Logstash介绍
Logstash是一个具有实时管道功能的开源数据收集引擎,Logstash可以动态地将来自不同数据源的数据统一起来,并将数据规范化为你选择的目的地,清理和大众化你的所有数据,用于各种高级下游分析和可视化用例。
虽然Logstash最初推动了日志收集方面的创新,但是它的功能远远超出了这个用例,任何类型的事件都可以通过大量的输入、过滤器和输出插件来丰富和转换,使用许多原生编解码可以进一步简化摄取过程。Logstash通过利用大量和多种数据来提高你的洞察力。
数据收集处理引擎
Logstash 在数据收集处理中的位置如下图(框架简介)。
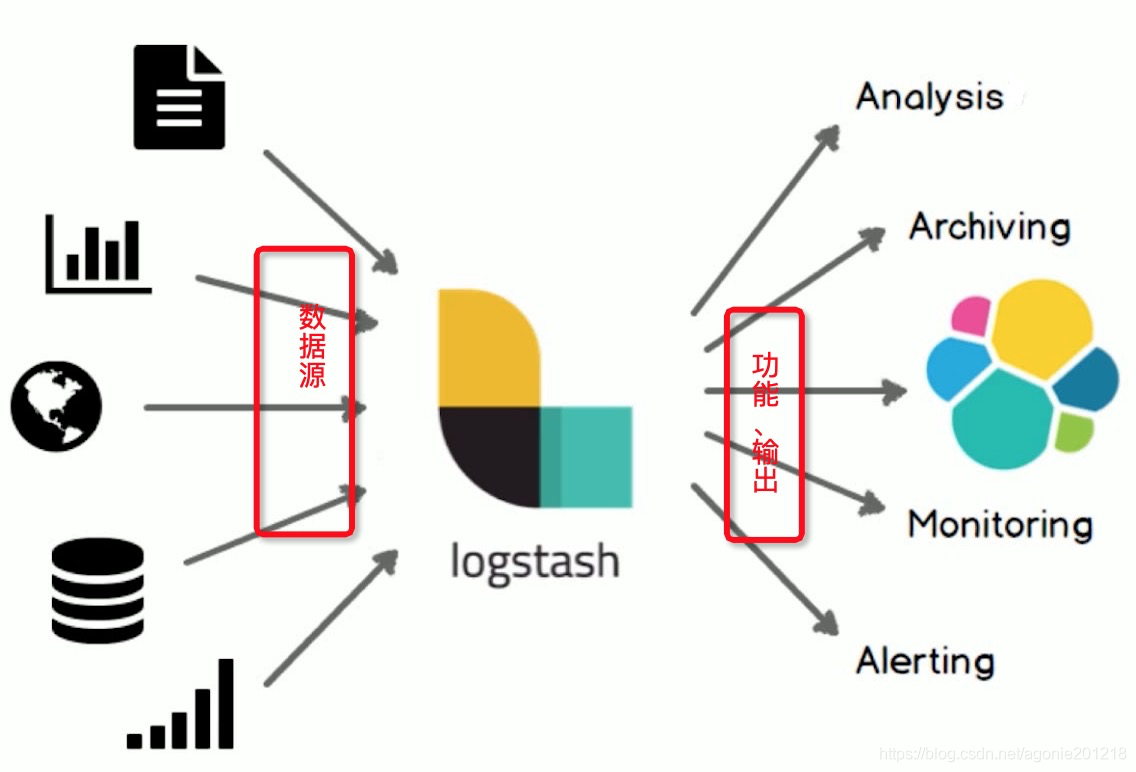
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
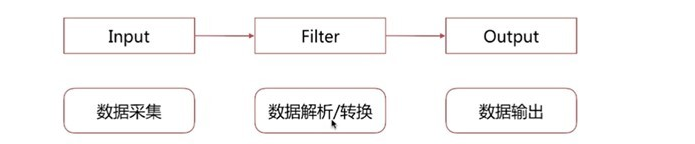
工作流程
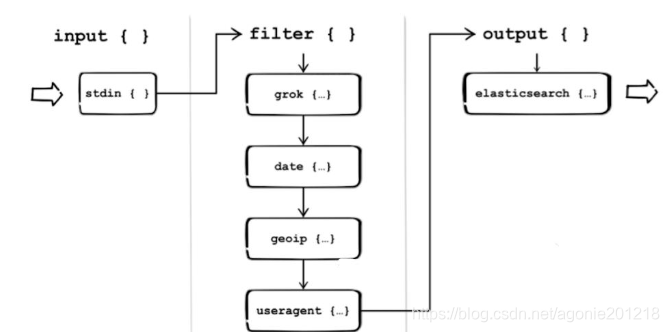
- Logstash 分为三个阶段
- 完备的 Logstash 处理流进过的过程
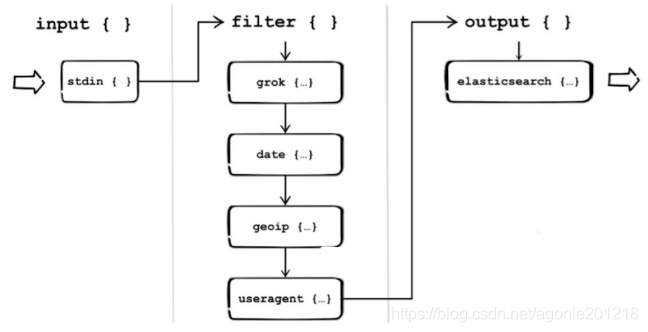
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能 - (1)Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等
- (2)Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等
- (3)Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等
- (4)Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline
可以点击每个模块后面的详细参考链接了解该模块的插件列表及对应功能
执行模型:
-
(1)每个Input启动一个线程,从对应数据源获取数据
-
(2)Input会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失Logstash提供了两个特性:
Persistent Queues:通过磁盘上的queue来防止数据丢失 Dead Letter Queues:保存无法处理的event(仅支持Elasticsearch作为输出源) -
(3)Logstash会有多个pipeline worker, 每一个pipeline worker会从队列中取一批数据,然后执行filter和output(worker数目及每次处理的数据量均由配置确定)
Logstash使用示例
Logstash Hello world
第一个示例Logstash将采用标准输入和标准输出作为input和output,并且不指定filter
- (1)下载Logstash并解压(需要预先安装JDK8)
- (2)cd到Logstash的根目录,并执行启动命令如下:
cd logstash
bin/logstash -e 'input { stdin { } } output { stdout {} }'
- (3)此时Logstash已经启动成功,-e表示在启动时直接指定pipeline配置,当然也可以将该配置写入一个配置文件中,然后通过指定配置文件来启动
- (4)在控制台输入:hello world,可以看到如下输出:
{
"@timestamp" => 2020-03-08T08:11:01.333Z,
"@version" => "1",
"message" => "hello word",
"host" => "andydeMacBook-Pro-2.local"
}
Logstash会自动为数据添加@version, host, @timestamp等字段
在这个示例中Logstash从标准输入中获得数据,仅在数据中添加一些简单字段后将其输出到标准输出。
名称解析
- Pipeline
- input-filter-output的3阶段处理流程
- 队列管理
- 插件生命周期管理 - Logstash Event
- 内部流转的数据表现形式(封装数据)
- 原始数据在input被转换为Event ,在output event被转换为目标格式数据
- 在配置文件中可以对Event中的属性进行增删改查
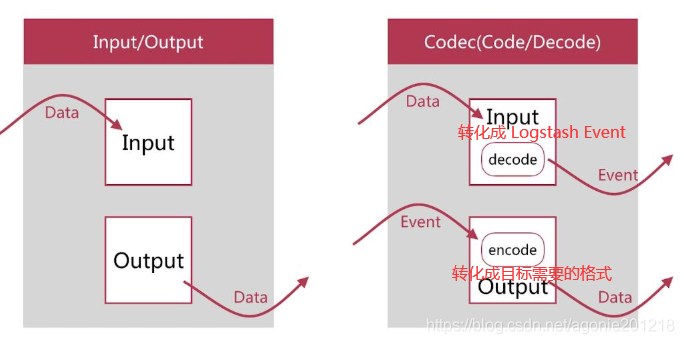
- 整体架构

举例配置文件
按指定配置文件运行
bin/logstash -f codec.conf

- Codec-Input Decoding (按行转化成 event)
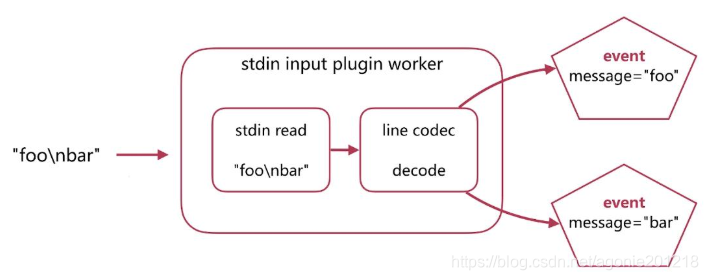
- Codec-Output Encoding (输出json)
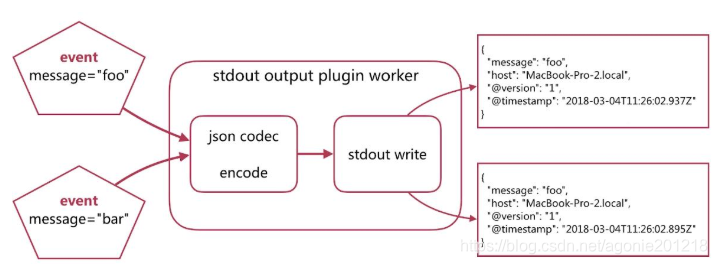
- 运行结果

Logstash 整个架构
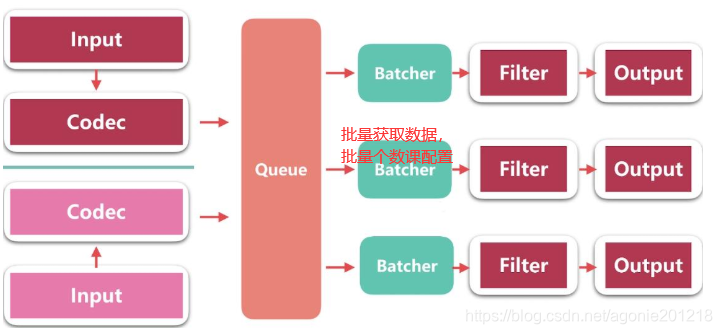
Logstash 整个生命历程时如何?
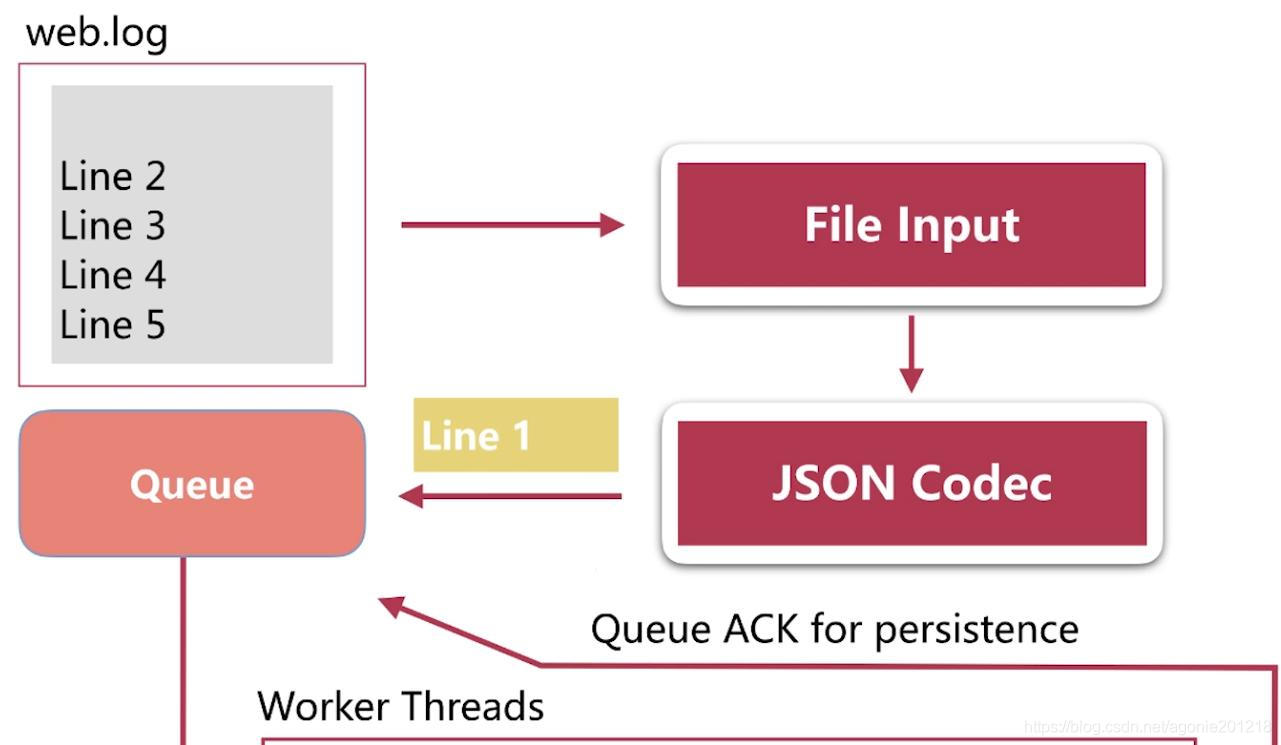
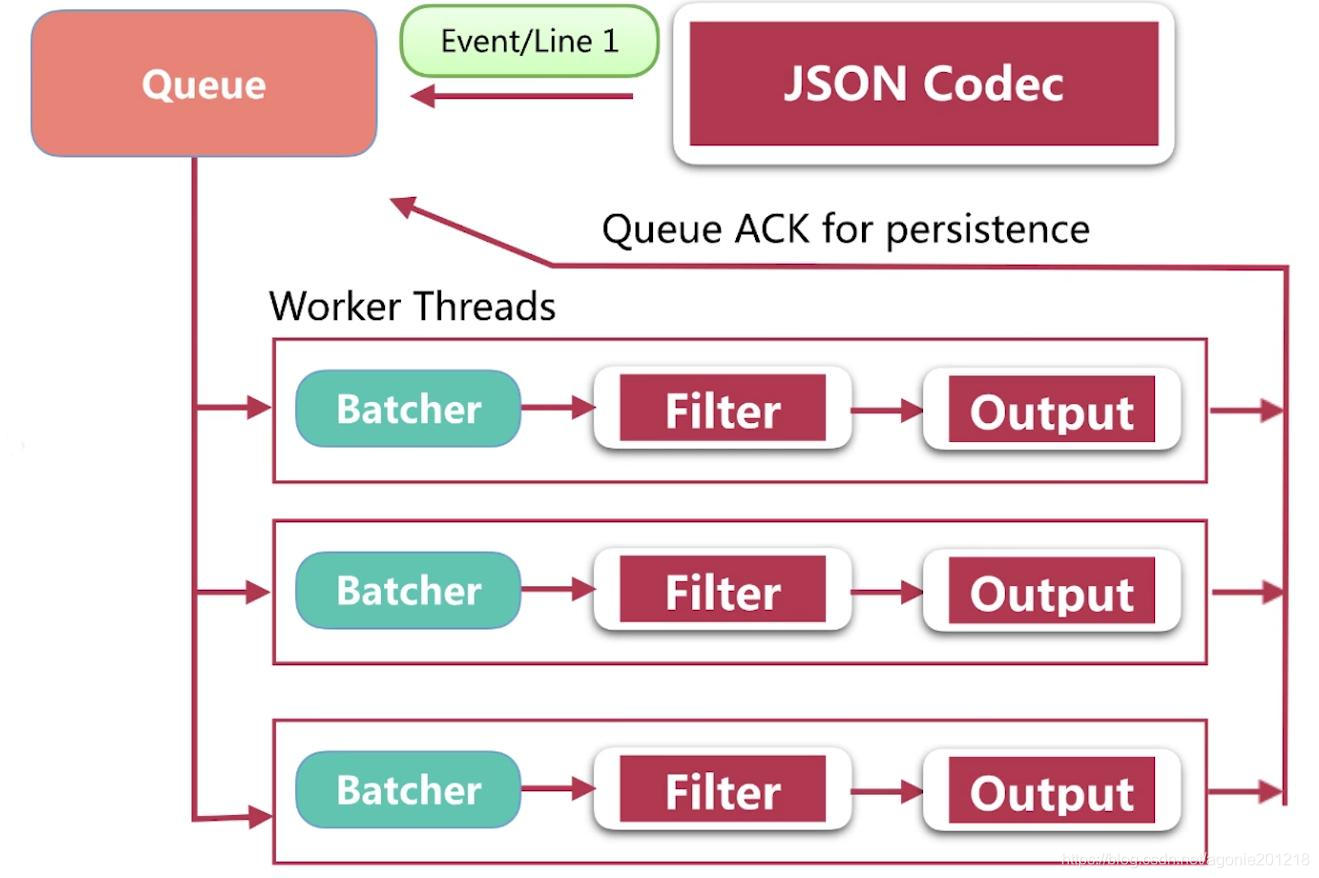
queue 简介
-
In Memory
- 无法处理进程Crash、机器宕机等情况,会导致数据丢失 -
Persistent Queue In Disk
- 可处理进程Crash等情况,保证数据不丢失 - 保证数据至少消费一次 - 充当缓冲区,可以替代Kafka等消息队列的作用
Persistent Queue

- 持久队列工作机制:
- 数据流向Data-1-2-3-4(红色)
- disk备份后PQ告诉input收到数据
- 然后 数据Data从PQ1-2-3(蓝色)
- filter/output会处理Data
- 2发送ack到PQ 3是把disk的备份数据删掉。处理到此结束。
- disk作用是解决数据容灾的问题
- 两种queue对比(性能相当,差异不大)
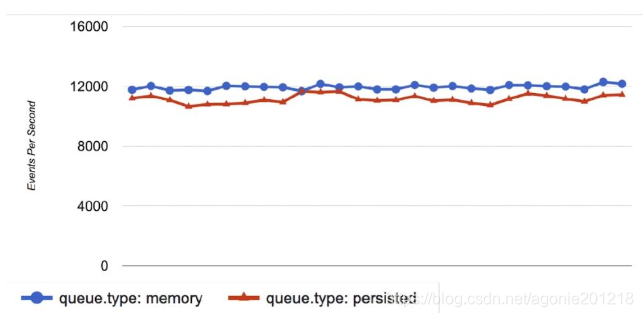
一般情况下打开persisted queue
- queue.type:persisted
默认是memory
queue.max_bytes:4gb - 队列存储最大数据量
其他的配置
https://www.elastic.co/guide/en/logstash/current/persistent-queues.html
线程相关简介
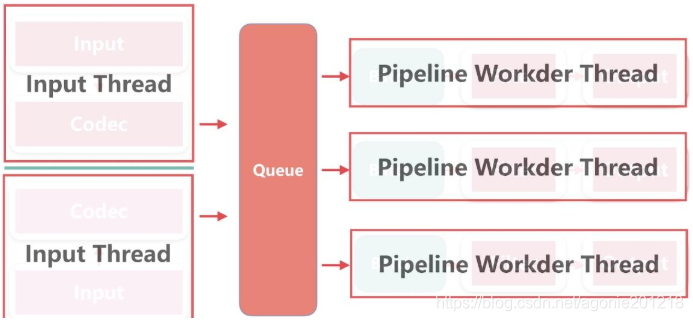
相关配置
- pipeline.workers |-w
- pipeline线程数,即filter-output的处理线程数,默认是cpu核数. - pipeline.batch.size l-b.
- Batcher一次批量获取的待处理文档数,默认125 ,可以根据输出进行调整,越大会占用越多的heap空间,可以通过jvm.options调整 - pipeline.batch.delay |-u
- Batcher等待的时长,单位为ms
GC 分配 线程的一些情况可以下载VisualVM来监控到。
配置简介
##logstash配置文件:
logstash设置相关的配置文件(在conf文件夹中, setting files )
- logstash.yml logstash相关的配置,比如node.name, path.data, pipeline.workers, queue.type等,这其中的配置可以被命令行参数中的相关参数覆盖
- jvm.options修改jvm的相关参数,比如修改heap size等
pipeline配置文件定义数据处理流程的文件,以.conf结尾
logstash.yml常用配置项
-
node.name
- 节点名,便于识别 -
path.data
- 持久化存储数据的文件夹,默认是logstash home目录下的data -
path.config
- 设定pipeline配置文件的目录 -
path.log
- 设定pipeline日志文件的目录 -
pipeline.workers
- 设定pipeline的线程数(filter+output) ,优化的常用项 -
pipeline.batch.size/delay
- 设定批量处理数据的数目和延迟 -
queue.type
- 设定队列类型,默认是memory -
queue.max_bytes
- 队列总容量,默认是1g
logstash命令行配置项
--node.name
-f --path.config pipeline路径,可以是文件或者文件夹
--path.settings logstash配置文件夹路径,其中要包含logstash.yml
-e --config.string指明pipeline内容,多用于测试使用
-w --pipeline.workers
-b --pipeline.batch.size
--path.data
--debug. 详细日志输出
-t --confia.test and exit
两种配置使用场合
·线上环境推荐采用配置文件的方式来设定logstash的相关配置,这样可以减少犯错的机会,而且文件便于进行版本化管理
·命令行形式多用来进行快速的配置测试、验证、检查等
pipeline配置简介
pipeline用于配置input、filter、output插件,框架如下:
input {}
filter {}
output {}
配置语法
数值类型







例子
调试的配置建议
调试建议大家使用如下配置:
- http 作为 input, 方便输入测试数据,并且可以结合reload 特性(stdin无法 reload)
- stdout 做 output,codec使用 rubydebug,即时查看解析结果
- 测试错误输入情况下的输出,以便对错误情况进行处理

处理的建议
@metadata 特殊字段字段
在logstash1.5版本开始,有一个特殊的字段,叫做@metadata。@metadata包含的内容不会作为事件的一部分输出。
- 适合用来存储做条件判断、临时存储的字段
- 相比 remove_field 有一定的性能提升

部署Logstash
演示过如何快速使用Logstash后,现在详细讲述一下Logstash的部署方式。
1. 安装
- 安装JDK:Logstash采用JRuby编写,运行需要JDK环境,因此安装Logstash前需要先安装JDK。(当前6.4仅支持JDK8)
- 安装Logstash:可以采用直接下载压缩包方式安装,也通过APT或YUM安装,另外Logstash支持安装到Docker中。
- 安装X-PACK:在6.3及之后版本X-PACK会随Logstash安装,在此之前需要手动安装
2. 目录结构
logstash的目录主要包括:根目录、bin目录、配置目录、日志目录、插件目录、数据目录
3. 配置文件
- Pipeline配置文件,名称可以自定义,在启动Logstash时显式指定,编写方式可以参考前面示例,对于具体插件的配置方式参见具体插件的说明(使用Logstash时必须配置):
用于定义一个pipeline,数据处理方式和输出源 - Settings配置文件(可以使用默认配置):
在使用Logstash时可以不用设置,用于性能调优,日志记录等- logstash.yml:用于控制logstash的执行过程
- pipelines.yml: 如果有多个pipeline时使用该配置来配置多pipeline执行
- jvm.options:jvm的配置
- log4j2.properties:log4j 2的配置,用于记录logstash运行日志[参考链接]
- startup.options: 仅适用于Lniux系统,用于设置系统启动项目!
- 为了保证敏感配置的安全性,logstash提供了配置加密功能
4. 启动关闭方式
bin/logstash [options]
Logstash places the systemd unit files in /etc/systemd/system for both deb and rpm.
sudo systemctl start logstash.service
- 在docker中启动3.4.2 关闭
- 关闭Logstash
- Logstash的关闭时会先关闭input停止输入,然后处理完所有进行中的事件,然后才完全停止,以防止数据丢失,但这也导致停止过程出现延迟或失败的情况。
5. 扩展Logstash
当单个Logstash无法满足性能需求时,可以采用横向扩展的方式来提高Logstash的处理能力。横向扩展的多个Logstash相互独立,采用相同的pipeline配置,另外可以在这多个Logstash前增加一个LoadBalance,以实现多个Logstash的负载均衡。
6.性能调优
-
(1)Inputs和Outputs的性能:当输入输出源的性能已经达到上限,那么性能瓶颈不在Logstash,应优先对输入输出源的性能进行调优。
-
(2)系统性能指标:
- CPU:确定CPU使用率是否过高,如果CPU过高则先查看JVM堆空间使用率部分,确认是否为GC频繁导致,如果GC正常,则可以通过调节Logstash worker相关配置来解决。
- 内存:由于Logstash运行在JVM上,因此注意调整JVM堆空间上限,以便其有足够的运行空间。另外注意Logstash所在机器上是否有其他应用占用了大量内存,导致Logstash内存磁盘交换频繁。
- I/O使用率:
1)磁盘IO:
磁盘IO饱和可能是因为使用了会导致磁盘IO饱和的创建(如file output),另外Logstash中出现错误产生大量错误日志时也会导致磁盘IO饱和。Linux下可以通过iostat, dstat等查看磁盘IO情况
2)网络IO:
网络IO饱和一般发生在使用有大量网络操作的插件时。linux下可以使用dstat或iftop等查看网络IO情况
-(3)JVM堆检查:
- 如果JVM堆大小设置过小会导致GC频繁,从而导致CPU使用率过高
- 快速验证这个问题的方法是double堆大小,看性能是否有提升。注意要给系统至少预留1GB的空间。
- 为了精确查找问题可以使用jmap或VisualVM。[参考]
- 设置Xms和Xmx为相同值,防止堆大小在运行时调整,这个过程非常消耗性能。
-
(4)Logstash worker设置:
worker相关配置在logstash.yml中,主要包括如下三个:- pipeline.workers:
该参数用以指定Logstash中执行filter和output的线程数,当如果发现CPU使用率尚未达到上限,可以通过调整该参数,为Logstash提供更高的性能。建议将Worker数设置适当超过CPU核数可以减少IO等待时间对处理过程的影响。实际调优中可以先通过-w指定该参数,当确定好数值后再写入配置文件中。 - pipeline.batch.size:
该指标用于指定单个worker线程一次性执行flilter和output的event批量数。增大该值可以减少IO次数,提高处理速度,但是也以为这增加内存等资源的消耗。当与Elasticsearch联用时,该值可以用于指定Elasticsearch一次bluck操作的大小。 - pipeline.batch.delay:
该指标用于指定worker等待时间的超时时间,如果worker在该时间内没有等到pipeline.batch.size个事件,那么将直接开始执行filter和output而不再等待。
- pipeline.workers: