数据建模
- 英文为 Data Modeling, 为创建数据模型的过程
- 数据模型(Data Model)
- 对现实世界进行抽象描述的一种工具和方法
- 通过抽象的实体及实体之间联系的形式去描述业务规则,从而实现对现实世界的映射
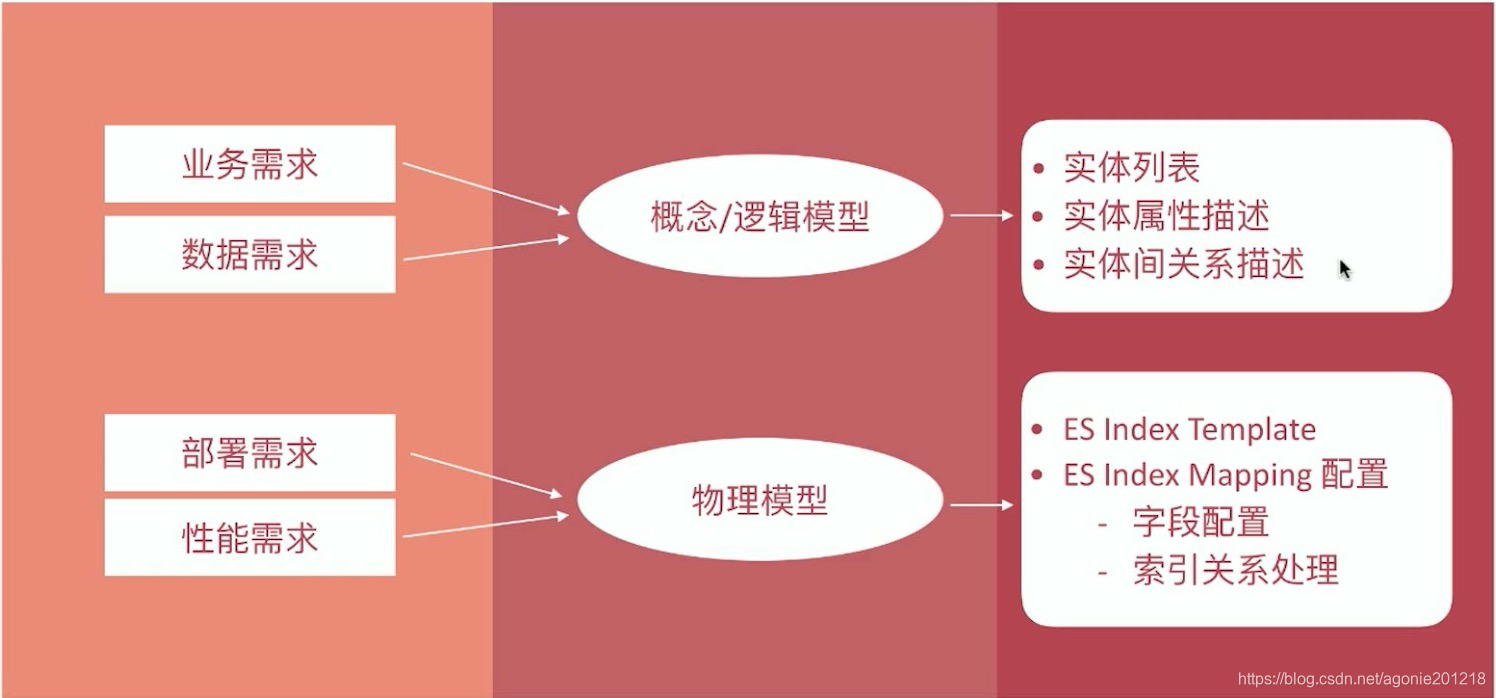
数据建模的过程
- 概念模型
- 确定系统的核心需求和范围边界,设计实体和实体间的关系 - 逻辑模型
- 进一步梳理业务需求,确定每个实体的属性、关系和约束等 - 物理模型
- 结合具体的数据库产品,在满足业务读写性能需求的前提下确定最终的定义
- Mysql、MongoDB、elasticsearch等
- 第三范式
数据建模的意义

ES中的数据建模
- ES 是基于 Lucene 以倒排索引为基础实现的存储体系,不遵循关系型数据库中的范式预定
Mapping 字段的相关设置
enbaled
- true | false
- 仅存储,不做搜索或聚合分析
index
- true | false
- 是否构建倒排索引
index_option
- docs | freqs | positions | offsets
- 存储倒排索引的那些信息
norms
- true| false
- 是否存储归一化相关参数,如果字段仅用于过滤和聚合分析,可关闭
doc_values
- true| false
- 是否启用 doc_values,用于排序和集合分析
field_data
- true| false
- 是否为text类型启用 fielddata,实现排序和聚合分析
store
- true| false
- 是否存储该字段
coerce
- true| false
- 是否开启自动数据类型转化,比如字符串转为数字、浮点转为整型等
multifields 多字段
- 灵活使用多字段特性来解决多样的业务需求
dynamic
- true| false | strict
- 控制 mapping 自动更新
date_datection
- true| false
- 是否自动识别日期类型
Mapping 字段属性的设定流程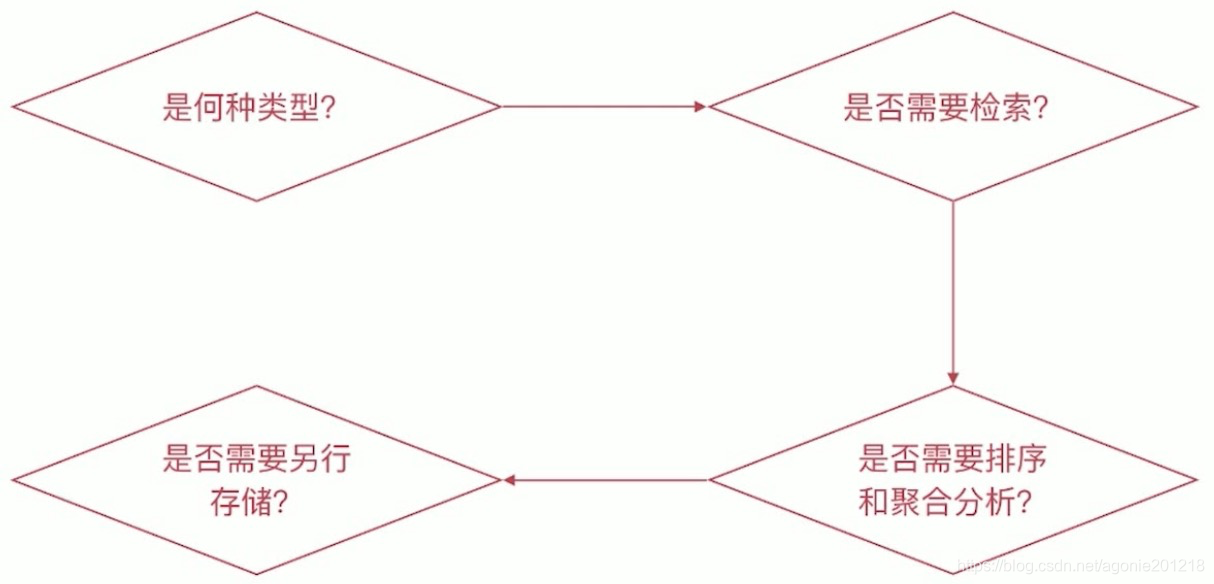
是何种类型
字符串类型
- 需要分词则设定为 text 类型, 否则设置为 keyword 类型
枚举类型
- 基于性能考虑将其设定为 keyword 类型,即便该数据为整型
数值类型
- 尽量选择贴近的类型,比如byte即可表示所有数值是,即选用 byte ,不要用 long
其他类型
- 比如布尔类型、日期、地理位置数据等
是否需要索引
- 完全不需要检索、排序、聚合分析的字段
- enable 设置为false - 不需要检索的字段
- index 设置为 false - 需要检索的字段,可以通过如下配置设定需要的存储粒度
- index_options 结合需要设定
- norms 不需要归一化数据是关闭即可
不需要排序或者聚合分析功能
- doc_values 设定为 false
- fielddata 设定为 false
是否需要另行存储?
- 是否需要专门存储当前字段的数据?
- store 设定为 true,即可存储该字段的原始内容(与_source 中的不相关)
- 一般结合_source的enabled 设定为false
实例
博客文章 blog_index
- 标题 title
- 发布日期 publish_date
- 作者 author
- 摘要 abstract
- 网络地址 url
blog_index 的 mapping 设置如下:

博客文章 blog_index
- 标题 title
- 发布日期 publish_date
- 作者 author
- 摘要 abstract
- 内容 content ## 加入一个大字段如何设置mapping
- 网络地址 url
- blog_index 的 mapping 设置如下

用 _source= … 也可过滤,但他只在coordinating 节点做过滤,各个节点返回coordinating 节点的 _source 还是一样的内容。
实例

关联关系处理
- ES 不擅长处理关系型数据库中的关联关系,比如文章表 blog 与评论表 comment之间通过 blog_id 关联,在 ES 中可以通过如下两种手段相解决
- Nested Object
- Parent/Child - 评论 Comment
- 文章 Id blog_id
- 评论人 username
- 评论 日期 date
- 评论内容 content

关联关系处理之 Nested Object


- Comments 默认是 Object Array,存储结构类似下面的形式:

- Nested Object 可以解决这个问题


关联关系处理之 Parent/Child
- ES 还挺了类似关系数据库中 join 的实现方式,使用join数据类型实现
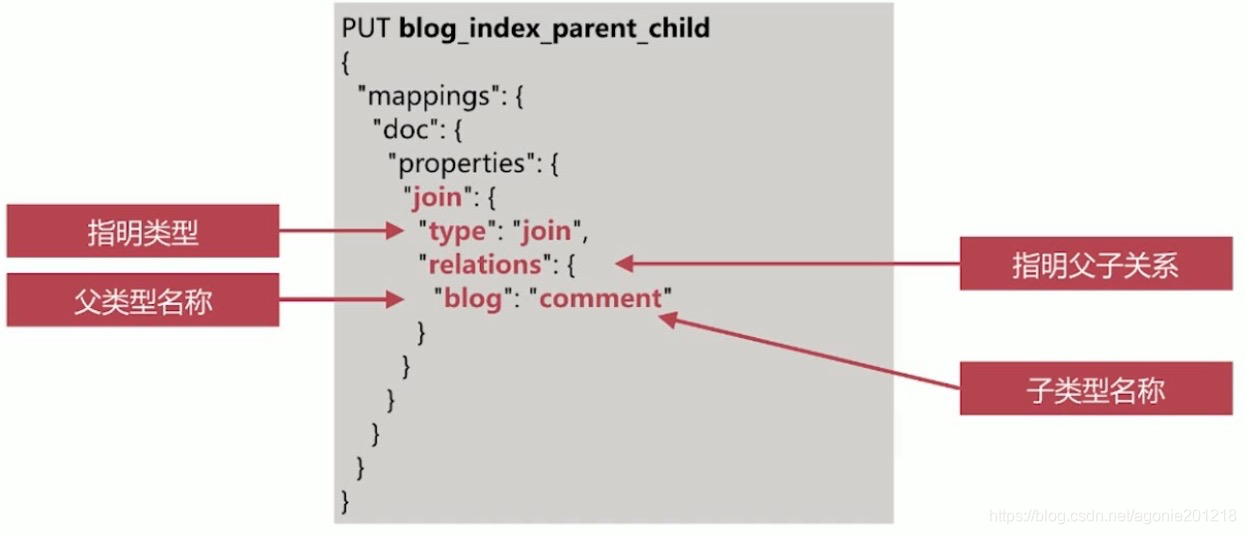
创建关系文档

查询关联语法
- 常见 query语法包括如下几种
- parent_id: 返回某父文档的子文档 (父文档 id 为2 的子文档)
- has_child 返回包含某子文档的父文档(评论包含 world 的父文档)
- has_parent 返回包含某父文档的子文档(标题为 ‘blog’ 的子文档)

Nested Object vs Parent/Child

建议尽量选择 Nested Object 来解决问题
Reindex
- 指重建所有数据的过程,一般发生在如下情况:
- mapping 设置变更,比如字段类型变化、分词器字典更新等
- index 设置变更,比如分片数更改等
- 迁移数据 - ES 提供了现成的API 用于完成该工作
- _update_by_query 在现有索引上重建
- _reindex 在其他索引上重建
Reindex - _update_by_query
将 blog_index 的所有文档重建一遍;conflicts=proceed 覆盖之后来的更新

Reindex - _reindex
将 blog_index 重建到 blog_new_index 中

query -> 迁移部分文档

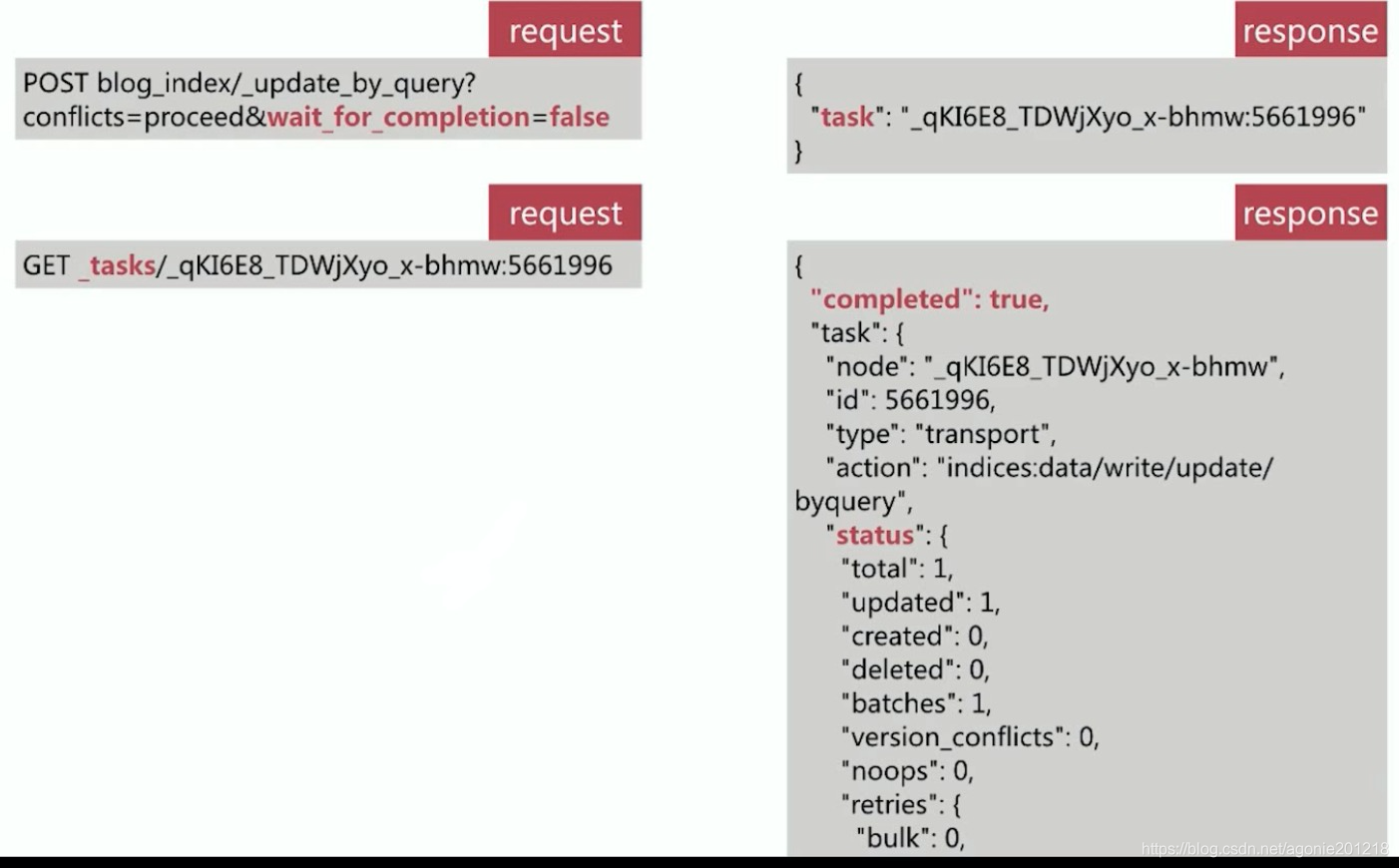
Reindex -Task
- 数据重建的时间受索引文档规模的影响,当规模越大,所系时间越多,此时需要通过设定url 参数 wait_for_completion 为false 来异步执行,ES以 task 来描述此类执行任务
- ES 提供了 Task API 来查看任务的执行进度和相关数据