项目地址
爬取京东苏宁商品信息(手机 笔记本电脑) 以及商品的评论 然后继承到web上,实现了价格评价的比较 并且对每件商品评论进行了情感分析,绘制了评论的词云
https://github.com/ccclll777/JDSNCompare
如果觉得有用,请点个star
项目地址:http://39.105.44.114:38888/comparePrice/index.html
京东爬虫
在这里,我爬取了京东的搜索界面,通过关键字“手机”,“和笔记本电脑”,搜索到的信息,目标站点的url为
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&wq=%E6%89%8B%E6%9C%BA&pvid=15b7aa9229e8404c8c157db86b8563d8
https://search.jd.com/Searchkeyword=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&enc=utf-8&wq=bi%20ji%20ben&pvid=65b38d2ff9634a078f7d7d3825a39b5d
【1】京东网站界面分析
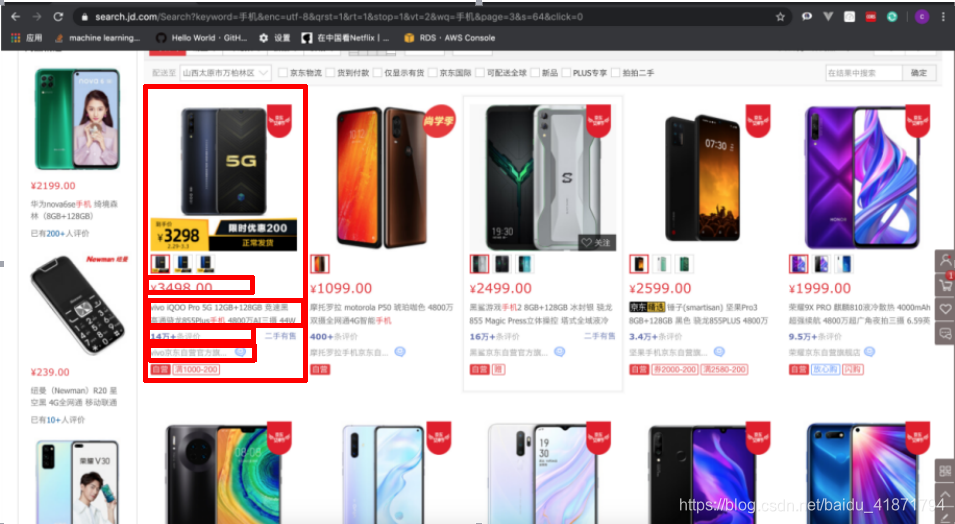
首先,我需要现在主界面中,获取到商品id,商品的详细界面的url,以及商品的价格,即。
然后,根据获取到的商品详细界面的url,进入每个商品的商品详情界面。商品详情的url中,数字部分就是这个商品的id,对于不同型号的商品都会有不同的id,进入商品详情界面后,就可以获取商品的标题,品牌,型号,店名等信息。

最后,在商品详情界面爬取商品的评论,在这里可以获取到评论的内容,评论的商品的标签,评论时间以及回复数量等
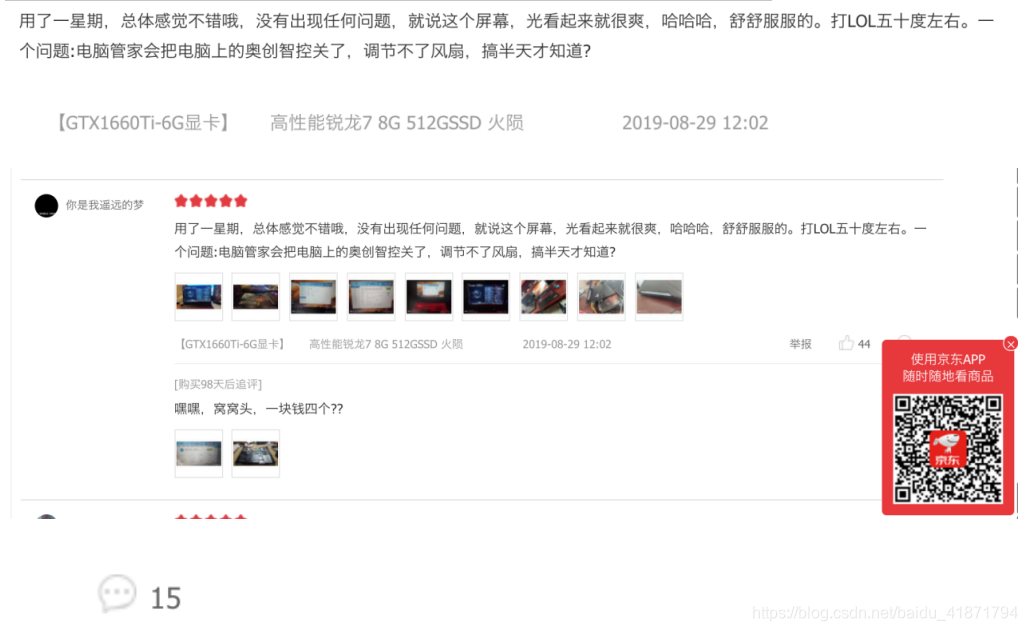
经过总结之后,发现两者的共同点,可以根据任意参数搜索信息。
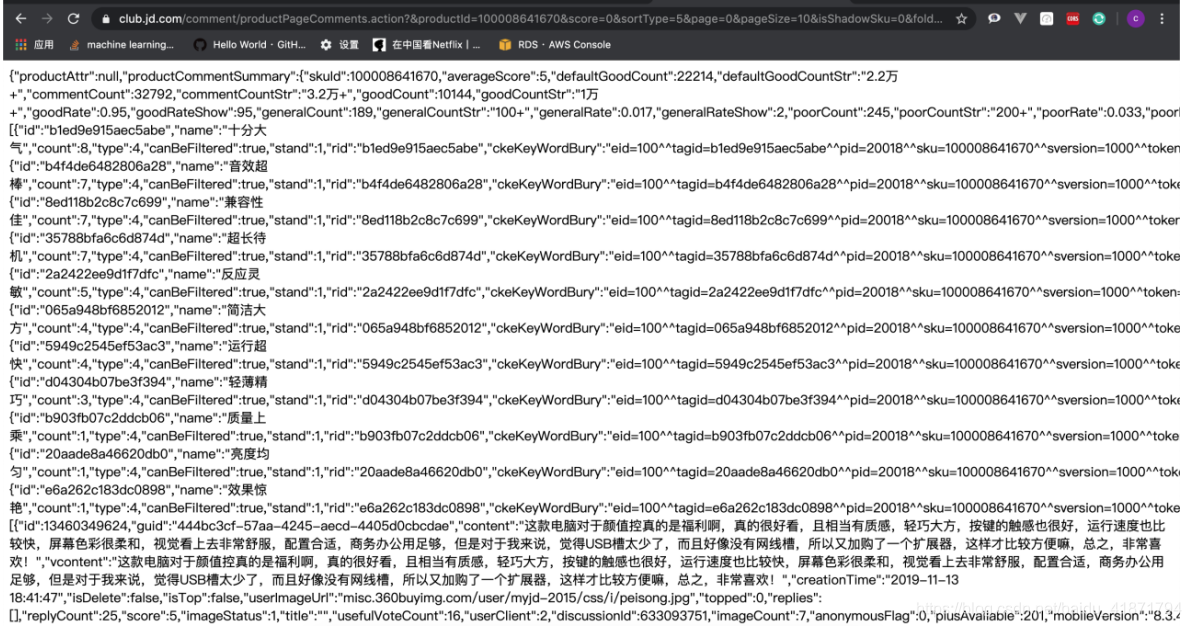
商品详情界面的商品评论,通过搜索评论的内容,发现的获取评论信息的接口,返回的数据是json格式的
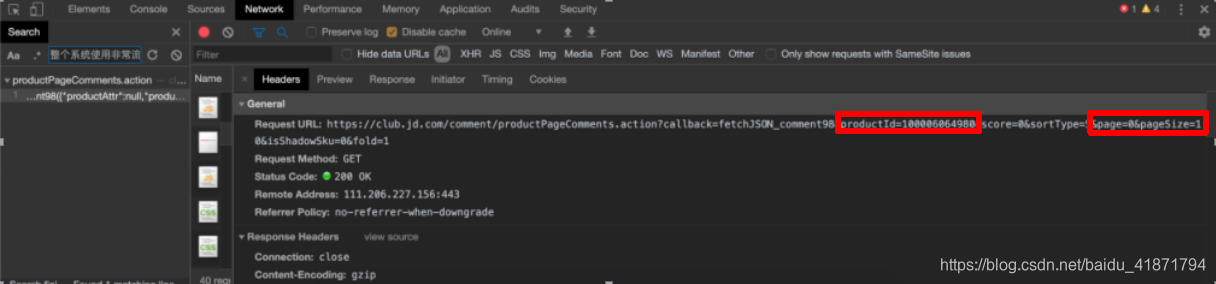
https://club.jd.com/comment/productPageComments.action?productId={}&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&fold=1
只需更改参数productId(商品的id),以及page(爬取第几页评论),这两个参数即可
【2】操作过程
(1)京东搜索主界面内容的网页源代码分析
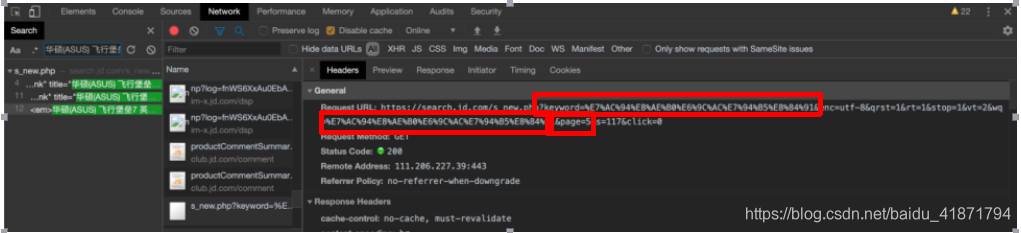
通过对翻页的url进行分析,得到了共同的url
https://search.jd.com/Search?keyword={}&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq={}&page={}&s=51&click=0
其中{}中可以替换成搜索的关键字以及页数(京东搜索出的内容会展示100页)
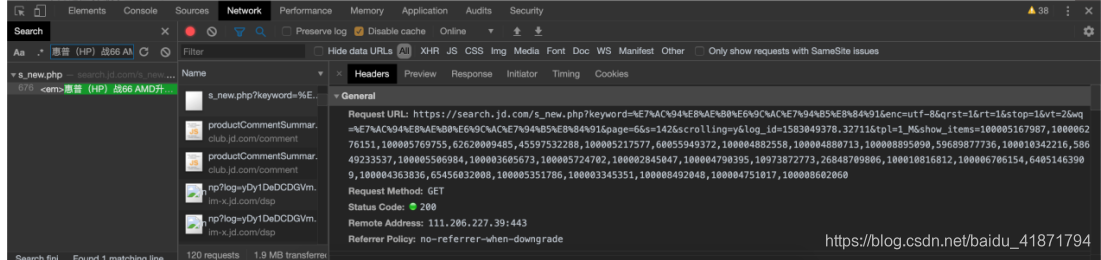
通过向下翻页,发现页面下面的内容是异步加载出来的
需要在爬取页面前半部分时,构造后半部分的url,从而爬取网页的后半部分

https://search.jd.com/s_new.php?keyword=%s&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%s&page=%d&s=76&scrolling=y&log_id=1582951658.11616&tpl=1_M&show_items=%s
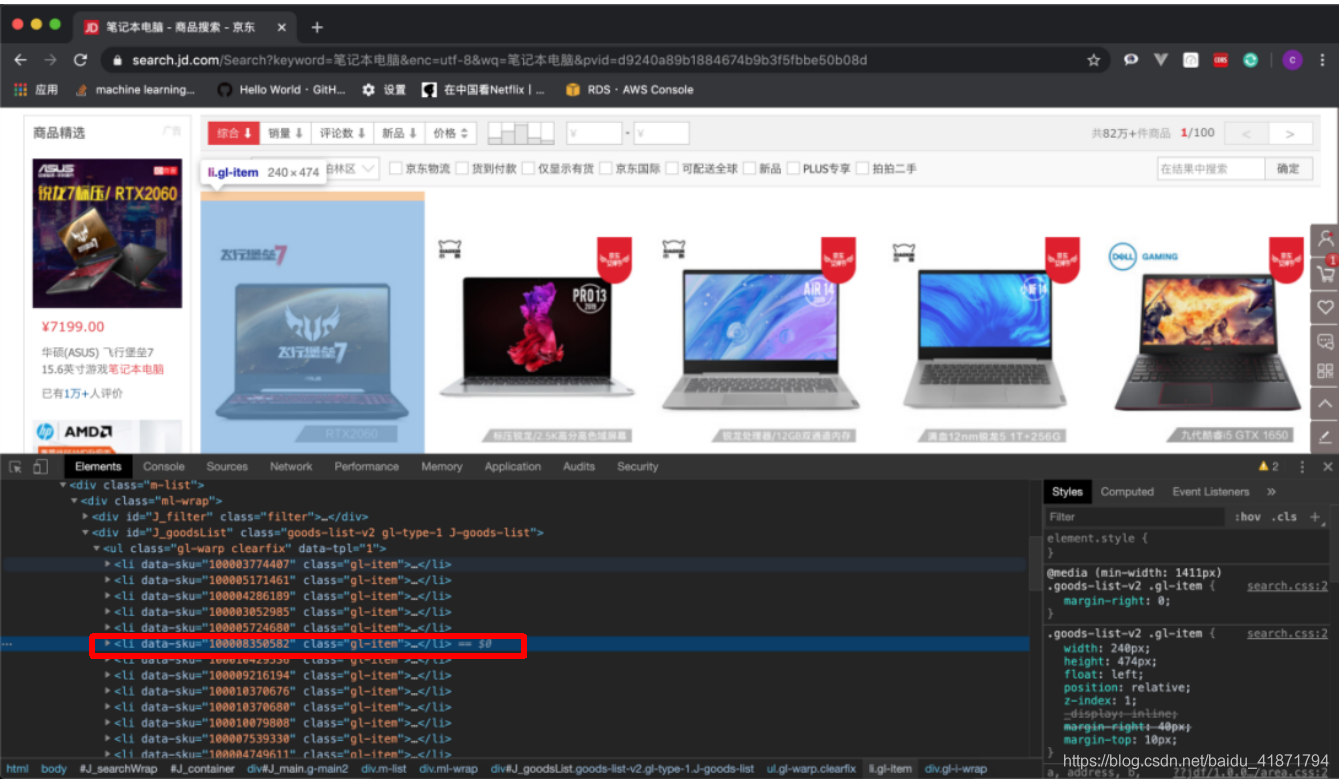
网页中的每一个商品都在一个li标签之中。我们在li标签之中提取我们需要的内容。
- 商品详情的url:
根据dom树的位置,通过class选择器层层选择
.gl-warp .gl-item .gl-i-wrap .p-name a::attr(href)

- 商品价格
根据dom树的位置,通过class选择器层层选择,
.gl-warp .gl-item .gl-i-wrap .p-price strong i::text
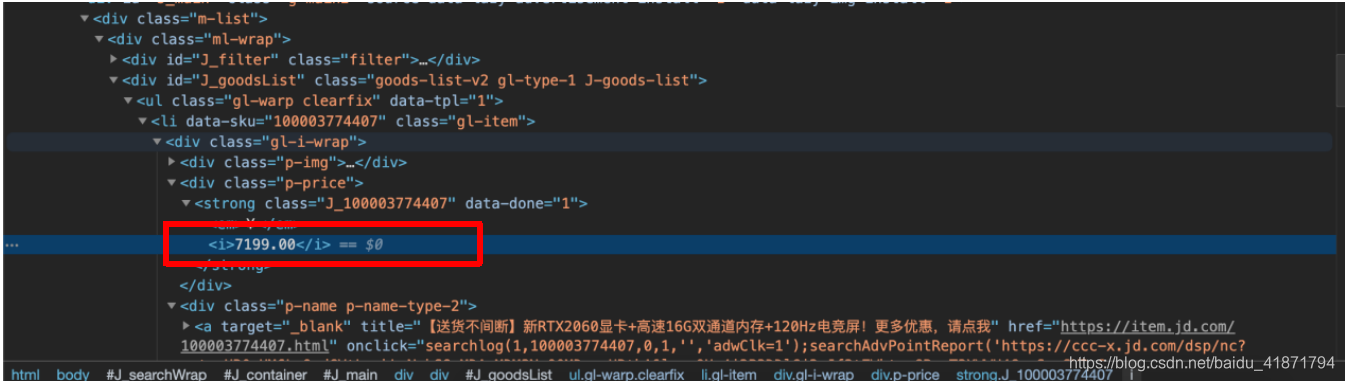
- 商品的id 即data_sku中的信息
根据dom树的位置,通过class选择器层层选择
.gl-warp .gl-item::attr(data-sku)

(2)商品的详情界面
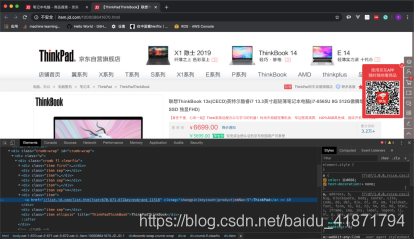
- 商品的品牌
.inner .border .head a::text
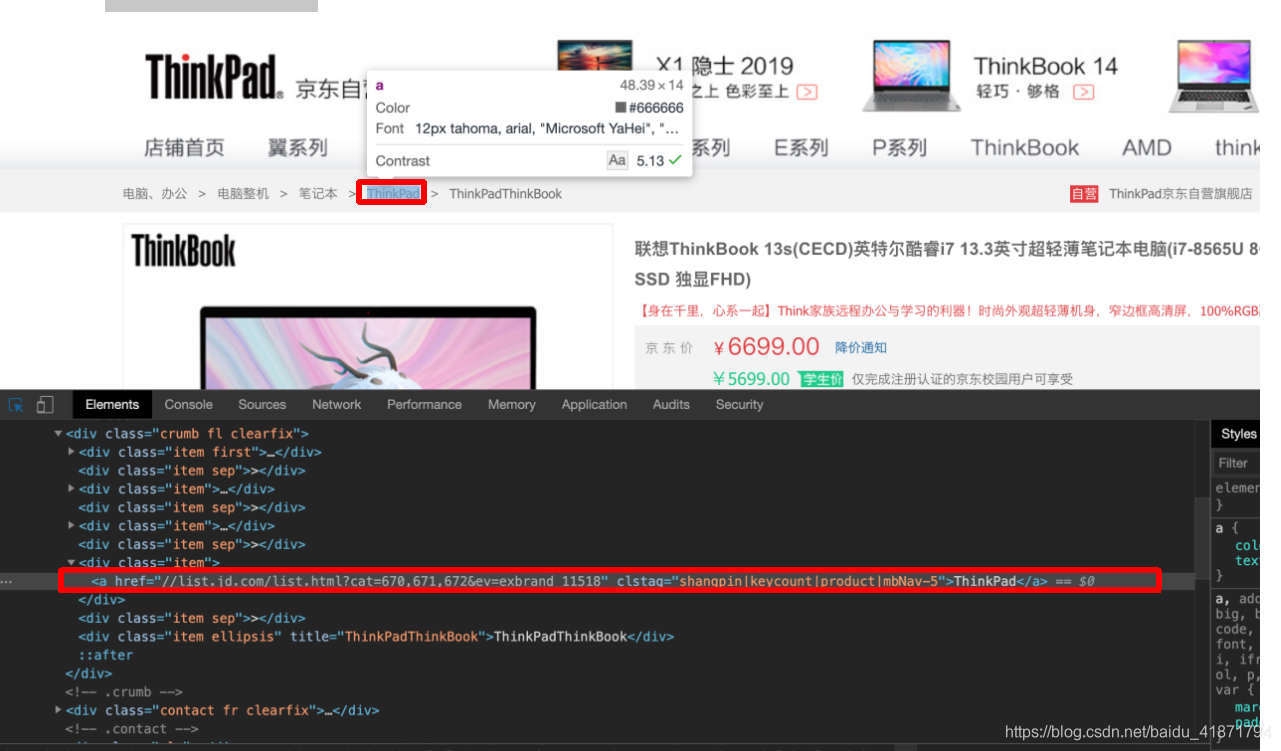
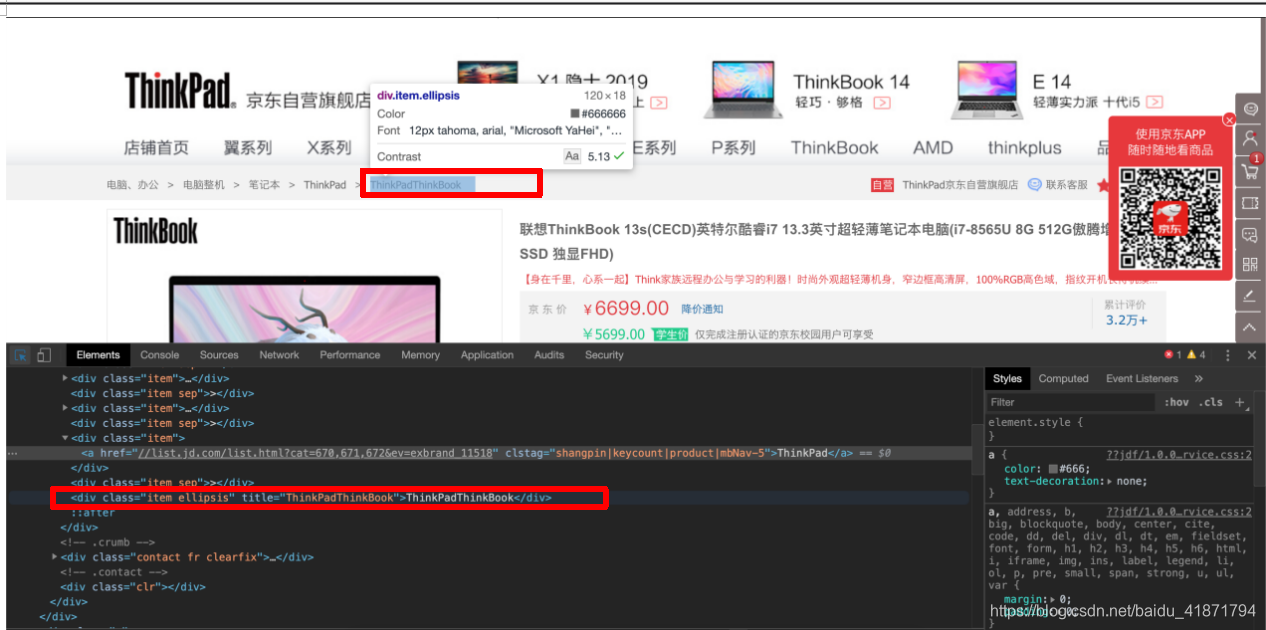
- 商品的型号
.item .ellipsis::text
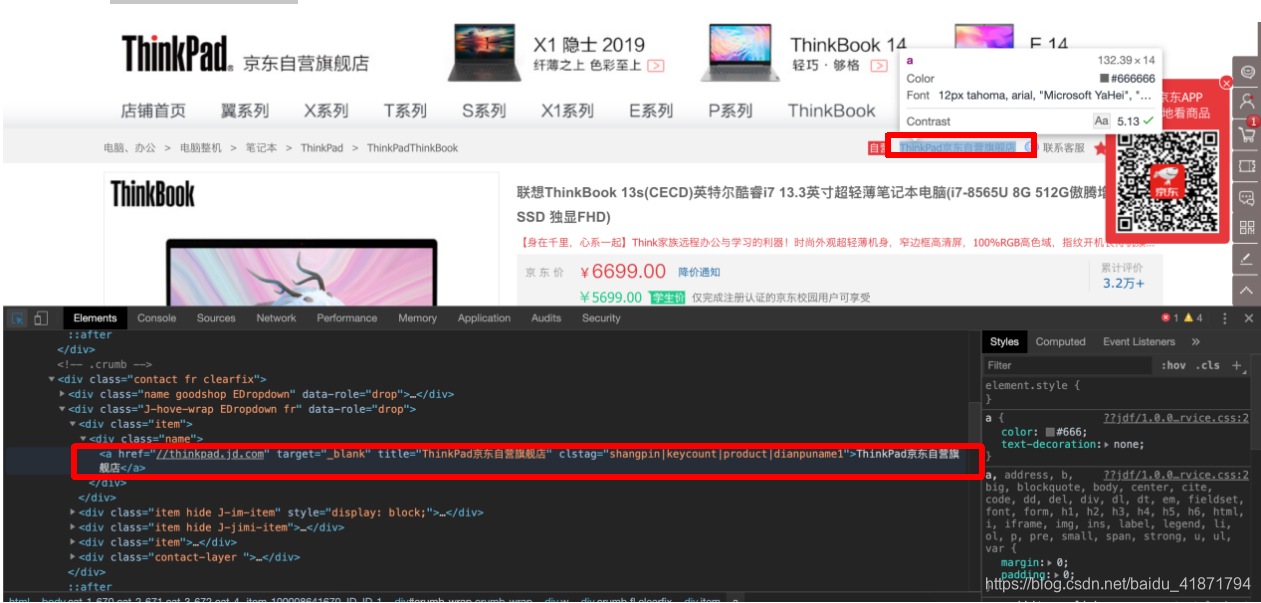
- 店铺名称
.J-hove-wrap .EDropdown .fr .item .name a::text
- 商品的标题
根据dom树的位置,通过class选择器层层选择,
.w .product-intro .itemInfo-wrap #spec-img::attr(alt)
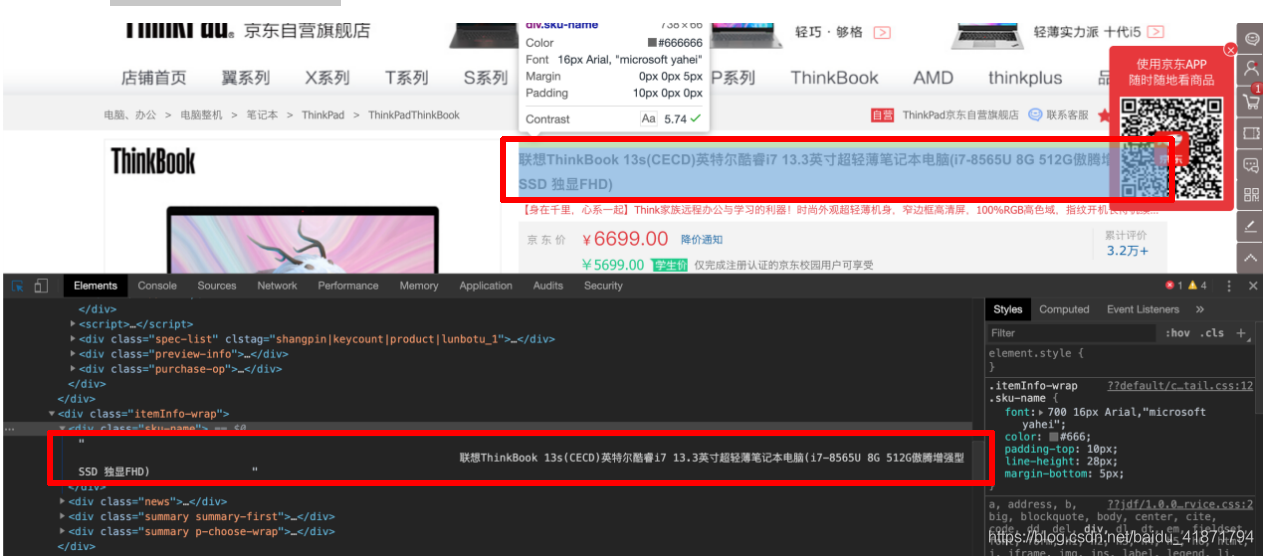
(3)商品评价
根据对商品评论在console中进行搜索,发现的获取评论的接口
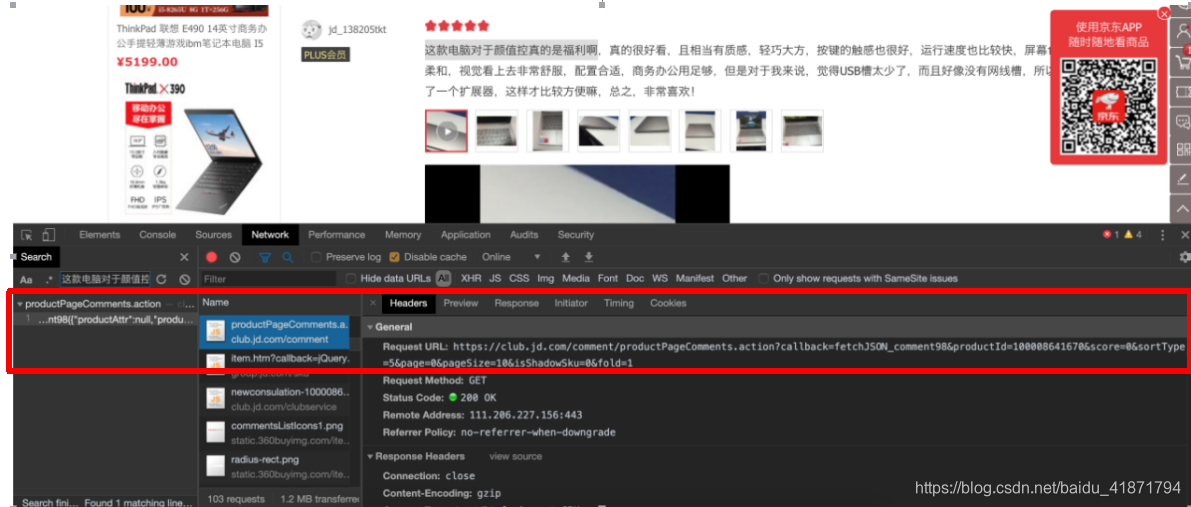
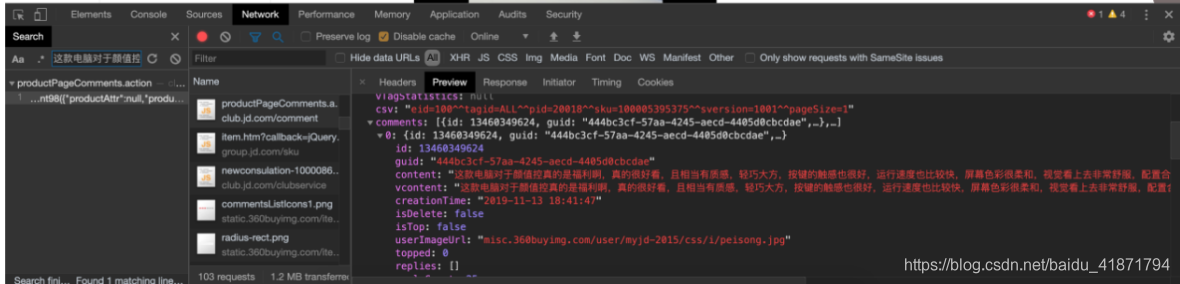
里面有相应的评论信息。通过对翻页的分析,获取到爬取评论的规律。
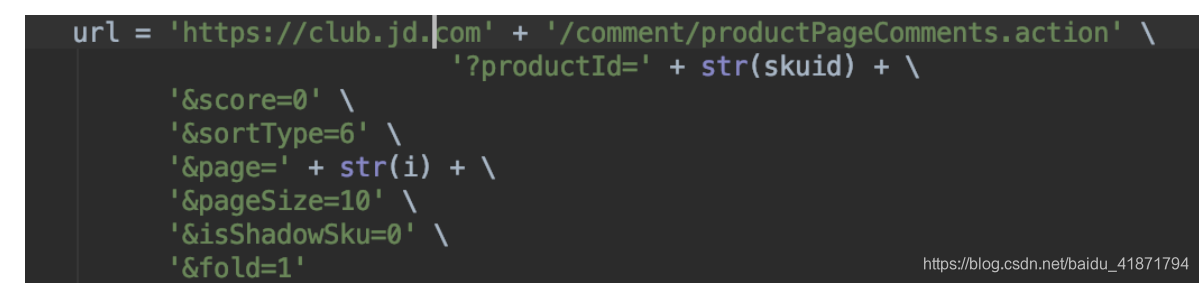
skuid为商品的id page为页数
【3】数据库表的设计
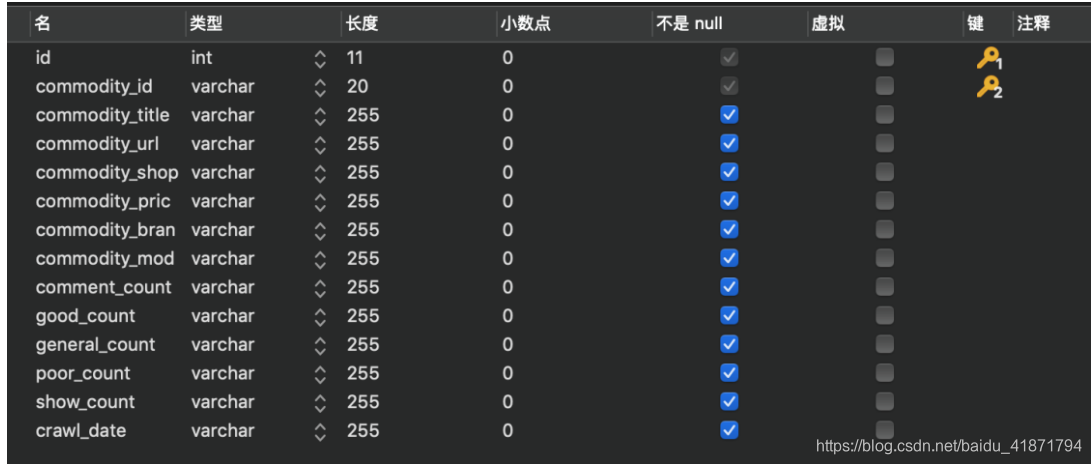
商品id (commodity_id)
商品标题 (commodity_title)
商品详情页网址 (commodity_url)
商品的网店名称 (commodity_shop_name)
商品价格 (commodity_price)
商品牌子 (commodity_brand)
商品型号 (commodity_model)
商品评论数量 (comment_count)
商品好评数 (good_count)
商品中评数 (general_count)
商品差评数 (poor_count)
商品展示数 (show_count)
爬取时间(crawl_date)
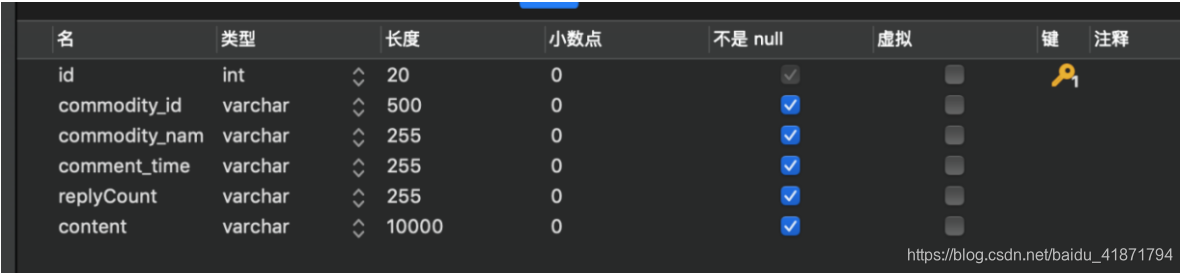
商品id (commodity_id)
商品标签 (commodity_name)
评论时间 (commodity_time)
评论的评论数 (replyCount)
评论内容(content)
【4】代码实现
项目代码在github ,如果觉得有用,请点个star
https://github.com/ccclll777/JDSNCompare
(1)扫码登陆京东
通过请求接口,将后端返回的base64编码的图片解析出来,扫描之后成功登陆,会把cookie保存在本地,如果下次登陆时,cookie没有失效,则不用再次扫码登录
import json
import os
import pickle
import re
import random
import time
import requests
from bs4 import BeautifulSoup
class Assistant(object):
def __init__(self):
self.username = ''
self.nick_name = ''
self.is_login = False
self.User_Agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
self.headers = {
'User-Agent': self.User_Agent
}
self.sess = requests.session()
self.item_cat = dict()
self.item_vender_ids = dict() # 记录商家id
self.item_states = dict() # 记录商品上架状态
self.risk_control = ''
try:
self.load_cookies()
except Exception:
pass
#保存coookie
def load_cookies(self):
cookies_file = ''
for name in os.listdir('./cookies'):
if name.endswith('.cookies'):
cookies_file = './cookies/{0}'.format(name)
break
with open(cookies_file, 'rb') as f:
local_cookies = pickle.load(f)
self.sess.cookies.update(local_cookies)
self.is_login = self._validate_cookies()
#验证cookie是否有效
def _validate_cookies(self):
url = 'https://order.jd.com/center/list.action'
payload = {
'rid': str(int(time.time() * 1000)),
}
try:
resp = self.sess.get(url=url, params=payload, allow_redirects=False)
if resp.status_code == requests.codes.OK:
return True
except Exception as e:
print(e)
self.sess = requests.session()
return False
def _save_cookies(self):
cookies_file = './cookies/{0}.cookies'.format(self.nick_name)
directory = os.path.dirname(cookies_file)
if not os.path.exists(directory):
os.makedirs(directory)
with open(cookies_file, 'wb') as f:
pickle.dump(self.sess.cookies, f)
#获取登陆界面
def _get_login_page(self):
url = "https://passport.jd.com/new/login.aspx"
page = self.sess.get(url, headers=self.headers)
return page
# 获取二维码扫描登陆
def _get_QRcode(self):
url = 'https://qr.m.jd.com/show'
payload = {
'appid': 133,
'size': 147,
't': str(int(time.time() * 1000)),
}
headers = {
'User-Agent': self.User_Agent,
'Referer': 'https://passport.jd.com/new/login.aspx',
}
resp = self.sess.get(url=url, headers=headers, params=payload)
if resp.status_code !=requests.codes.OK:
print('获取二维码失败')
return False
QRCode_file = 'QRcode.png'
#保存二维码图片
with open(QRCode_file, 'wb') as f:
for chunk in resp.iter_content(chunk_size=1024):
f.write(chunk)
print('二维码获取成功,请打开京东APP扫描')
if os.name == "nt":
os.system('start ' + QRCode_file) # for Windows
else:
if os.uname()[0] == "Linux":
os.system("eog " + QRCode_file) # for Linux
else:
os.system("open " + QRCode_file) # for Mac
return True
def login_by_QRcode(self):
"""二维码登陆
"""
if self.is_login:
print('登录成功')
return True
self._get_login_page()
# download QR code
if not self._get_QRcode():
print('登录失败')
return False
# get QR code ticket
ticket = None
retry_times = 90
for _ in range(retry_times):
ticket = self._get_QRcode_ticket()
if ticket:
break
time.sleep(2)
else:
print('二维码扫描出错')
return False
# validate QR code ticket
if not self._validate_QRcode_ticket(ticket):
print('二维码登录失败')
return False
else:
print('二维码登录成功')
self.nick_name = self.get_user_info()
self._save_cookies()
self.is_login = True
return True
def get_user_info(self):
"""获取用户信息
:return: 用户名
"""
url = 'https://passport.jd.com/user/petName/getUserInfoForMiniJd.action'
payload = {
'callback': 'jQuery{}'.format(random.randint(1000000, 9999999)),
'_': str(int(time.time() * 1000)),
}
headers = {
'User-Agent': self.User_Agent,
'Referer': 'https://order.jd.com/center/list.action',
}
try:
resp = self.sess.get(url=url, params=payload, headers=headers)
begin = resp.text.find('{')
end = resp.text.rfind('}') + 1
resp_json = json.loads(resp.text[begin:end])
# many user info are included in response, now return nick name in it
# jQuery2381773({"imgUrl":"//storage.360buyimg.com/i.imageUpload/xxx.jpg","lastLoginTime":"","nickName":"xxx","plusStatus":"0","realName":"xxx","userLevel":x,"userScoreVO":{"accountScore":xx,"activityScore":xx,"consumptionScore":xxxxx,"default":false,"financeScore":xxx,"pin":"xxx","riskScore":x,"totalScore":xxxxx}})
return resp_json.get('nickName') or 'jd'
except Exception:
return 'jd'
def _validate_QRcode_ticket(self, ticket):
url = 'https://passport.jd.com/uc/qrCodeTicketValidation'
headers = {
'User-Agent': self.User_Agent,
'Referer': 'https://passport.jd.com/uc/login?ltype=logout',
}
resp = self.sess.get(url=url, headers=headers, params={'t': ticket})
if resp.status_code !=requests.codes.OK:
return False
resp_json = json.loads(resp.text)
if resp_json['returnCode'] == 0:
return True
else:
print(resp_json)
return False
def _get_QRcode_ticket(self):
url = 'https://qr.m.jd.com/check'
payload = {
'appid': '133',
'callback': 'jQuery{}'.format(random.randint(1000000, 9999999)),
'token': self.sess.cookies.get('wlfstk_smdl'),
'_': str(int(time.time() * 1000)),
}
headers = {
'User-Agent': self.User_Agent,
'Referer': 'https://passport.jd.com/new/login.aspx',
}
resp = self.sess.get(url=url, headers=headers, params=payload)
if resp.status_code !=requests.codes.OK:
print('获取二维码扫描结果出错')
return False
begin = resp.text.find('{')
end = resp.text.rfind('}') + 1
resp_json = json.loads(resp.text[begin:end])
if resp_json['code'] != 200:
print('Code: {0}, Message: {1}'.format(resp_json['code'], resp_json['msg']))
return None
else:
print('已完成手机客户端确认')
return resp_json['ticket']
(2)京东商品信息的代码,使用scrapy框架,只贴出有关爬虫逻辑的重要部分
首先请求search界面,通过之前的分析,加载每一页数据(中间需要向下拖动,请求另一半数据),爬取到search界面的每条数据后,都会转到详情界面,爬取物品的详情,然后将数据存入数据库(具体的代码中都有注释)
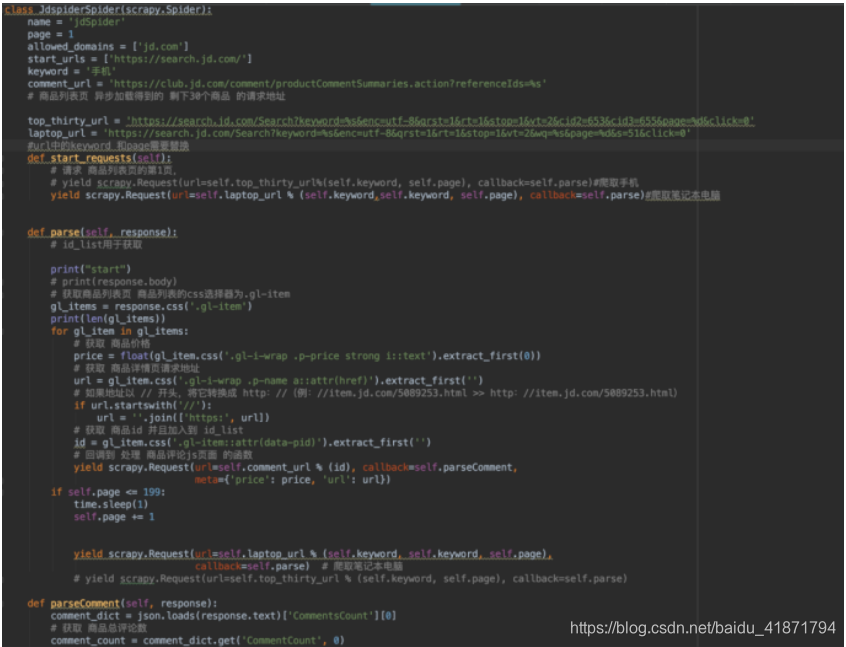
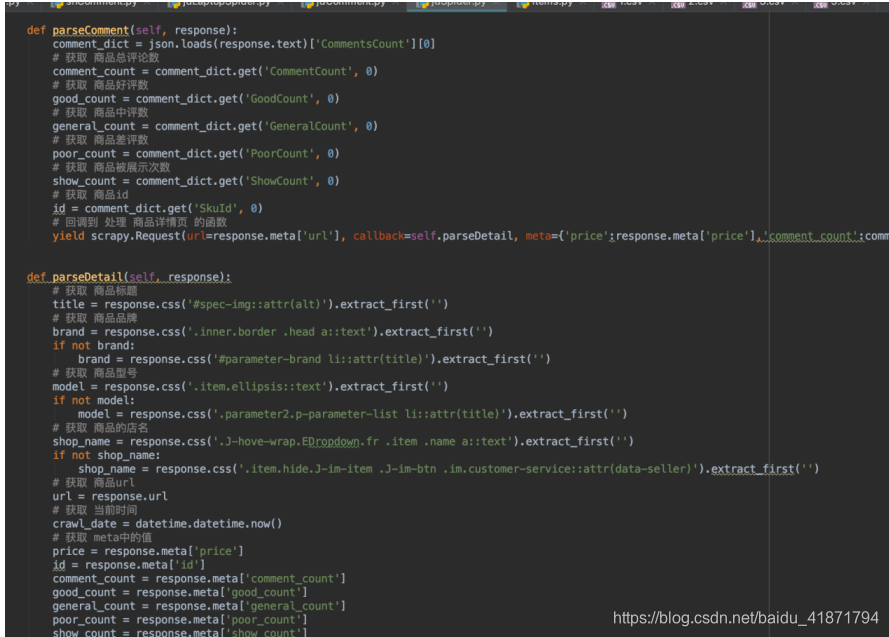
(3)京东获取评论代码
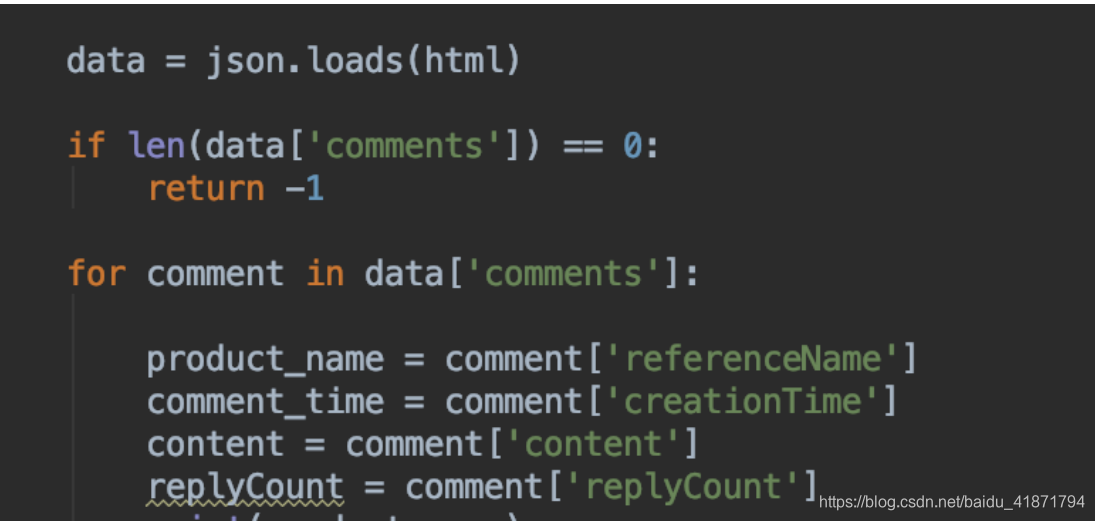
获取评论时,只要得到商品的id,就能通过接口获取商品对应的评论,返回的数据时json格式,使用json库进行解析即可
import urllib.request
import json
import time
import random
import pymysql as pymysql
from random import choice
import sys
'''
爬取京东的评论 由于可以找到对应的接口 所以没有使用scrapy
解析json即可
'''
DEFAULT_REQUEST_HEADERS = {
'Accept': ' */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',
'cookie':'__jdu=15806122687801051175906; shshshfpa=d7d62fe8-302d-0eef-66ba-ff2b34d256a6-1580613199; shshshfpb=ptpp5JVNIFs%2FOKJmShsleow%3D%3D; pinId=0j9tP6mmaSFNEgXcNiCsZrV9-x-f3wj7; pin=jd_45a3a96f0dce8; unick=jd_45a3a96f0dce8; _tp=1S2A2FEea%2BptNQ%2BXOUNIjyaAn1cq2%2BrRzUshb6mUkKg%3D; _pst=jd_45a3a96f0dce8; user-key=fee67ccf-58e4-4adb-b458-3ee0ba2b47d3; ipLocation=%u5c71%u897f; unpl=V2_ZzNtbUdQQhQiChQALxkMUmILFVVLUEEVdlwRXHkfWVIzChtZclRCFnQUR1dnGlsUZwsZX0RcQRxFCEVkeBlUDWAAFVREZ3Mldgh2VUsZWAxmBBJeQVBKE3wJRlV%2fGVwDYwsTWnJnRBV8OHYGJkEOXyVHTW1KX0YQcThHZHsRXAJnChBYRlZzXhsJC1R%2fEF0CZwARWktRShR1CUJUex9YDWYEIlxyVA%3d%3d; __jdv=76161171|www.taobap.com|t_219962687_|tuiguang|4600f3cee1af496986312ef9374fe885|1582717059275; areaId=6; ipLoc-djd=6-303-36783-0; PCSYCityID=CN_140000_140100_140109; TrackID=1APbutj1lK16uXpxdIo35ZLUlCVHS37YbWy4ACoGrq_YbCTbZ_OHR55MDDThDq3N0RBQz6SIJ6L-T_UfLk-ZlCyfeDrwfoErqSMFSrY61r5inA8_5X2CIktUW9ynUz0RJ; cn=1; 3AB9D23F7A4B3C9B=HF4B3KEULPAGQU5ZK3A7U6ZLTA3GWQ2HEMSSHRFEKDYSXUGJSTH7DF7POYHZSCHJ465QTNAB4GWQAGAXPBDOQVHKUM; shshshfp=d5fee5b234e13324bd45d9b023635ae4; __jda=122270672.15806122687801051175906.1580612269.1582972811.1582975798.28; __jdc=122270672; shshshsID=9ebd788cef6e998f5d7fb9ae641dad31_2_1582975799167; SL_GWPT_Show_Hide_tmp=1; SL_wptGlobTipTmp=1; __jdb=122270672.2.15806122687801051175906|28.1582975798',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Host': 'club.jd.com',
'Pragma':' no-cache',
'upgrade-insecure-requests': '1',
'Sec-Fetch-Dest': 'script',
'Sec-Fetch-Mode': 'no-cors',
'Sec-Fetch-Site': 'same-site'
}
'''
'''
fw = open('result3.csv','w')
def crawlProductComment(url, skuid):
# 读取原始数据(注意选择gbk编码方式)
try:
html = urllib.request.urlopen(url=url).read().decode('gbk', 'ignore')
except Exception:
return -1
#解析json
data = json.loads(html)
if len(data['comments']) == 0:
return -1
for comment in data['comments']:
product_name = comment['referenceName']
comment_time = comment['creationTime']
content = comment['content']
replyCount = comment['replyCount']
print(product_name)
print(comment_time)
print(content)
fw.write('{},{},{},{}'.format(product_name.replace('\n',''),comment_time.replace('\n',''),content.replace('\n',''),replyCount))
fw.write('\n')
# 数据库操作
# 获取数据库链接
connection = pymysql.connect(host="127.0.0.1", user="root", passwd="SSwns304275", db="JDP", port=3306, charset="utf8")
try:
# 获取会话指针
with connection.cursor() as cursor:
# 创建sql语句
sql = "insert into comment(commodity_id,commodity_name,comment_time,replyCount,content) values (%s,%s,%s,%s,%s)"
# 执行sql语句
cursor.execute(sql, (skuid, product_name, comment_time,replyCount, content))
# 提交数据库
connection.commit()
finally:
connection.close()
return 1
def crawl_main(skuid):
i = 0
retry_times = 6
while True:
url = 'https://club.jd.com' + '/comment/productPageComments.action' \
'?productId=' + str(skuid) + \
'&score=0' \
'&sortType=6' \
'&page=' + str(i) + \
'&pageSize=10' \
'&isShadowSku=0' \
'&fold=1'
i = i + 1
print(url)
if crawlProductComment(url, skuid) == -1:
retry_times = retry_times - 1
if retry_times < 0:
break
i = i - 1
randint = random.randint(3, 10)
while randint > 0:
print("\r", "{}th retrying in {} seconds...".format(6 - retry_times, randint), end='', flush=True)
randint -= 1
else:
retry_times = 2
print("\r", "{}th page has been saved.".format(i), end='', flush=True)
if i == 20:
break
fr = open("jdUrl.csv", "r")
id_list = fr.readlines()
list = id_list[0].split(',');
for i in list:
crawl_main(i)
# print(i)
(4)京东获取图片的代码
获取图片需要到商品的详情界面,找到对应的图片标签重的图片链接即可,然后使用urllib将图片资源下载到本地(由于刚开始没有爬图片,图片时在做网站时需要,才爬的图片,所以没有写在一起)
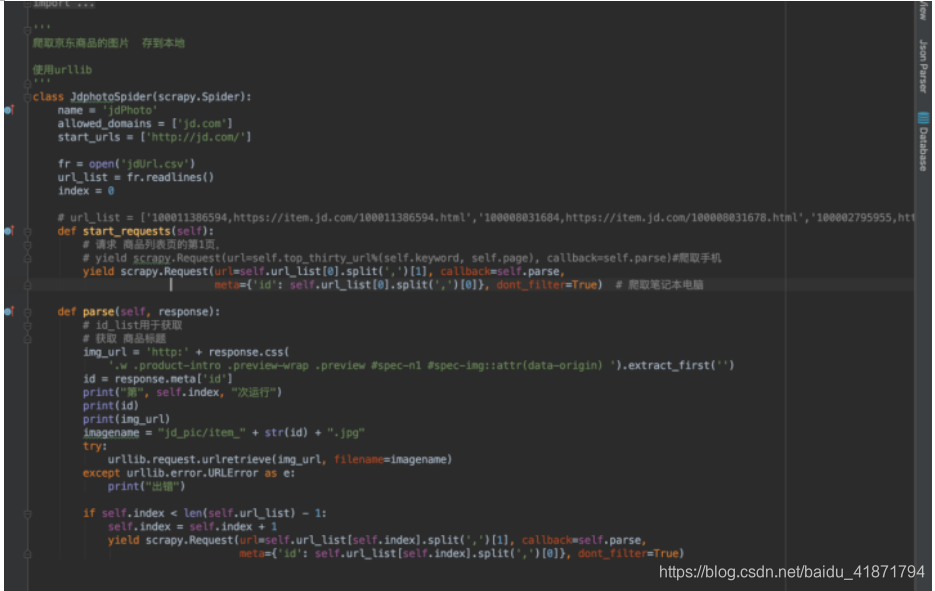
苏宁爬虫
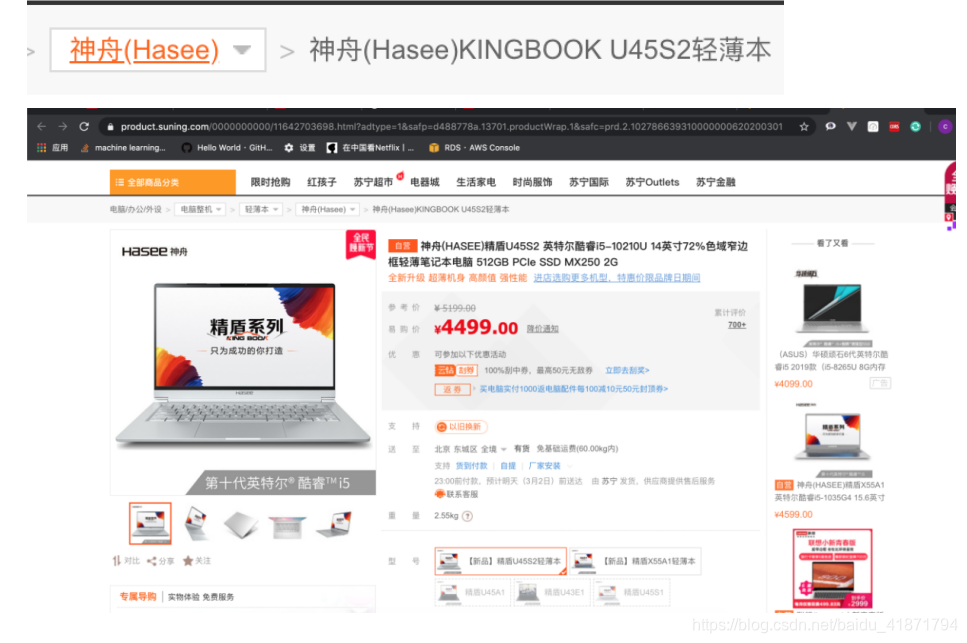
爬取苏宁易购的搜索界面,同样搜索关键词为“手机”和“笔记本电脑”的信息。目标站点的URL为:
https://search.suning.com/emall/searchV1Product.do?keyword={}&ci=0&pg=01&cp={}&il=0&st=0&iy=0&adNumber=16&isNoResult=0&n=1&sesab=ACAABAABCAAA&id=IDENTIFYING&cc=010&paging={}&sub=0&jzq=112901
【1】苏宁网站记录分析
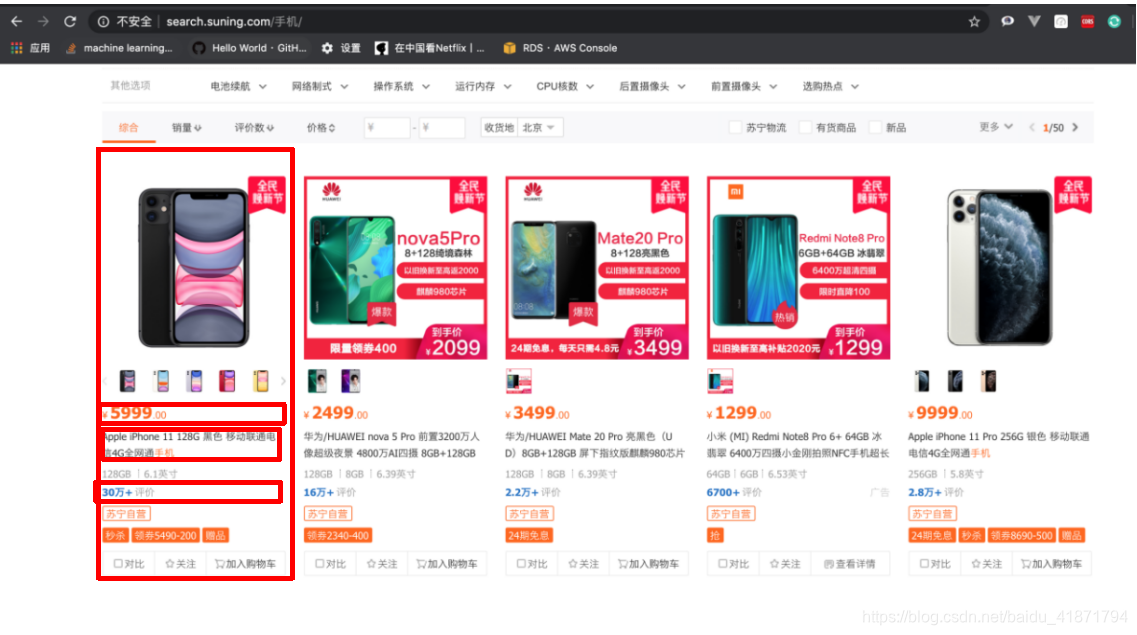
首先,我需要现在主界面中,获取到商品id,商品的详细界面的url,以及商品的价格,商品的评论数,店铺名称。
问题:从苏宁爬取商品的价格时,价格数据是通过接口请求的,那个接口参数很难预设,所以有的价格爬取不到,默认为0.0

然后,根据获取到的商品详细界面的url,进入每个商品的商品详情界面。商品详情的url中,数字部分就是这个商品的id,对于不同型号的商品都会有不同的id,进入商品详情界面后,就可以获取商品的品牌,型号等详细信息。
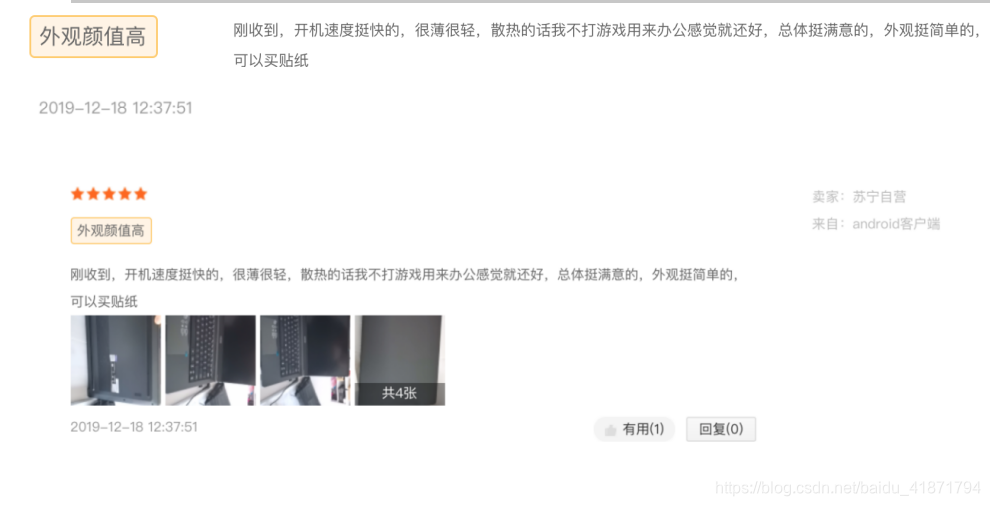
最后爬取评论信息,可以得到评论的内容,标签,评论时间等等。
【2】操作过程
(1)苏宁搜索主界面内容的网页源代码分析
在对搜索界面进行分析时,发现了url异步加载的规律,整页的内容不是同时加载的,而且根据向下翻页,分四次请求进行加载的。
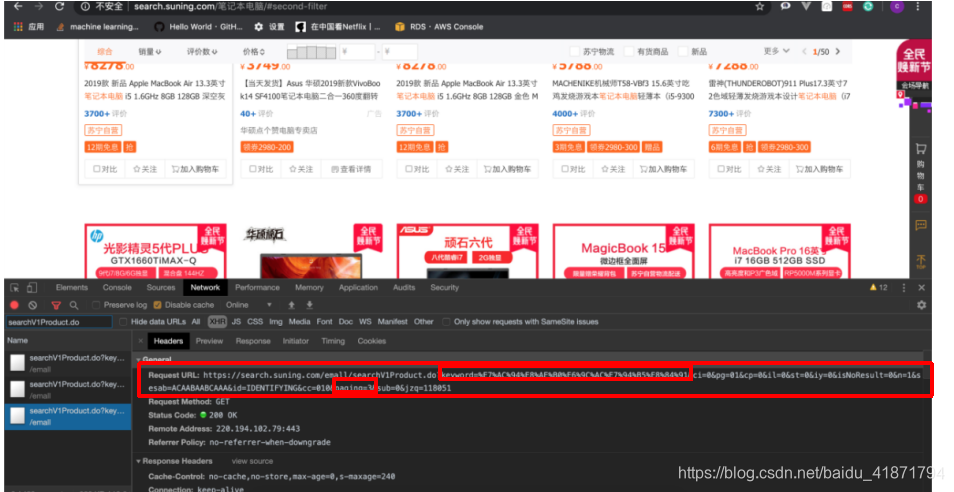
通过对url的分析发现
https://search.suning.com/emall/searchV1Product.do?keyword={}&ci=0&pg=01&cp={}&il=0&st=0&iy=0&adNumber=16&isNoResult=0&n=1&sesab=ACAABAABCAAA&id=IDENTIFYING&cc=010&paging={}&sub=0&jzq=112901
每页分为4层,直接请求 商品列表页地址 的话,只会显示第一层,其余 3层 是用户下拉后 异步加载出来的,使用抓包的方法可以截取到,所以每一页都分为 4步来分别请求
商品列表页 一共有 50页,请求地址参数中的 cp 为页数(0~49),paging 为层数(0~3)
商品详情页 可以加载出 商品价格页,携带 商品的id 即可请求
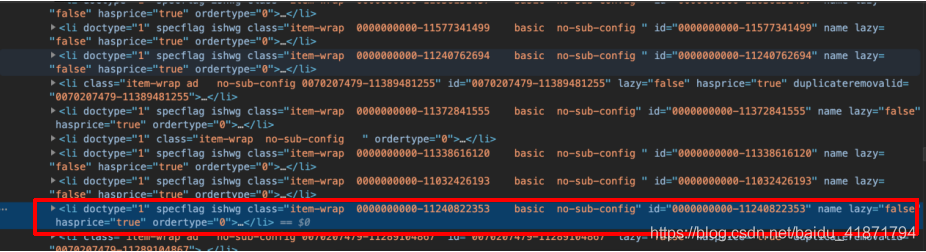
li中存储了所有的信息
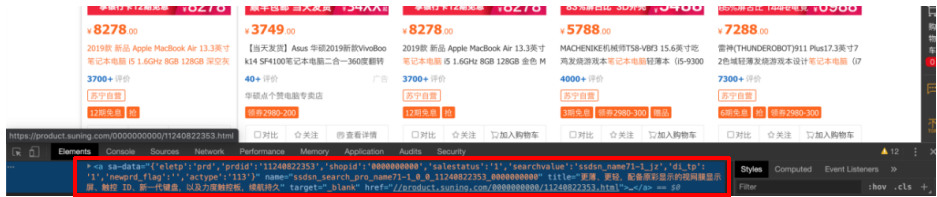
- 商品详细信息的url
.product-box .res-img .img-block a::attr(href)
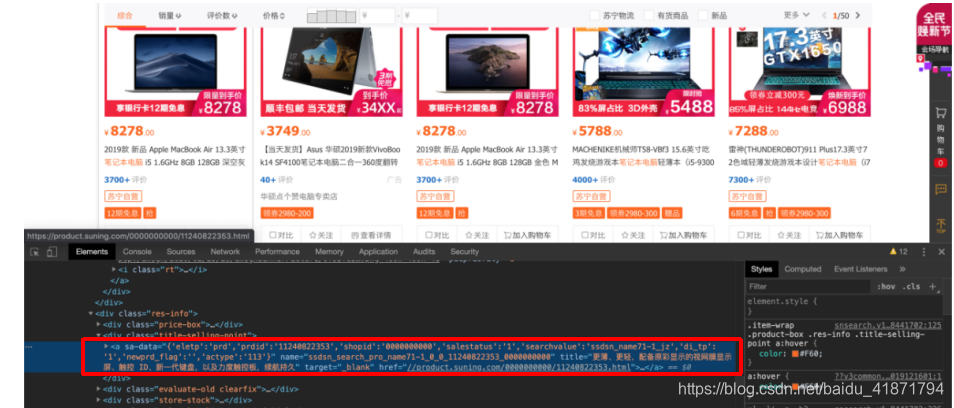
- 商品的评论数
.product-box .res-info .evaluate-old.clearfix .info-evaluate a
i::text’
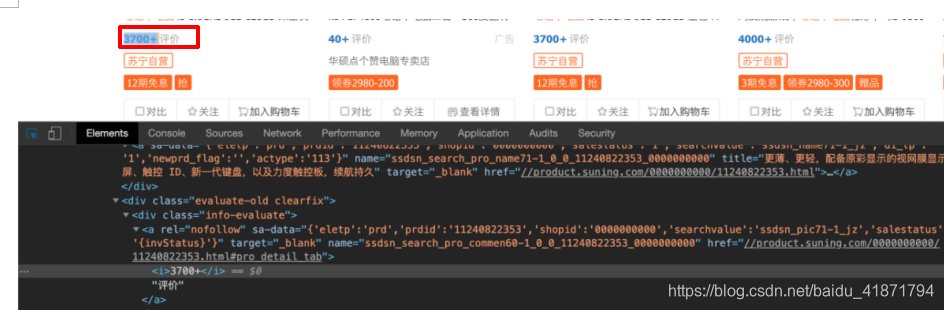
- 店铺名称
.product-box .res-info .store-stock a::text
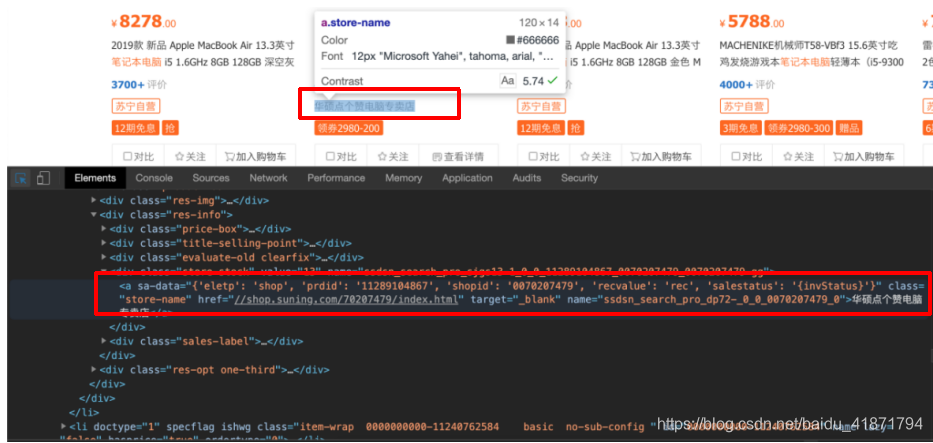
- 商品标题信息
.product-box .res-img .img-block a img::attr(alt)
- 对于商品价格的爬取,本来以为是界面上的,经过分析发现,商品的价格是异步加载的。
实际上商品的价格是通过接口动态请求的,有很大的不确定性,所以请求不到价格的商品,默认价格为0.0
接口为
https://icps.suning.com/icps-web/getVarnishAllPriceNoCache/0000000{id}_010_0100100_0000000000_1_getClusterPrice.jsonp?callback=getClusterPrice
- 商品的id
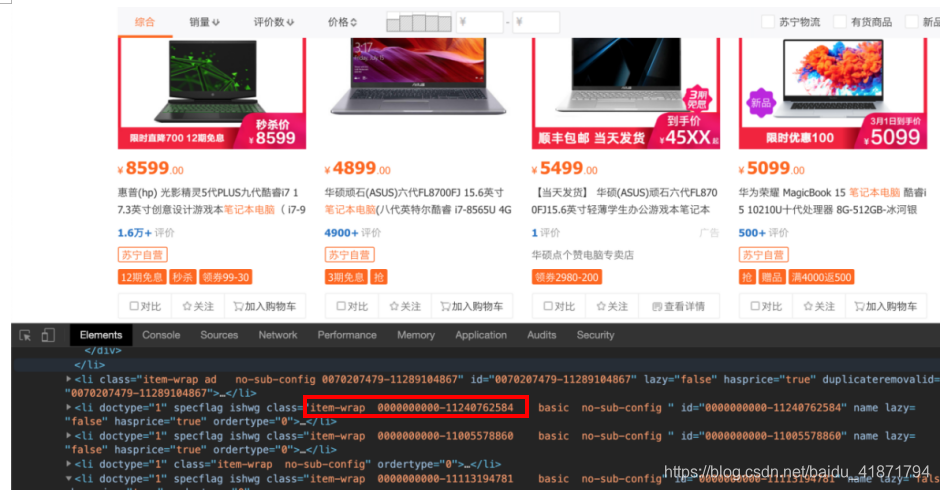
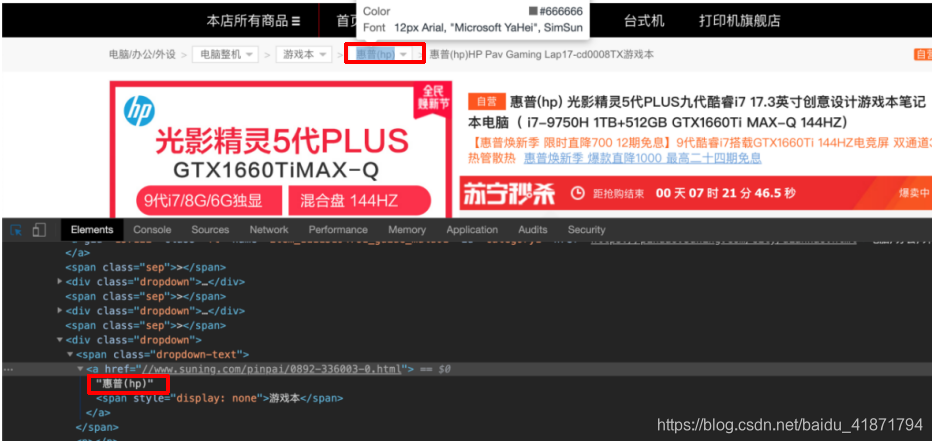
(2)苏宁商品详情界面的分析 - 商品的品牌
.dropdown .dropdown-text a::text
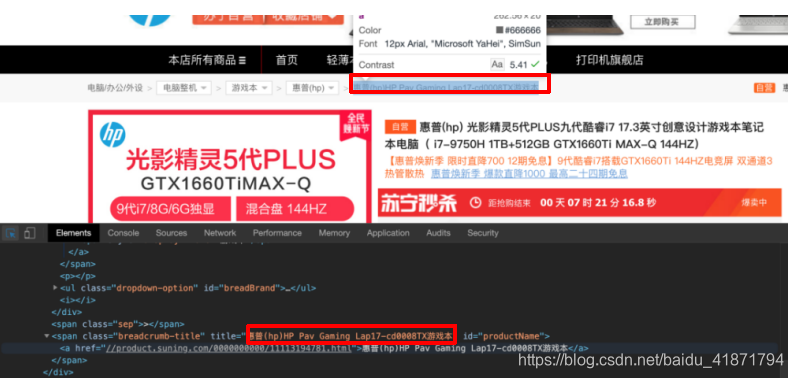
- 商品的型号
.breadcrumb-title::attr(title)
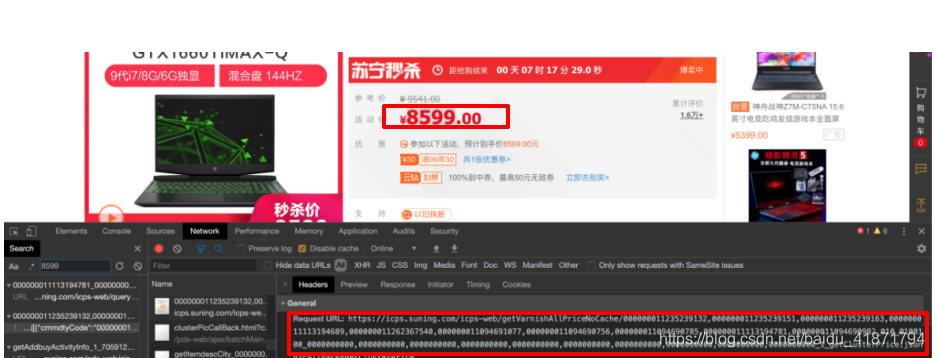
- 商品的价格
查询到的获取商品价格的接口
https://icps.suning.com/icps-web/getVarnishAllPriceNoCache/0000000%s_010_0100100_0000000000_1_getClusterPrice.jsonp?callback=getClusterPrice
(3)苏宁商品详细信息的评论
找到了获取评论的接口,经过分析得到获取评论的url,也是根据商品的id以及评论的页数进行请求
请求到了json文件,然后用python的json库进行解析即可
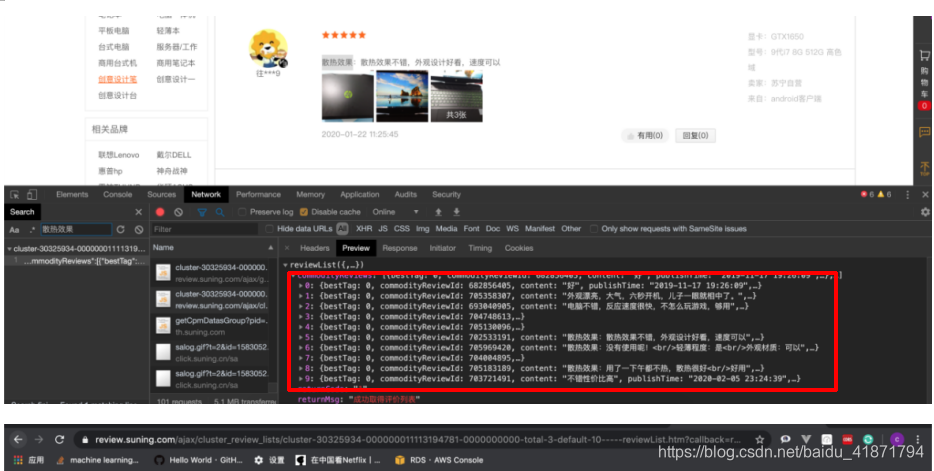
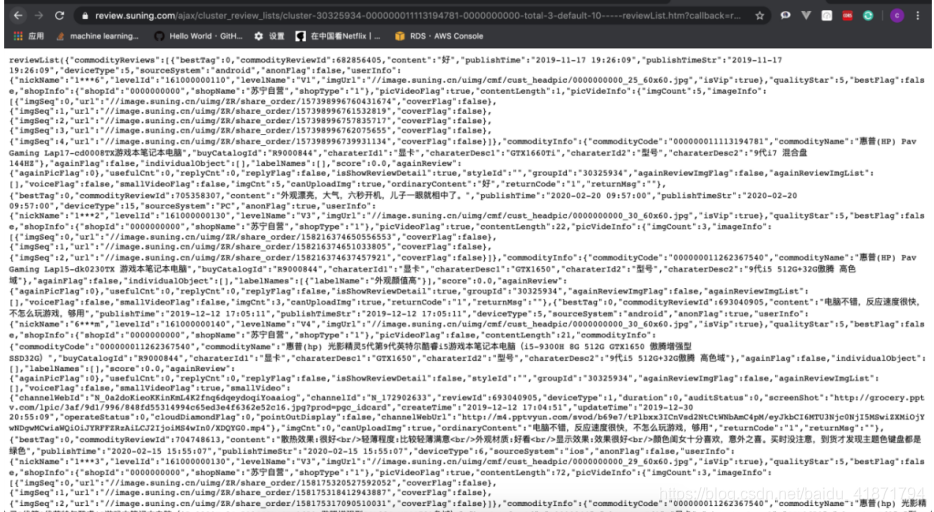
https://review.suning.com/ajax/cluster_review_lists/general-00000000-{}-0000000000-total-{}-default-10-----reviewList.htm
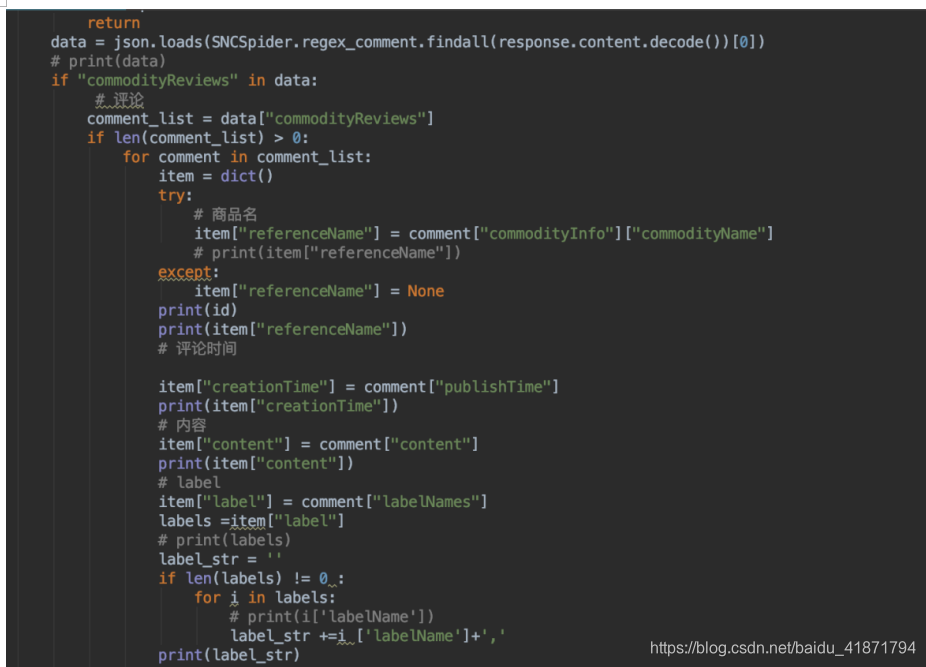
【3】数据库表的设计
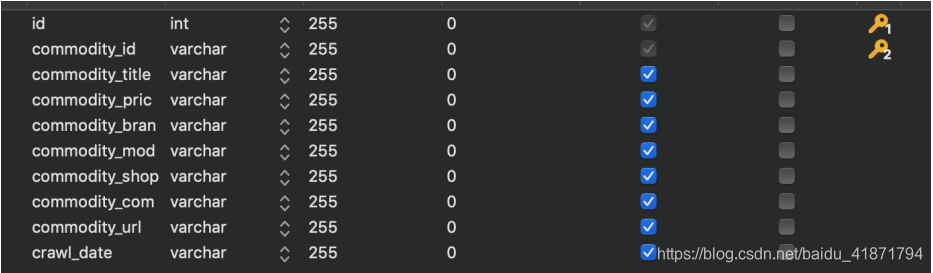
商品id (commodity_id)
商品标题 (commodity_title)
商品详情页网址 (commodity_url)
商品的网店名称 (commodity_shop_name)
商品价格 (commodity_price)
商品牌子 (commodity_brand)
商品型号 (commodity_model)
商品评论数量 (comment_count)
爬取时间(crawl_date)
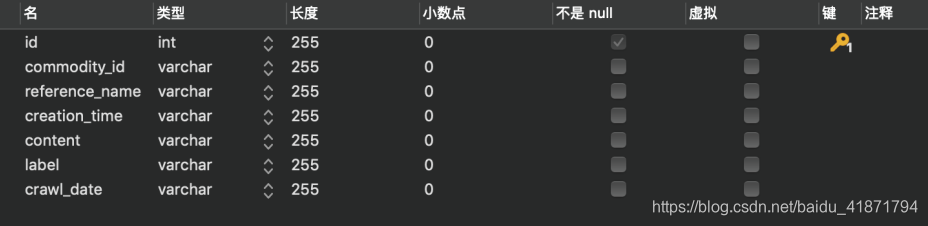
商品id (commodity_id)
商品标签名称 (referrnce_name)
评论的评论数 (replyCount)
评论内容(content)
标签(label)
爬取时间(crawl_data)
评论时间(creation_time)
【4】代码实现
项目代码在github ,如果觉得有用,请点个star
https://github.com/ccclll777/JDSNCompare
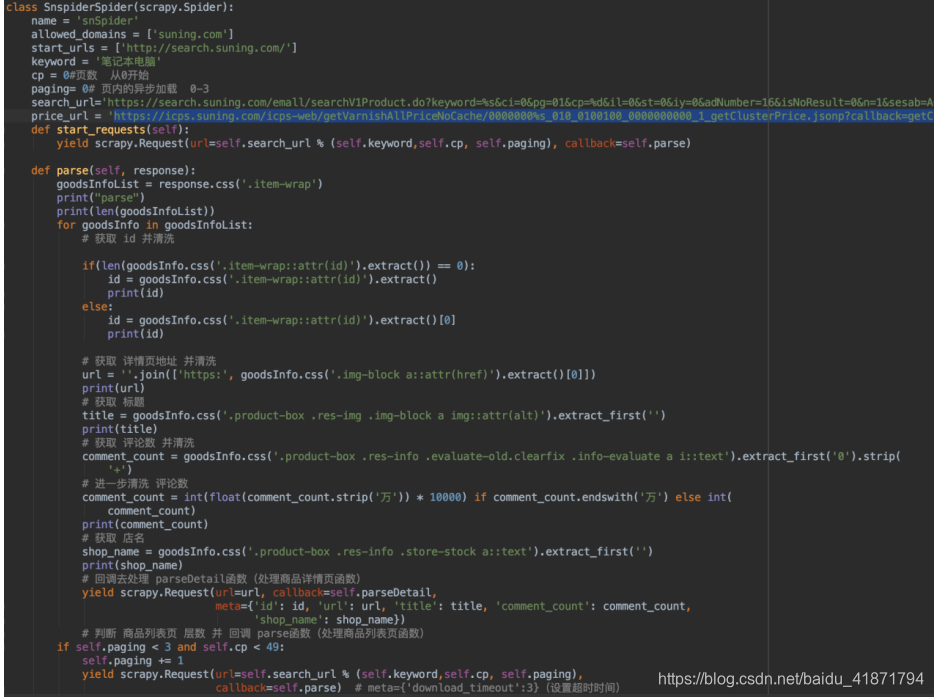
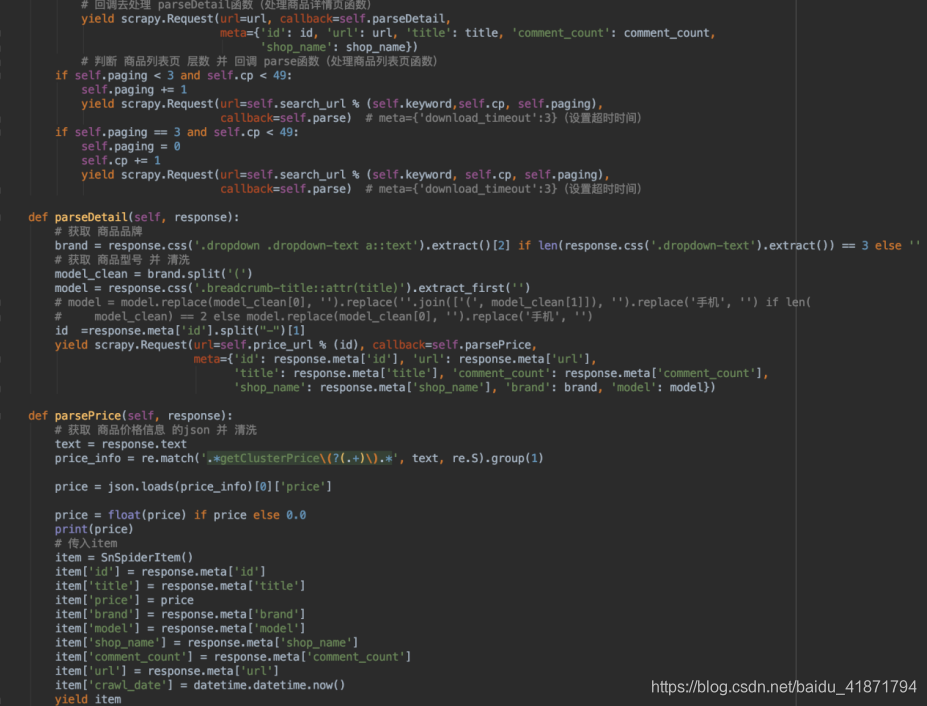
(1)苏宁商品信息爬虫,使用scrapy框架
首先请求search界面,通过之前的分析,加载每一页数据(中间需要分四次用不同的请求请求数据),爬取到search界面的每条数据后,都会转到详情界面,爬取物品的详情,然后爬取商品的价格(价格不是一开始就在界面上的,是通过接口动态请求的,可能会请求不到,所以没请求到价格的数据默认为0.0),然后将数据存入数据库(具体的代码中都有注释)
请求价格的接口为:将id换成对应id即可
https://icps.suning.com/icps-web/getVarnishAllPriceNoCache/0000000{id}_010_0100100_0000000000_1_getClusterPrice.jsonp?callback=getClusterPrice
(2)苏宁评论信息
获取图片需要到商品的详情界面,找到对应的图片标签重的图片链接即可,然后使用urllib将图片资源下载到本地(由于刚开始没有爬图片,图片时在做网站时需要,才爬的图片,所以没有写在一起)
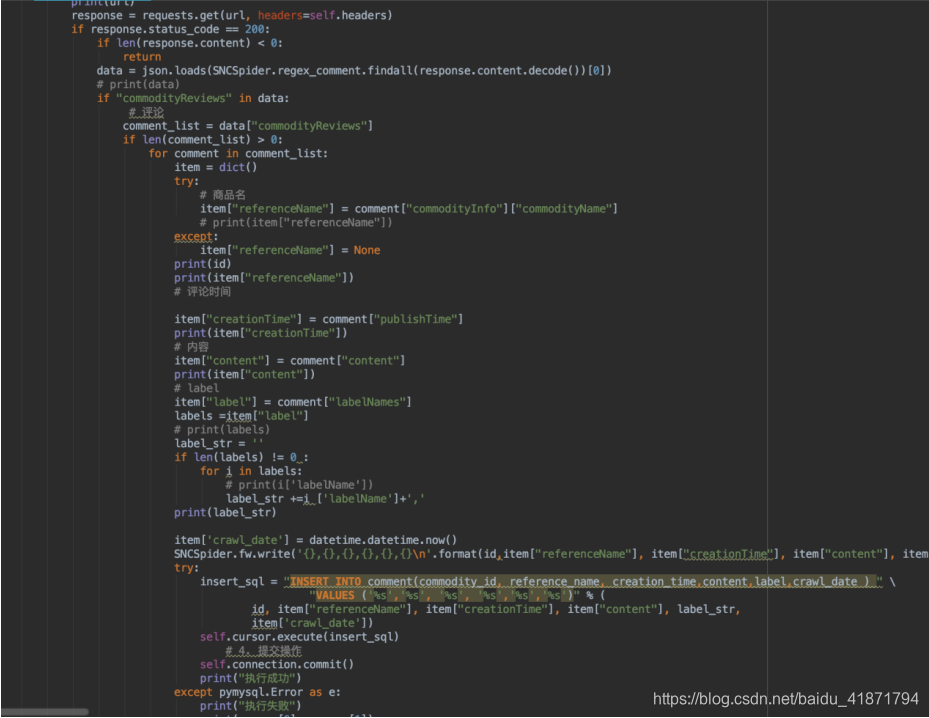
(3)获取苏宁商品图片
将两个平台的数据汇总到前端界面,进行价格比较
【0】项目技术栈
python语言开发后端,使用django框架(python3.7)
Html+css+javascript开发前端使用vue+iview框架
项目地址:http://39.105.44.114:38888/comparePrice/index.html
【1】首页
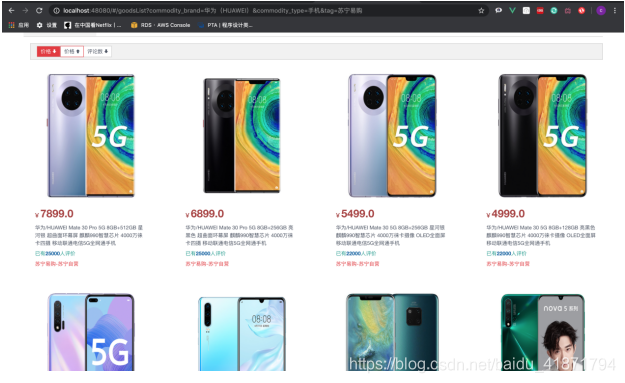
【2】点击相关商品,进入商品列表
可以按照价格,评论数排序,并且实现了分页功能,并且不同平台的商品有着不同的标记(苏宁易购 或者京东)
(1)按价格降序
(2)按评论数量降序
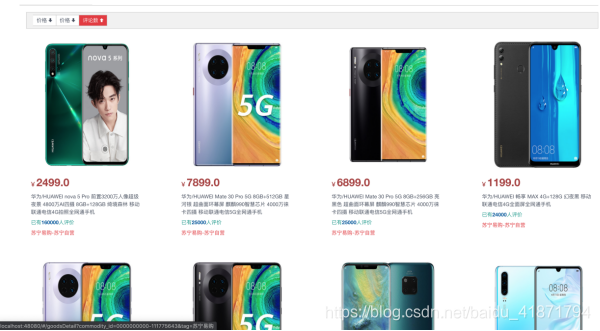
(3)实现分页
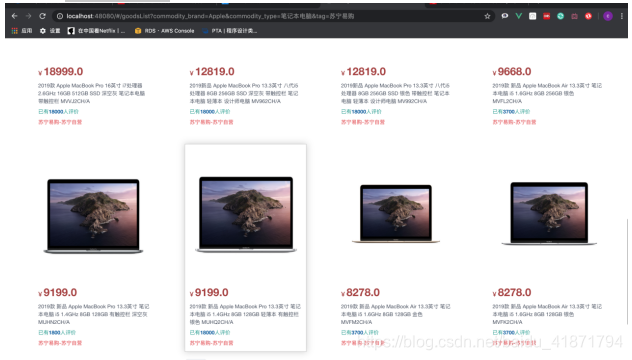
【3】搜索商品功能
可以根据品牌型号搜索,后端会自动对搜索的关键词和商品的品牌,商品的描述进行比对,选择编辑距离最小的进行输出(由于没有提前建好关键词索引,所以搜索比较慢,需要20s左右,以后加入索引可能会更快)
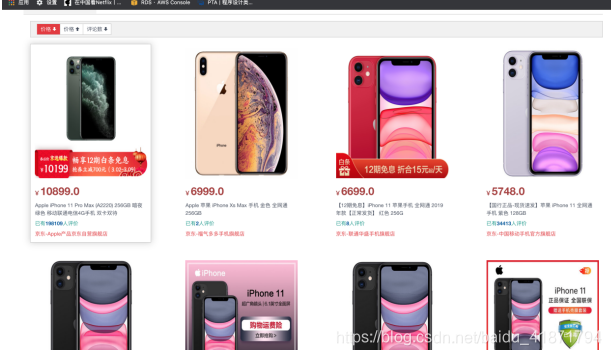
(1)搜索iPhone XS MAX
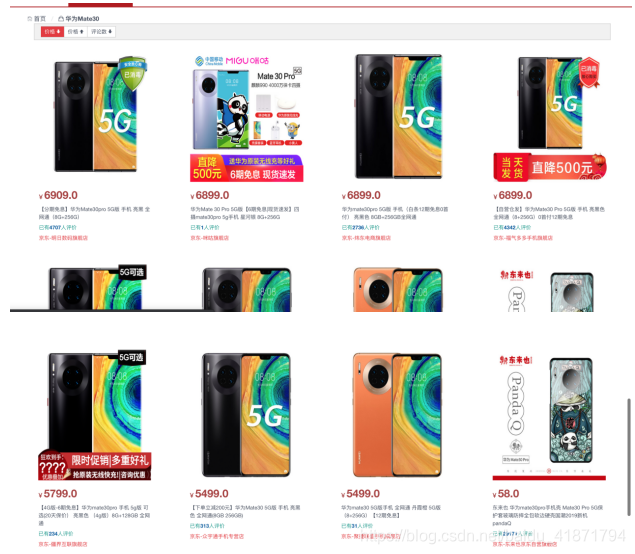
(2)搜索华为 mate 30
(3)搜索惠普(HP)光影精灵
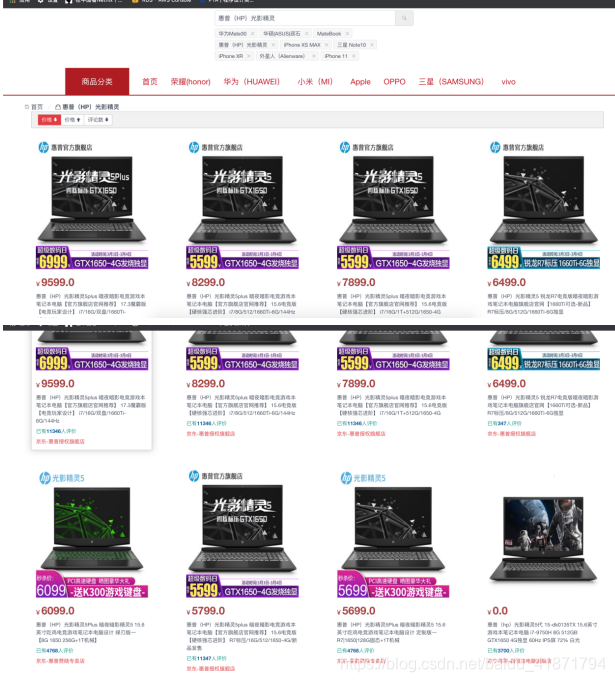
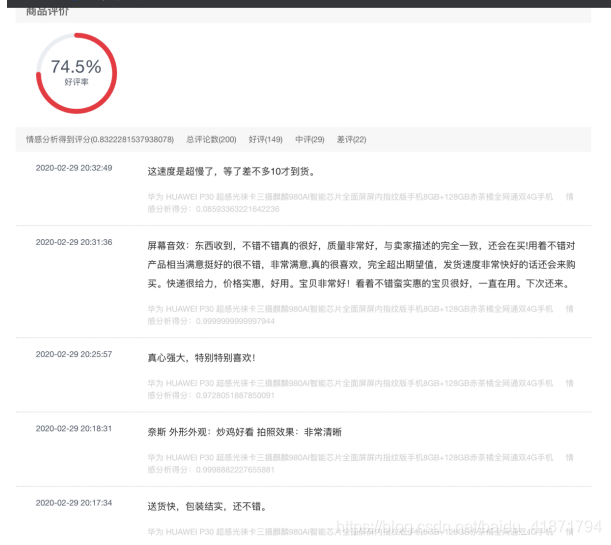
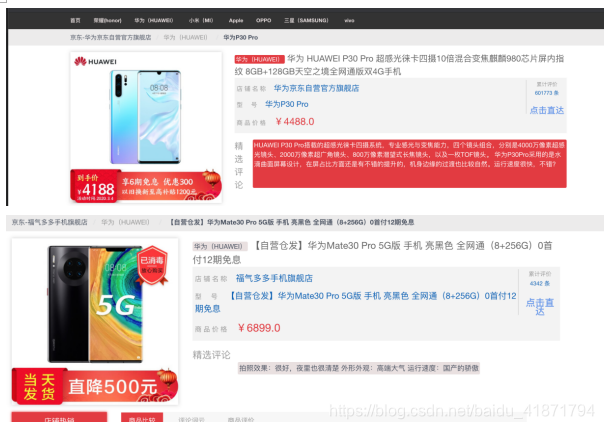
【4】商品详情界面
(1)展示商品的详细信息
可以点击链接直接到售卖的店铺
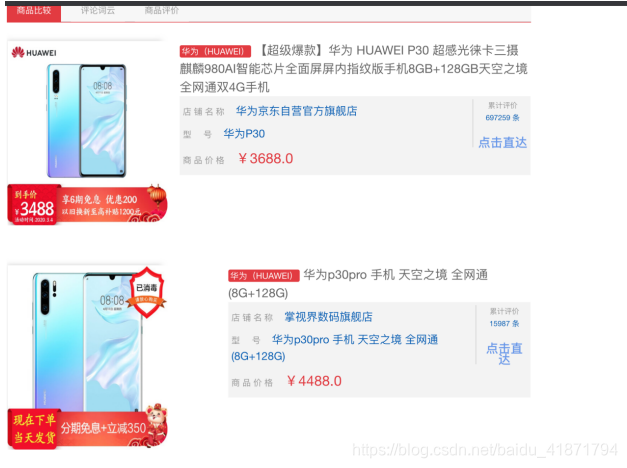
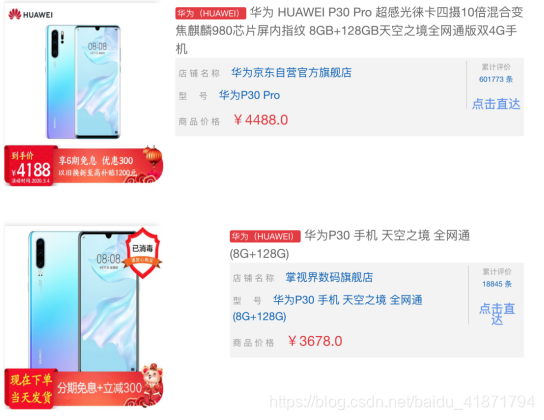
(2)商品比较
会查询出和这个手机型号相同或相似的手机品牌,可以进行比较
(后端实现为,先搜索品牌和型号,然后对比相似性,最后在对比商品描述的相似性,寻找相似商品)
(3)绘制评论词云
将爬取到的评论信息绘制成词云,供用户查看。

(4)展示爬取到的商品评论,并对整体已经每一句评论做了情感分析