一、数据库一主一从环境搭建
1.首先打开服务管理器,找到mysql服务。

右击属性查看mysql服务的磁盘位置
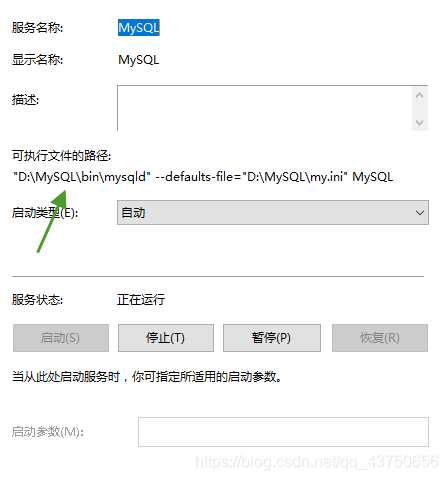
找到D磁盘上的mysql文件夹,复制一份mysql-slave当做从机

进入mysql-slave的data文件夹,修改my.ini文件
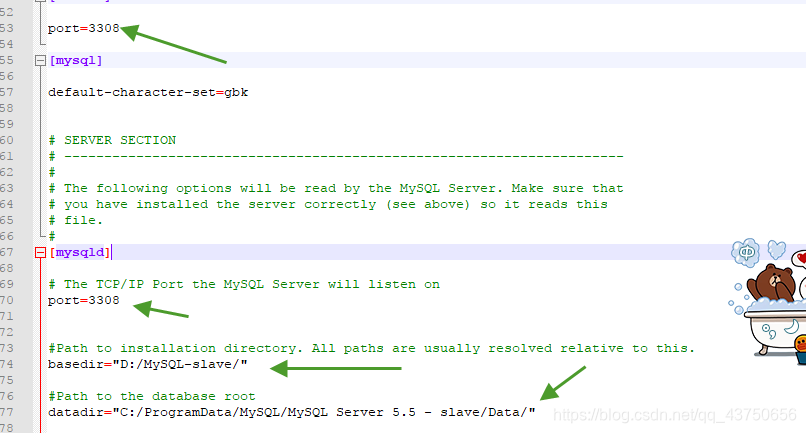
修改四个地方,端口,slave服务的磁盘位置,以及slave服务的数据库的磁盘位置,按照datadir="C:/ProgramData/MySQL/MySQL Server 5.5 - slave/Data/"的路径在相应目录复制一份数据库。
这样的话在C:\ProgramData\MySQL目录下
就有了两个数据库,一个为主机、一个为从机
2.注册新复制的mysql服务
进入新复制的slave服务的bin目录下,执行如下命令
mysqld install mysqls1 --defaults-file="D:\MySQL-slave\my.ini"
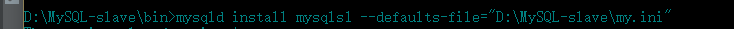
这样在服务管理器中就有了两个服务

3.修改两台服务器的配置文件
(1)主服务器的配置文件
修改D:\MySQL\my.ini文件,在文件末尾添加以下配置
[mysqld]
#开启日志
log-bin=mysql-bin
#设置服务id,主从两台服务器不能一致
server_id=1
#设置需要同步的数据库
binlog-do-db=user_db
#屏蔽系统库同步
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
(2)从服务器的配置文件
修改D:\MySQL-slave\my.ini文件,在文件末尾添加以下配置
[mysqld]
#开启日志
log-bin=mysql-bin
#设置服务id,主从不能一致
server_id=2
#设置需要同步的数据库
replicate_wild_do_table=user_db.%
#屏蔽系统库同步
replicate_wild_ignore_table=mysql.%
replicate_wild_ignore_table=information_schema.%
replicate_wild_ignore_table=performance_schema.%
(3)重启两个服务(mysql和mysqls1)。
(4)用cmd方式登录主服务器
由于我们配置了两个mysql服务所以登录的时候我们将端口指定一下,3306为主服务器端口。
mysql -uroot -proot -P 3306
登录以后为从服务器专门创建一个账号
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY 'slave';
#刷新权限
FLUSH PRIVILEGES;
最后执行 show master status; 获取日志文件以及接入点信息

(5)用cmd方式登录从服务器
mysql -uroot -p19981009 -P 3308
先执行如下命令,让从机停止slave功能,然后重设master
STOP SLAVE;
RESET MASTER;
执行最重要一步
CHANGE MASTER TO
master_host = 'localhost',
master_user = 'slave',
master_password = 'slave',
master_log_file = 'mysql-bin.000002',
master_log_pos = 107;

然后执行start slave;开启复制功能
查看从机状态show slave status\G;
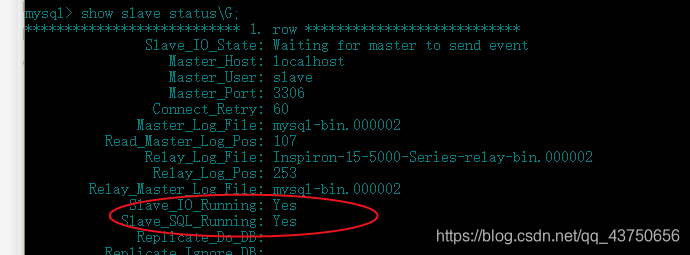
当这两项成为YES的时候代表一主一从的环境搭建成功。
二、主从复制原理
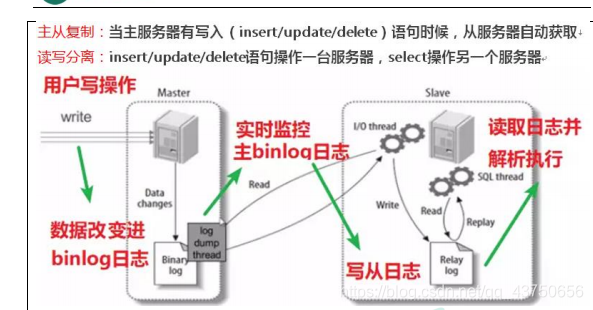
也就是所有的增删改请求发送给主服务器,所有的读请求发送给从服务器。主服务器通过开启binlog日志功能,可以让从服务器实时监控该日志,当主服务器发生写请求时,从服务器会读取该日志并解析,从而实现数据同步。
三、代码实现
1.数据库设计
在user_db库中创建t_user_info表
use user_db;
CREATE TABLE `t_user_info` (
`id` bigint(30) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`gender` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.创建实体类和mapper
(项目的环境搭建是基于上一篇的,可以参考这里SpringBoot集成Sharding-JDBC实现分库分表)
@Data
@TableName("t_user_info")
public class UserInfo {
private Long id;
private String name;
private String gender;
}
public interface UserInfoMapper extends BaseMapper<UserInfo> {
}
3.配置application.properties
spring.shardingsphere.datasource.names=m1,s1
#配置m1这个数据源,由于这里是水平分表,所以只需要一个数据源即可 其中m1代表该数据源的一个标识
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
#指定链接驱动
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
#指定链接url
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/user_db?useSSL=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC
#指定链接用户名
spring.shardingsphere.datasource.m1.username=root
#指定链接密码
spring.shardingsphere.datasource.m1.password=root
#配置s1这个数据源,由于这里是水平分表,所以只需要一个数据源即可 其中s1代表该数据源的一个标识
spring.shardingsphere.datasource.s1.type=com.alibaba.druid.pool.DruidDataSource
#指定链接驱动
spring.shardingsphere.datasource.s1.driver-class-name=com.mysql.cj.jdbc.Driver
#指定链接url
spring.shardingsphere.datasource.s1.url=jdbc:mysql://localhost:3308/user_db?useSSL=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC
#指定链接用户名
spring.shardingsphere.datasource.s1.username=root
#指定链接密码
spring.shardingsphere.datasource.s1.password=root
# 指定主服务器的数据源
spring.shardingsphere.sharding.master-slave-rules.ds.master-data-source-name=m1
#指定从服务器的数据源
spring.shardingsphere.sharding.master-slave-rules.ds.slave-data-source-names=s1
# 配置 实现读写分离的表
spring.shardingsphere.sharding.tables.t_user_info.actual-data-nodes=ds.t_user_info
#开启sql 输出日志
spring.shardingsphere.props.sql.show=true
# 由于一个实体类对应两张表,所以会产生覆盖操作,加上这个配置解决覆盖问题
spring.main.allow-bean-definition-overriding=true
4.编写测试代码
@Test
public void testSeparation(){
UserInfo userInfo = new UserInfo();
userInfo.setGender("0");
userInfo.setName("谢广坤");
userInfoMapper.insert(userInfo);
}
日志查看:

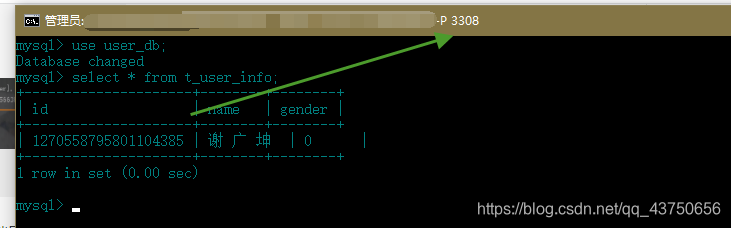
可以看到这条插入的sql是向m1数据源也就是3306端口发送的请求
再查看从机3308端口也自动复制了该条数据。
5.测试读请求
@Test
public void testSeparationRead(){
userInfoMapper.selectById(1270558795801104385L);
}
日志查看:

可以发现select请求是发给的s1数据源。至此,一主一从的读写分离已完成实现。