TCP是可靠的传输层协议,但这并不意味着一端发送的数据一定可以到达另一端,因为传输过程中遇到的情况是不可控的,很有可能就有某些数据发生丢失,所以”可靠”其实并不可靠。
不过毕竟现如今的网络设备还算完善,传输过程中由于硬件错误导致数据丢失的情况基本可以忽略,那么,数据丢失的原因就只能是:传输路径过于拥堵,导致某些路由器或链路缓冲区无法再容纳多余数据,那么对于新来的数据包就只能丢掉。
为了解决这一问题,保证就算传输过程中遇到再多麻烦,也尽量使数据可以顺利到达对端,TCP引入拥塞控制用于缓解网络中的拥堵情况,同时采用超时重传机制解决数据的丢失问题
超时重传机制
超时重传机制主要是为了解决数据包在传输过程中丢失的问题,在上一篇关于TCP流量控制的介绍中已经简单接触过超时重传的概念。TCP每发送一个报文段,就会为这个报文段开启一个定时器,如果定时器溢出时仍然没有收到接收端的应答报文,那么TCP就认为这个报文段在传输过程中丢失,然后重新发送这个报文段。这便是超时重传机制
以<TCP/IP详解>中的例子为例,通过tcpdump抓包分析观察TCP的重传
首先和远方的某个服务器进行连接,发送一些数据以确认连接正常,随后拔掉本机以太网电缆,发送另一条数据

tcpdump的输出结果为
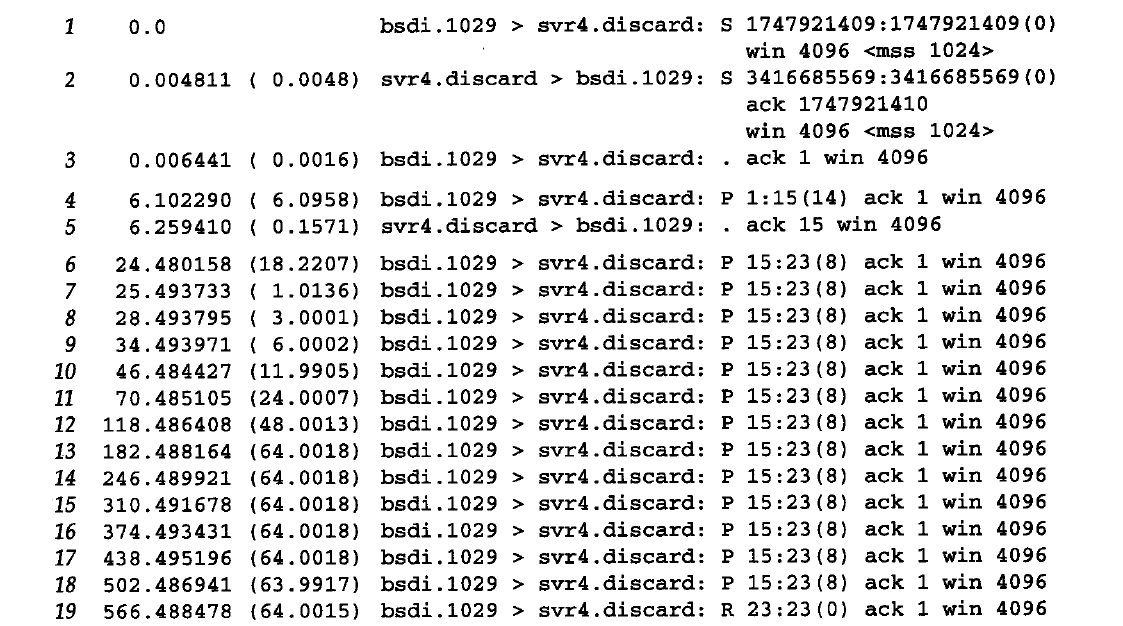
可以看到,前三行表示TCP的三次握手,四五行分别表示发送的”hello world”报文段以及应答报文段,随后的若干行表示TCP多次尝试重新发送”and hi”报文段,最后一行发送复位报文段,终止连接
本质上就是当第一次发送”and hi”报文段时启动了定时器,然而在规定的时间内没有收到对端的回复,所以重新发送”and hi”报文段,并重启定时器(重启的定时器时间会增大)
拥塞控制
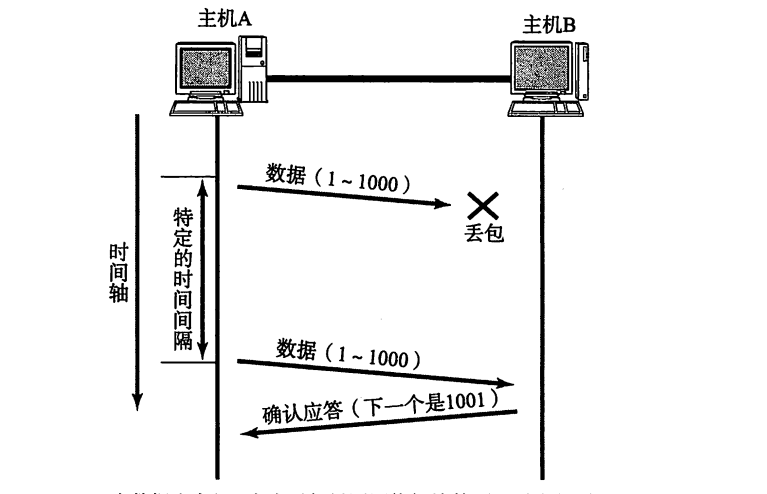
超时重传是为了解决数据丢失的问题,而数据丢失的原因很大程序上是由于传输路径拥塞导致的。在正常的传输过程中,数据是从一个路由器跳到下一个路由器,每个路由器都有自己的缓冲区,新来的数据会存放在缓冲区中,与此同时路由器也在不断地将缓冲区中的数据发送给下一个路由器。但是如果某个路由器接收数据的速率大于发送数据的速率,就会导致缓冲区数据累积,最终填满缓冲区。此时如果再有数据到来,缓冲区已经无法容纳它们,只能将它们丢掉,造成数据丢失
这就是所谓的拥塞现象,本质就是传输路径上的节点不平衡。为了解决这一问题,就需要当出现拥塞现象时立即减少发送端发送的数据量,为路径上的某些节点提供清空缓冲区的时间,同时也避免了不必要的重传。
但是,发送端如何才能得知网络中发生了拥塞呢。因为由于硬件错误造成的数据丢失是很罕见的,所以发送端假定,如果出现了数据丢失,那么就可以认定发生了拥塞。TCP提供了若干缓解拥塞的算法,如
- 慢启动算法
- 拥塞避免算法
- 快速重传算法
- 快速恢复算法
下面会分别介绍这几种算法
由上一篇内容可知,TCP有一个叫做流量控制的机制,它与拥塞控制非常相似,但是仍然有一些差异
- 流量控制是端对端的控制机制,两端各自通知对方允许的窗口大小以防止对端发送过多数据导致自己来不及处理造成接收缓冲区被填满
- 拥塞控制不是端对端的控制机制,它是为了缓解从一端到另一端这条路径上的拥堵问题
不过二者都是通过限制发送方发送的数据包个数来解决问题,所以上述算法无非就是降低发送端发送速率,缓解网络压力
慢启动
慢启动算法的核心思想是当连接刚建立时允许发送的报文段个数很少,随后不断增加允许发送的报文段个数直到规定的阀值
慢启动为发送方TCP提供了另一个窗口:拥塞窗口,记为cwnd。在对滑动窗口的介绍中得知,发送方滑动窗口不能大于对端允许的窗口大小(称为通知窗口)。通过通知窗口,发送方可以得知接收方可以接收的数据个数,从而根据这个大小设置自己的滑动窗大小。
有了拥塞窗口的限制,发送方的滑动窗口大小就不能大于拥塞窗口和通知窗口的最小值(多数情况是等于最小值),TCP就会根据这个最小值发送数据。拥塞窗口在连接建立时被初始化为1个报文段,此后每接收到一个应答报文,就将拥塞窗口增加,直到增加到慢启动阀值
拥塞窗口增加的规则是增加对端接收的报文段数。
比如发送方连续发送两个报文段,然后两个应答报文段先后被发给发送方,那么拥塞窗口会先后执行两次加一。然而如果对端将这两个应答合并成一个应答报文段发回发送端,由于对端一次应答了两个报文段,那么拥塞窗口就直接加二
根据应答报文段中对端希望下次接收的序列号和发送端滑动窗口的左边界序列号,可以计算出对端接收的报文段数。
另外,为了表示方便,拥塞窗口的单位是报文段,一个报文段中可能有多个字节数据。而通知窗口的单位是字节数,也就是序列号数。注意区分
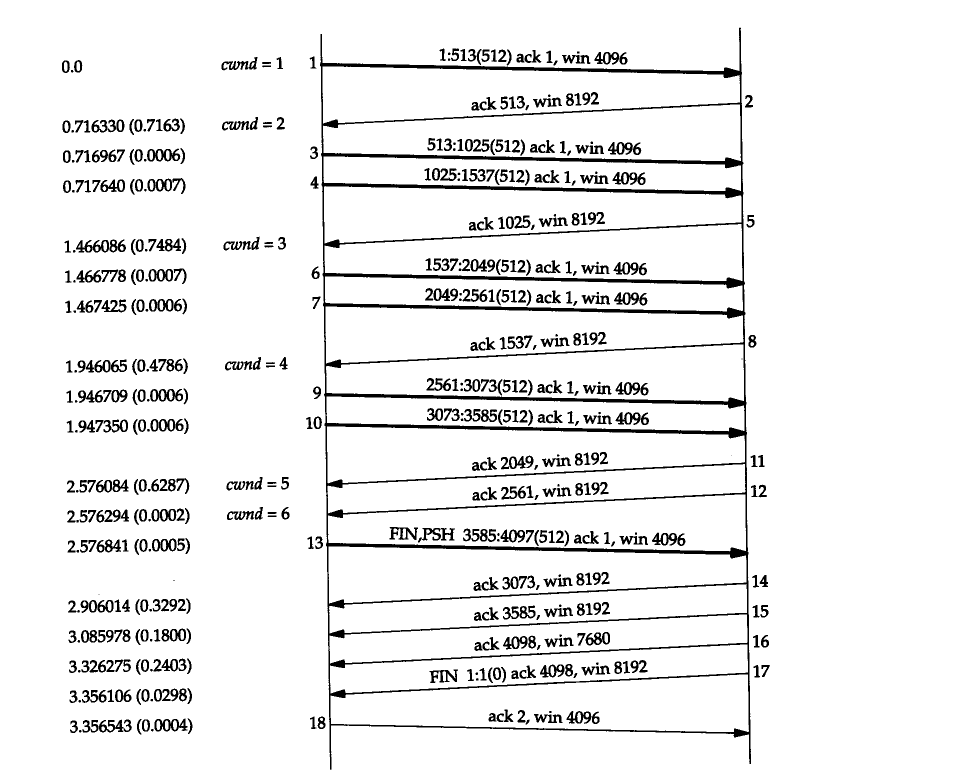
上图展现了慢启动算法过程中拥塞窗口大小的变化情况,拥塞窗口初始为1个报文段,所以TCP一次只能发送一个报文段
当TCP将这一个数据发送并得到对端应答后,拥塞窗口加一变为2。此时可以发送两个报文段,然后接收到其中一个报文段的应答报文段,拥塞窗口加一变为3。此时拥塞窗口为3,由于存在一个已经发送但是没有收到应答报文段,此时还允许发送两个报文段,所以接下来TCP连续发送了两个报文段,如此往复
当然,TCP不能放任拥塞窗口这么疯长下去,所以设置了一个阀值,当拥塞窗口增长到这个阀值时,慢启动算法就结束了,随后会执行拥塞避免算法
拥塞避免算法
拥塞避免算法是当拥塞窗口增长到一定程度时采取的一种算法,该算法的核心思想是减缓拥塞窗口的增加速度,每接收到一个应答就将拥塞窗口加一
注意拥塞避免算法和慢启动算法对于拥塞窗口的增加是有区别的。当对端将多个应答合并成一个应答报文发送时(由于延迟ACK,通常都会合并发送),慢启动算法会将拥塞窗口增加多个报文段数而拥塞避免算法只加一个
慢启动算法和拥塞避免算法通常配合使用,二者需要TCP发送端维护一个拥塞窗口cwnd和一个慢启动门限ssthresh(阀值),算法工作过程为
- 对一个给定的连接,初始拥塞窗口为1个报文段,同时设置慢启动门限为65536字节
- TCP输出例程的输出不能超过拥塞窗口和通知窗口的大小(二者的最小值是滑动窗口的最大值)
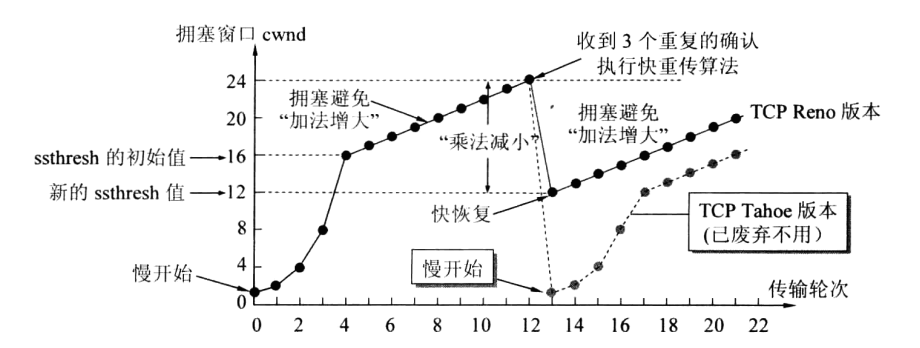
- 执行慢启动算法,拥塞窗口呈指数增长,当增长到慢启动门限时改为拥塞避免算法,使得拥塞窗口呈线性加法增长
- 当拥塞发生时,将慢启动门限ssthresh改为当前窗口的一半,但不能小于2个报文段(当前窗口指的是滑动窗口),然后将拥塞窗口设置为1一个报文段,重新开始慢启动算法
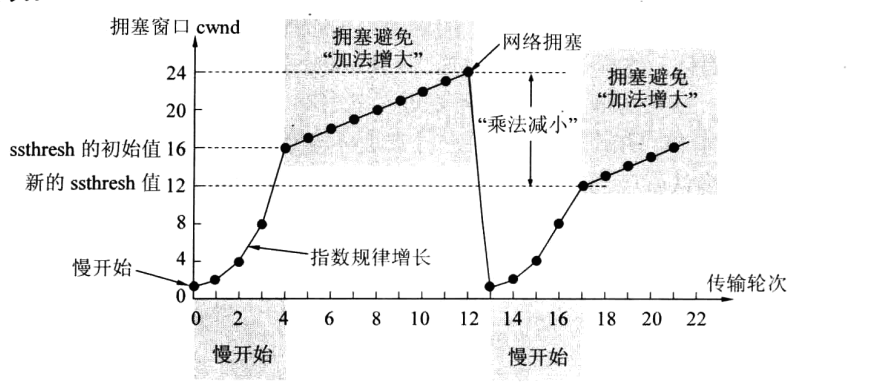
图中慢开始指的就是慢启动算法
由图片可以看到,当发生拥塞时拥塞窗口立即降为1个报文段大小,使得发送方可以发送的报文段数量急剧下降,这就为传输路径上的节点清空缓冲区提供了时间。此外由于已经发生了拥塞,证明网络条件并不是很好,所以拥塞窗口要增长的慢些,将慢启动门限降为一半便是这个目的
快速重传算法
前面介绍到当数据超时定时器溢出时,发送端便得知有数据丢失,从而认为网络中发生了拥塞。有什么其他方法可以确定数据丢失呢
考虑这样一种情况,发送端在发送若干报文段后连续发送了多个报文段[1001:2000],[2001:3000],[3001:4000]…,但是只有后几个报文段成功到达对端,由于对端希望接收的序列号是1001,所以接收端发送给发送端的所有应答报文段中携带的序列号仍然都是1001。
快速重传算法的核心思想就是当发送端接收到了三个相同的应答报文(携带的希望下次接收的序列号相同)时,就假设以该序列号结尾的那个报文段丢失,所以发送端不必等到定时器溢出就会重传丢失的报文段
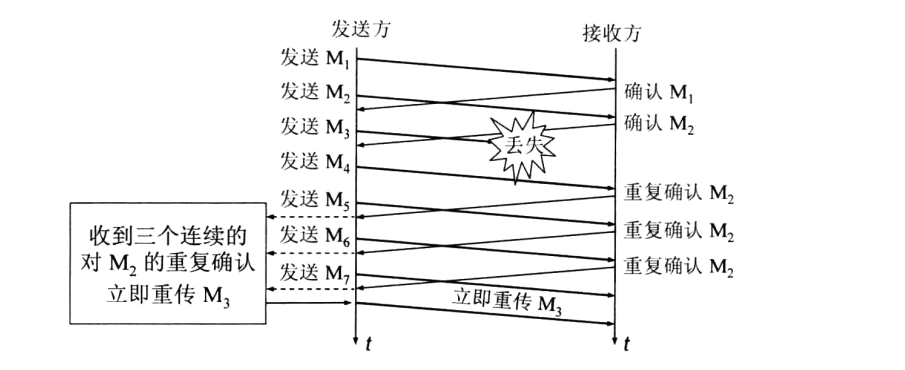
快速恢复算法
快速重传算法仅仅是为了尽早发现丢失报文段并重传,并不能确定网络发生拥塞(如果发生严重的拥塞,就不会一连有好几个报文段到达接收端,也就不会一连收到接收端发来的好几个重复应答报文段),所以不会执行慢启动算法将拥塞窗口降为1
快速重传法和快速恢复法的执行过程如下
- 当发送方连续收到三个重复应答报文时,就将慢启动门限ssthresh减半
- 将拥塞窗口降为减半后的ssthresh值+三个报文段
- 开始执行拥塞避免算法,缓慢增加拥塞窗口
加三个报文段的原因是发送端目前可以确定接收方已经接收到三个报文段(通过接收到三个重复应答报文得知),所以可以确定这三个报文段没有滞留在传输路径上,也就没有加重网络负担,所以可以加上三个报文段大小
在旧版的快速重传算法中还是使用慢启动,但是正如上面所述,网络很可能没有发生拥塞,所以在修正后的版本中使用快速恢复算法
重新分组
现考虑一种情况,发送端连续发送M1,M2,M3三个报文段,但只有M1顺利到达而M2和M3都在传输过程中丢失。如果按正常的流程,发送端TCP会先后重传M2和M3两个报文段。
但是从节省报文段数量的角度思考,如果将M2和M3合并成一个新的报文段进行重传,就能够减少传输过程中的报文段数量,在某种程度上也减轻了网络负担
由于TCP数据都是基于序列号的,每个数据都有唯一的序列号,所以可以将两段数据合成一段
再次使用<TCP/IP详解>中的例子,示例中首先发送一个报文段确认连接正常,然后断开以太网电缆并发送两个报文段(由于网络连接中断,这两个报文段必将重传),最后插上以太网电缆

观察tcpdump输出结果
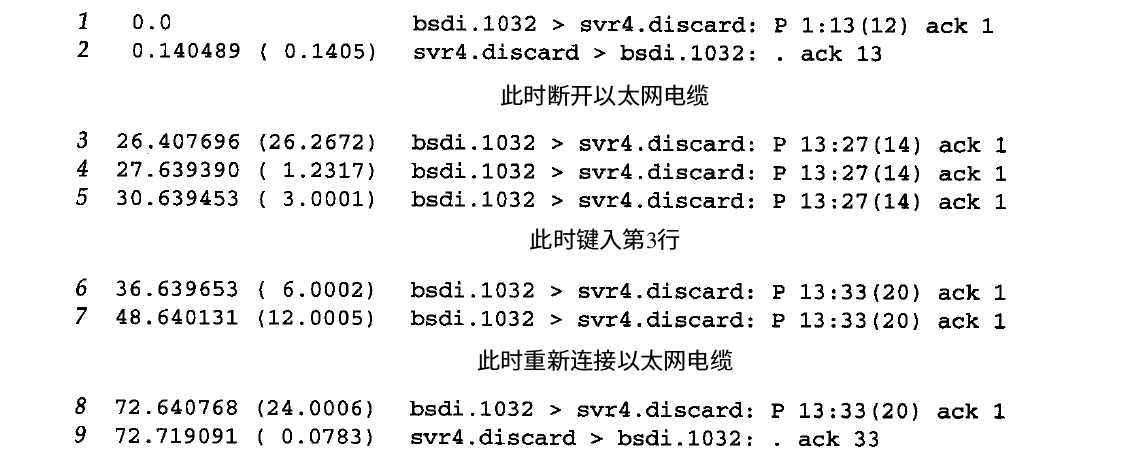
从图中可以看到发送”line number 2”报文段时由于网络原因进行了两次重传,随后键入”and 3”尝试发送,发现TCP将这两个报文段合并成一个进行发送(从图中数据个数为20得知)