Flink架构与集群搭建
一、Flink基本架构
1.1 JobManager与TaskManager
Flink运行时包含了两种类型的处理器:
JobManager处理器:也称之为Master,用于协调分布式执行,它们用来调度task,协调检查点,协调失败时恢复等。Flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master处理器,它们其中有一个是leader,而其他的都是standby。
TaskManager处理器:也称之为Worker,用于执行一个dataflow的task(或者特殊的subtask)、数据缓冲和data stream的交换,Flink运行时至少会存在一个worker处理器。

Master和Worker处理器可以直接在物理机上启动,或者通过像YARN这样的资源调度框架。
Worker连接到Master,告知自身的可用性进而获得任务分配。
1.2 无界数据流与有界数据流
Flink用于处理有界和无界数据:
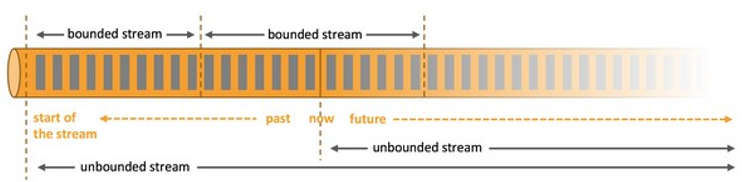
无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性。
有界数据流:有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为它们要实现的目标是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。例如,实现批处理的开源方案有MapReduce、Tez、Crunch、Spark,实现流处理的开源方案有Samza、Storm。
Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。基于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
1.3 数据流编程模型
Flink提供了不同级别的抽象,以开发流或批处理作业,如下图所示:

最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function)被嵌入到DataStream API中。底层过程函数(Process Function) 与 DataStream API 相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
实际上,大多数应用并不需要上述的底层抽象,而是针对核心API(Core APIs) 进行编程,比如DataStream API(有界或无界流数据)以及DataSet API(有界数据集)。这些API为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。DataSet API 为有界数据集提供了额外的支持,例如循环与迭代。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。Table API遵循(扩展的)关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。Table API程序声明式地定义了什么逻辑操作应该执行,而不是准确地确定这些操作代码的看上去如何 。 尽管Table API可以通过多种类型的用户自定义函数(UDF)进行扩展,其仍不如核心API更具表达能力,但是使用起来却更加简洁(代码量更少)。除此之外,Table API程序在执行之前会经过内置优化器进行优化。
可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
Flink提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行。
二、Flink集群搭建
Flink可以选择的部署方式有:
Local、Standalone(资源利用率低)、Yarn、Mesos、Docker、Kubernetes、AWS。
这里主要对Standalone模式和Yarn模式下的Flink集群部署进行分析。
2.1 Standalone模式安装
(1)软件要求
Java 1.8.x或更高版本
ssh(必须运行sshd才能使用管理远程组件的Flink脚本)
集群部署规划:
| 节点名称 | master | worker | zookeeper |
|---|---|---|---|
| bigdata11 | master | zookeeper | |
| bigdata12 | master | worker | zookeeper |
| bigdata13 | worker | zookeeper |
(2)解压
tar -zxvf flink-1.6.1-bin-hadoop28-scala_2.11.tgz -C /opt/module/
(3)修改配置文件
修改flink/conf/masters,slaves,flink-conf.yaml
[root@bigdata11 conf]$ sudo vi masters
bigdata11:8081
[root@bigdata11 conf]$ sudo vi slaves
bigdata12
bigdata13
[root@bigdata11 conf]$ sudo vi flink-conf.yaml
taskmanager.numberOfTaskSlots:2 //52行
jobmanager.rpc.address: bigdata11 //33行
可选配置:
•每个JobManager(jobmanager.heap.mb)的可用内存量,
•每个TaskManager(taskmanager.heap.mb)的可用内存量,
•每台机器的可用CPU数量(taskmanager.numberOfTaskSlots),
•集群中的CPU总数(parallelism.default)和
•临时目录(taskmanager.tmp.dirs)
(4)拷贝安装包到各节点
[root@bigdata11 module]$ scp -r flink-1.6.1/ root@bigdata12:/opt/module
[root@bigdata11 module]$ scp -r flink-1.6.1/ root@bigdata13:/opt/module
(5)配置环境变量
配置所有节点Flink的环境变量:
[root@bigdata11 flink-1.6.1]$ vi /etc/profile
//添加以下配置
export FLINK_HOME=/opt/module/flink-1.6.1
export PATH=$PATH:$FLINK_HOME/bin
//source一下,使其生效
[root@bigdata11 flink-1.6.1]$ source /etc/profile
(6)启动flink
[itstar@bigdata11 flink-1.6.1]$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host bigdata11.
Starting taskexecutor daemon on host bigdata12.
Starting taskexecutor daemon on host bigdata13.

(7)Web界面查看
在浏览器输入:http://bigdata11:8081

(8)运行测试
[itstar@bigdata11 flink-1.6.1]$ bin/flink run -m bigdata11:8081
./examples/batch/WordCount.jar --input /opt/module/datas/word.txt

(9)Flink 的 HA
首先,我们需要知道 Flink 有两种部署的模式,分别是 Standalone 以及 Yarn Cluster 模式。
对于 Standalone 来说,Flink 必须依赖于 Zookeeper 来实现 JobManager 的 HA(Zookeeper 已经成为了大部分开源框架 HA 必不可少的模块)。在 Zookeeper 的帮助下,一个 Standalone 的 Flink 集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于 Standby 状态。当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选举新的 JobManager 来接管 Flink 集群。
对于 Yarn Cluaster 模式来说,Flink 依靠 Yarn 本身来对 JobManager 做 HA 。其实这里完全是 Yarn 的机制。对于 Yarn Cluster 模式来说,JobManager 和 TaskManager 都是被 Yarn 启动在 Yarn 的 Container 中。此时的 JobManager,其实应该称之为 Flink Application Master。也就说它的故障恢复,就完全依靠着 Yarn 中的 ResourceManager(和 MapReduce 的 AppMaster 一样)。由于完全依赖了 Yarn,因此不同版本的 Yarn 可能会有细微的差异。这里不再做深究。
1)修改配置文件
修改flink-conf.yaml,HA模式下,jobmanager不需要指定,在master file中配置,由zookeeper选出leader与standby。
#jobmanager.rpc.address: bigdata11
high-availability: zookeeper //73行
#指定高可用模式(必须) //88行
high-availability.zookeeper.quorum:bigdata11:2181,bigdata12:2181,bigdata13:2181
#ZooKeeper仲裁是ZooKeeper服务器的复制组,它提供分布式协调服务(必须) //82行
high-availability.storageDir: hdfs:///flink/ha/
#JobManager元数据保存在文件系统storageDir中,只有指向此状态的指针存储在ZooKeeper中(必须) //没有
high-availability.zookeeper.path.root: /flink
#根ZooKeeper节点,在该节点下放置所有集群节点(推荐) //没有
high-availability.cluster-id:/flinkCluster
#自定义集群(推荐)
state.backend: filesystem
state.checkpoints.dir: hdfs:///flink/checkpoints
state.savepoints.dir: hdfs:///flink/checkpoints
修改conf/zoo.cfg
server.1=bigdata11:2888:3888
server.2=bigdata12:2888:3888
server.3=bigdata13:2888:3888
修改conf/masters
bigdata11:8081
bigdata12:8081
修改slaves
bigdata12
bigdata13
同步配置文件conf到各个节点
2)启动HA
先启动zookeeper集群各节点(测试环境中也可以用Flink自带的start-zookeeper-quorum.sh),启动dfs ,再启动flink
[itstar@bigdata11 flink-1.6.1]$ bin/start-cluster.sh
Web界面查看,这是会自动产生一个主Master,如下:

3)验证HA
手动杀死bigdata12上的master,此时,bigdata11上的备用master转为主mater。
4)手动将JobManager / TaskManager实例添加到群集
可以使用bin/jobmanager.sh和bin/taskmanager.sh脚本将JobManager和TaskManager实例添加到正在运行的集群中。
添加JobManager:
bin/jobmanager.sh ((start|start-foreground) [host] [webui-port])|stop|stop-all
添加TaskManager:
bin/taskmanager.sh start|start-foreground|stop|stop-all
[itstar@bigdata12 flink-1.6.1]$ jobmanager.sh start bigdata12
新添加的为从master节点
2.2 Yarn模式安装
1、在官网下载1.6.1版本Flink(https://archive.apache.org/dist/flink/flink-1.6.1/)。
2、将安装包上传到要按照JobManager的节点(bigdata11)。
3、进入Linux系统对安装包进行解压:(同上)
4、修改安装目录下conf文件夹内的flink-conf.yaml配置文件,指定JobManager:(同上)
5、修改安装目录下conf文件夹内的slave配置文件,指定TaskManager:(同上)
6、将配置好的Flink目录分发给其他的两台节点:(同上)
(1)明确虚拟机中已经设置好了环境变量HADOOP_HOME
(2)启动Hadoop集群(HDFS和Yarn)
(3)在bigdata11节点提交Yarn-Session,使用安装目录下bin目录中的yarn-session.sh脚本进行提交:
在yarn-site.xml文件中加入以下配置:
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>5</value>
</property>
执行命令:
/opt/module/flink-1.6.1/bin/yarn-session.sh -n 2 -s 4 -jm 1024 -tm 1024 -nm test -d
解释:
-n(--container):TaskManager的数量。
-s(--slots):每个TaskManager的slot数量,默认一个slot一个core,
默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
-jm:JobManager的内存(单位MB)。
-tm:每个taskmanager的内存(单位MB)。
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行
(4)启动后查看Yarn的Web页面,可以看到刚才提交的会话:

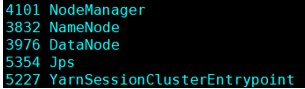
(5)在提交Session的节点查看进程:
(6)提交Jar到集群运行:
/opt/module/flink-1.6.1/bin/flink run -m yarn-cluster examples/batch/WordCount.jar
(7)提交后在Yarn的Web页面查看任务运行情况:

(8)任务运行结束后在控制台打印如下输出: