文件
文件简单理解为外设硬盘上面保存数据的一种方式。
File类的使用
- java.io.File类:文件和文件目录路径的抽象表示形式,与平台无关/
- File 能新建、删除、重命名文件和目录,但 File 不能访问文件内容本身。如果需要访问文件内容本身,则需要使用输入/输出流。
- 想要在Java程序中表示一个真实存在的文件或目录,那么必须有一个File对象,但是Java程序中的一个File对象,可能没有一个真实存在的文件或目录。
- File对象可以作为参数传递给流的构造器
File类的常用构造器
- public File(String pathname)
以pathname为路径创建File对象,可以是绝对路径或者相对路径,如果
pathname是相对路径,则默认的当前路径在系统属性user.dir中存储
绝对路径: 是一个固定的路径,从盘符开始,E:\javacode\Java8\Test.java
相对路径: 是相对于某个位置开始.如当前路径为E:\javacode ,要描述上述路径( E:\javacode\Java8\Test.java ),只需输入: Java8\Test.java 。此时的路径是相对 E:\javacode 来说的。*
- public File(String parent,String child)
以parent为父路径, child为子路径创建File对象。
File 类的常用方法
- File类的获取功能
public String getAbsolutePath(): 获取绝对路径
public String getPath() : 获取路径
public String getName() : 获取名称
public String getParent(): 获取上层文件目录路径。 若无, 返回null
public long length() : 获取文件长度(即:字节数) 。 不能获取目录的长度。
public long lastModified() : 获取最后一次的修改时间, 毫秒值
public String[] list() : 获取指定目录下的所有文件或者文件目录的名称数组
public File[] listFiles() : 获取指定目录下的所有文件或者文件目录的File数组
-
File类的重命名功能
public boolean renameTo(File dest):把文件重命名为指定的文件路径 -
File类的判断功能
public boolean isDirectory(): 判断是否是文件目录
public boolean isFile() : 判断是否是文件
public boolean exists() : 判断是否存在
public boolean canRead() : 判断是否可读
public boolean canWrite() : 判断是否可写
public boolean isHidden() : 判断是否隐藏
- File类的创建功能
public boolean createNewFile() : 创建文件。 若文件存在, 则不创建, 返回false
public boolean mkdir() : 创建文件目录。 如果此文件目录存在, 就不创建了。如果此文件目录的上层目录不存在, 也不创建。
public boolean mkdirs() : 创建文件目录。 如果上层文件目录不存在, 一并创建
注意事项:如果你创建文件或者文件目录没有写盘符路径, 那么, 默认在项目路径下
- File类的删除功能
public boolean delete(): 删除文件或者文件夹
删除注意事项:
Java中的删除不走回收站。
要删除一个文件目录, 请注意该文件目录内不能包含文件或者文件目录
io流
io原理
- I/O是Input/Output的缩写,I/O技术是非常实用的技术, 用于处理设备之间的数据传输。 如读/写文件,网络通讯等。
- Java程序中,对于数据的输入/输出操作以“流(stream)” 的方式进行
- java.io包下提供了各种“流”类和接口,用以获取不同种类的数据,并通过标准的方法输入或输出数据。
**输入input:**读取外部数据(磁盘,光盘等存储设备的数据)到程序(内存)中。.
**输出output:**将程序(内存)数据输出到磁盘、光盘等存储设备中。
流的分类
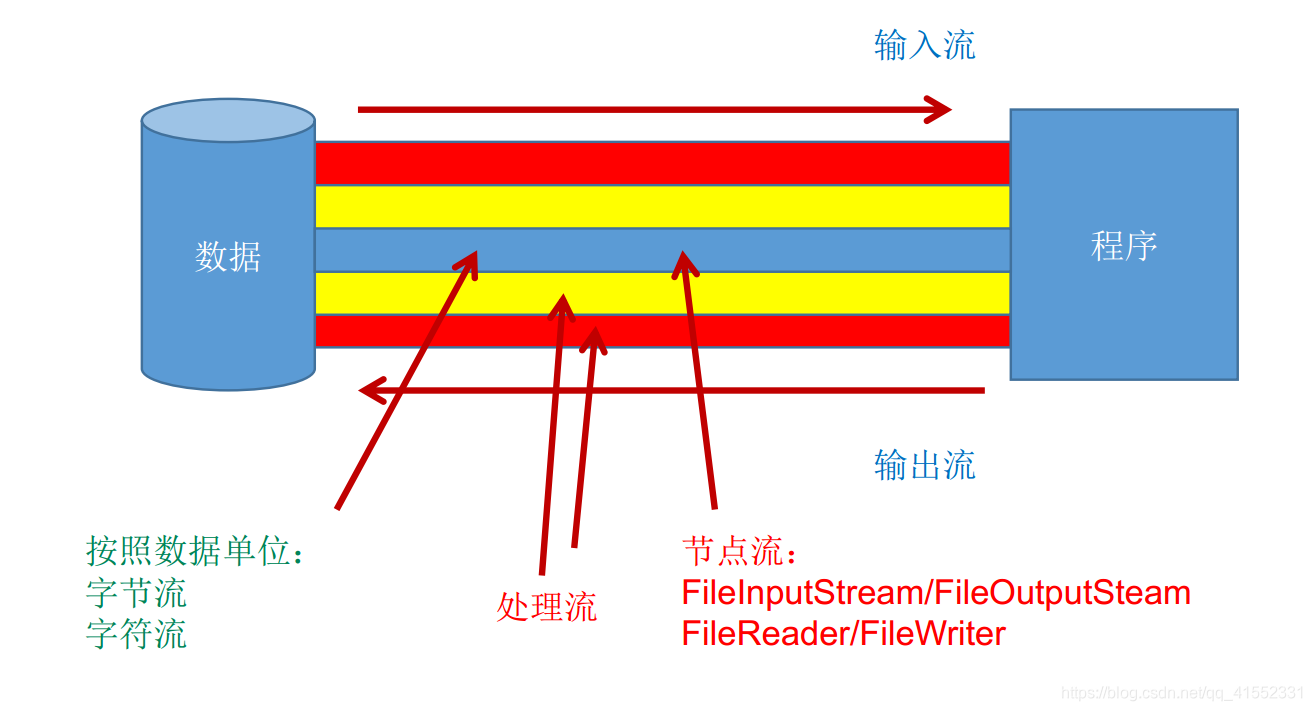
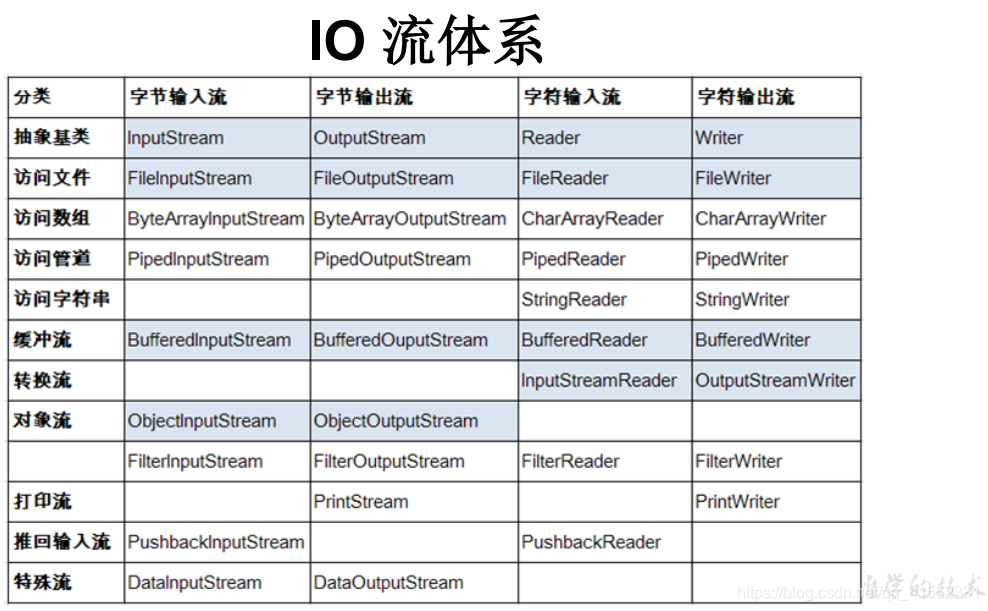
常用流
字节流
InputStream(字节输入流)
- int read()
从输入流中读取数据的下一个字节。 返回 0 到 255 范围内的 int 字节值。 如果因为已经到达流末尾而没有可用的字节, 则返回值 -1。 - int read(byte[] b)
从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。 如果因为已
经到达流末尾而没有可用的字节, 则返回值 -1。 否则以整数形式返回实际读取的字节数。 - int read(byte[] b, int off,int len)
将输入流中最多 len 个数据字节读入 byte 数组。 尝试读取 len 个字节, 但读取的字节也可能小于该值。 以整数形式返回实际读取的字节数。 如果因为流位于文件末尾而没有可用的字节, 则返回值 -1。 - public void close() throws IOException
关闭此输入流并释放与该流关联的所有系统资源。
OutputStream(字节输出流) - void write(int b)
将指定的字节写入此输出流。 write 的常规协定是:向输出流写入一个字节。 要写
入的字节是参数 b 的八个低位。 b 的 24 个高位将被忽略。 即写入0~255范围的。 - void write(byte[] b)
将 b.length 个字节从指定的 byte 数组写入此输出流。 write(b) 的常规协定是:应该与调用 write(b, 0, b.length) 的效果完全相同。 - void write(byte[] b,int off,int len)
将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。 - public void flush()throws IOException
刷新此输出流并强制写出所有缓冲的输出字节, 调用此方法指示应将这些字节立即写入它们预期的目标。 - public void close() throws IOException
关闭此输出流并释放与该流关联的所有系统资源
字符流
Reader
- int read()
读取单个字符。 作为整数读取的字符, 范围在 0 到 65535 之间(0x00-0xffff)(2个字节的Unicode码) , 如果已到达流的末尾, 则返回 -1 - int read(char[] cbuf)
将字符读入数组。 如果已到达流的末尾, 则返回 -1。 否则返回本次读取的字符数。 - int read(char[] cbuf,int off,int len)
将字符读入数组的某一部分。 存到数组cbuf中, 从off处开始存储, 最多读len个字符。 如果已到达流的末尾, 则返回 -1。 否则返回本次读取的字符数。 - public void close() throws IOException
关闭此输入流并释放与该流关联的所有系统资源
Writer - void write(int c)
写入单个字符。 要写入的字符包含在给定整数值的 16 个低位中, 16 高位被忽略。 即写入0 到 65535 之间的Unicode码。 - void write(char[] cbuf)
写入字符数组。 - void write(char[] cbuf,int off,int len)
写入字符数组的某一部分。 从off开始, 写入len个字符 - void write(String str)
写入字符串。 - void write(String str,int off,int len)
写入字符串的某一部分。 - void flush()
刷新该流的缓冲, 则立即将它们写入预期目标。 - public void close() throws IOException
关闭此输出流并释放与该流关联的所有系统资源
节点流(文件流)
读取文件
- 建立一个流对象,将已存在的一个文件加载进流。
FileReader fr = new FileReader(new File(“Test.txt”)); - 创建一个临时存放数据的数组。
char[] ch = new char[1024]; - 调用流对象的读取方法将流中的数据读入到数组中。
fr.read(ch); - 关闭资源。
fr.close();
FileReader fr = null;
try {
fr = new FileReader(new File("c:\\test.txt"));
char[] buf = new char[1024];
int len;
while ((len = fr.read(buf)) != -1) {
System.out.print(new String(buf, 0, len));
}
} catch (IOException e) {
System.out.println("read-Exception :" + e.getMessage());
} finally {
if (fr != null) {
try {
fr.close();
} catch (IOException e) {
System.out.println("close-Exception :" + e.getMessage());
}
}
}
写入文件
- 创建流对象,建立数据存放文件
FileWriter fw = new FileWriter(new File(“Test.txt”)); - 调用流对象的写入方法,将数据写入流
fw.write(“atguigu-songhongkang”); - 关闭流资源,并将流中的数据清空到文件中。
fw.close();
FileWriter fw = null;
try {
fw = new FileWriter(new File("Test.txt"));
fw.write("atguigu-songhongkang");
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fw != null)
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
注意:
- 定义文件路径时,注意:可以用“/”或者“\”。
- 在写入一个文件时,如果使用构造器FileOutputStream(file),则目录下有同名文件将被覆盖。
- 如果使用构造器FileOutputStream(file,true),则目录下的同名文件不会被覆盖,在文件内容末尾追加内容。
- 在读取文件时,必须保证该文件已存在,否则报异常。
- 字节流操作字节,比如: .mp3, .avi, .rmvb, mp4, .jpg, .doc, .ppt
- 字符流操作字符,只能操作普通文本文件。 最常见的文本文
件: .txt, .java, .c, .cpp 等语言的源代码。尤其注意.doc,excel,ppt这些不是文本文件
缓冲流(提高读写速度)
- 当读取数据时,数据按块读入缓冲区,其后的读操作则直接访问缓冲区
- 当使用BufferedInputStream读取字节文件时,BufferedInputStream会一次性从 文件中读取8192个(8Kb), 存在缓冲区中, 直到缓冲区装满了, 才重新从文件中读取下一个8192个字节数组。
- 向流中写入字节时, 不会直接写到文件, 先写到缓冲区中直到缓冲区写满,BufferedOutputStream才会把缓冲区中的数据一次性写到文件里。使用方法 flush()可以强制将缓冲区的内容全部写入输出流
- 关闭流的顺序和打开流的顺序相反。只要关闭最外层流即可, 关闭最外层流也 会相应关闭内层节点流
- flush()方法的使用:手动将buffer中内容写入文件 如果是带缓冲区的流对象的close()方法, 不但会关闭流, 还会在关闭流之前刷 新缓冲区, 关闭后不能再写出
- 缓冲流包裹着字节字符流使用
public void copyFile() throws Exception {
FileInputStream fis = null;
BufferedInputStream bis = null;
FileOutputStream fos = null;
BufferedOutputStream bos = null;
try {
//作业:复制本地文件到另一个地方
fis = new FileInputStream(
new File("D:\\javacode\\ideaCode\\javaWeb\\1572019978997.png"));
bis = new BufferedInputStream(fis);
fos = new FileOutputStream(
new File("D:\\javacode\\ideaCode\\javaWeb\\1572019978998.png"));
bos = new BufferedOutputStream(fos);
byte[] bytes = new byte[1024 * 8];
int len;
while ((len = fis.read(bytes)) != -1) {
bos.write(bytes);
bos.flush();
}
} finally {// IO流的操作完成之后,一定要释放资源,顺序是根据依赖关系B依赖A,反向释放(先释放B)
if (bis != null)
bis.close();
if (fis != null)
fis.close();
if (bos != null)
bos.close();
if (fos != null)
fos.close();
}
}
序列化与反序列化
序列化:把对象转化为字节序列的过程
反序列化:把字节恢复成对象的过程。
什么时候需要序列化?
1、把内存中的对象状态保存到一个文件中或者数据库中时候;
2、 用套接字在网络上传送对象的时候
实现序列化本身是跟语言无关的
如何实现对象序列化?
实现一个Serializable接口
import java.io.Serializable
class Person implements Serializable{
//private static final long serialVersionUID = 1L;
private String name;
private int age;
private String sex;
//transient修饰的变量,不能被序列化
transient private int stuId;
//static修饰的变量,不能被序列化
private static int count = 99;
public String getName() {
return name;
}
public int getAge() {
return age;
}
public String getSex() {
return sex;
}
public int getStuId() {
return stuId;
}
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public void setSex(String sex) {
this.sex = sex;
}
public void setStuId(int stuId) {
this.stuId = stuId;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", sex='" + sex + '\'' +
", stuId=" + stuId +
", count=" + count +
'}';
}
}
public class TestDemo3 {
public static void main(String[] args) throws Exception {
serializePerson();
Person person = deserializePerson();
System.out.println(person.toString());
}
/**
* 序列化
*/
private static void serializePerson() throws IOException {
Person person = new Person();
person.setName("bit");
person.setAge(10);
person.setSex("男");
person.setStuId(100);
// ObjectOutputStream 对象输出流,将 person 对象存储到E盘的
// person.txt 文件中,完成对 person 对象的序列化操作
ObjectOutputStream oos = new ObjectOutputStream
(new FileOutputStream(new File("e:/person.txt")));
oos.writeObject(person);
System.out.println("person 对象序列化成功!");
oos.close();
}
/**
* 反序列化
*/
private static Person deserializePerson() throws Exception {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new
File("e:/person.txt")));
Person person = (Person) ois.readObject();
System.out.println("person 对象反序列化成功!");
return person;
}
}
//ObjectOutputStream 代表对象输出流: 它的 writeObject(Object obj) 方法可对参数指定的 obj
对象进行序列化,把得到的字节序列写到一个目标输出流中。 ObjectInputStream 代表对象输入流:
它的 readObject() 方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回
//结果
person 对象序列化成功!
person 对象反序列化成功!
Person{name='bit', age=10, sex='男', stuId=0, count=99}
注意:
transient修饰属性不能被序列化
静态变量的值不能被序列化
关于序列化版本号serialVersionUID
如果类没有显示定义这个静态常量,它的值是Java运行时环境根据类的内部细节自动生成的。 若类的实例变量做了修改serialVersionUID 可能发生变化。 故建议,显式声明
简单来说, Java的序列化机制是通过在运行时判断类的serialVersionUID来验 证版本一致性的。在进行反序列化时, JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
(InvalidCastException)
private static final long serialVersionUID;