Sqoop简介
Sqoop旨在协助RDBMS与Hadoop之间进行高效的大数据交流。可以把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。
Sqoop是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,结构化数据可以是MySQL、Oracle等RDBMS。Sqoop底层用MapReduce程序实现抽取、转换、加载,MapReduce天生的特性保证了并行化和高容错率。
如果要用Sqoop,必须正确安装并配置Hadoop,因依赖于本地的Hadoop环境启动MR程序;MySQL、Oracle等数据库的JDBC驱动也要放到Sqoop的lib目录下。
Sqoop架构
Sqoop1和Sqoop2的对比
Sqoop1架构

Sqoop2架构
对比分析
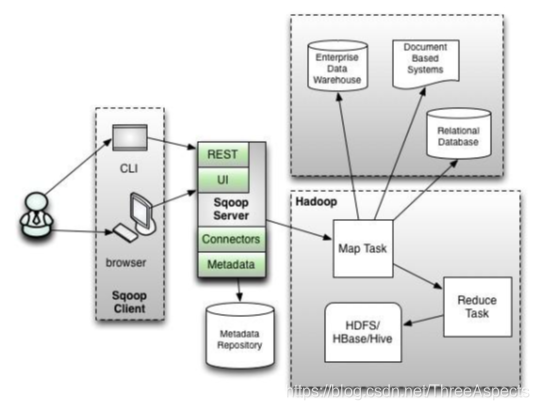
① 在架构上,Sqoop1仅仅使用一个Sqoop客户端;Sqoop2引入了Sqoop Server,对Connector实现了集中的管理,其访问方式也变得多样化了,其可以通过REST API、JAVA API、WEB UI以及CLI控制台方式进行访问。
② 在安全性能方面,在Sqoop1中我们经常用脚本的方式将HDFS中的数据导入到MySQL中,或者反过来将MySQL数据导入到HDFS中,其中在脚本里边都要显示指定MySQL数据库的用户名和密码的,安全性做的不是太完善。在Sqoop2中,如果是通过CLI方式访问的话,会有一个交互过程界面,你输入的密码信息不被看到,同时Sqoop2引入基于角色的安全机制。
优缺点
① Sqoop1优点:架构部署简单
② Sqoop1缺点:命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏,安装需要root权限,connector必须符合JDBC模型
③ Sqoop2优点:多种交互方式,命令行,Web UI,REST API,Conncetor集中化管理,所有的链接安装在Sqoop Server上,完善权限管理机制,Connector规范化,仅仅负责数据的读写
④ Sqoop2缺点:架构稍复杂,配置部署更繁琐
Sqoop导入底层工作原理
将数据从关系型数据库导入到Hadoop中
Step1:Sqoop与数据库Server通信,获取数据库表的元数据信息
Step2:Sqoop启动一个Map-Only的MR作业,利用元数据信息并行将数据写入Hadoop
Sqoop在import时,需要制定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。每个map中再处理数据库中获取的一行一行的值,写入到HDFS中。同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。 比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-100),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。

大概流程
- 读取要导入数据的表结构,生成运行类,默认是QueryResult,打成jar包,然后提交给Hadoop
- 设置好job,就由Hadoop来执行MapReduce来执行Import命令了,
1)首先要对数据进行切分,也就是DataSplit,DataDrivenDBInputFormat.getSplits(JobContext job)
2)切分好范围后,写入范围,以便读取DataDrivenDBInputFormat.write(DataOutput output),这里是lowerBoundQuery and upperBoundQuery
3)读取以上2)写入的范围DataDrivenDBInputFormat.readFields(DataInput input)
4)然后创建RecordReader从数据库中读取数据DataDrivenDBInputFormat.createRecordReader(InputSplit split,TaskAttemptContext context)
5)创建Map,TextImportMapper.setup(Context context)
6)RecordReader一行一行从关系型数据库中读取数据,设置好Map的Key和Value,交给MapDBRecordReader.nextKeyValue()
7)运行Map,mapTextImportMapper.map(LongWritable key, SqoopRecord val, Context context),最后生成的Key是行数据,由QueryResult生成,Value是NullWritable.get()
导入控制
Sqoop不需要每次都导入整张表。例如,可以指定导入表的部分列。用户也可以在查询中加入WHERE子句(使用—where参数),以此来限定需要导入的记录。
导入和一致性
在向HDFS导入数据时,重要的是要确保访问的是数据源的一致性快照。保证一致性的最好方法是在导入时不允许运行任何对表中现有数据进行更新的进程。
增量导入
定期运行导入时一种很常见的方式,这样做可以使HDFS的数据与数据库的数据保持同步。为此需要识别哪些是新数据。对于某一行来说,只有当特定列(由—check-column参数指定)的值大于指定值(通过—last-value设置)时,Sqoop才会导入该行数据。
直接模式导入:在Sqoop的文档中将使用外部工具的方法称为直接模式。
导入大对象:“内联”存储大对象,它们会严重影响扫描的性能。因此将大对象与它们的行分开存储。由于大对象单条记录太大,无法在内存中实现物化。为了克服这个困难,当导入大对象数据大于阈值16M时(通过sqoop.inline.lob.length.max设置,以字节为单位),Sqoop将导入的大对象存储在LobFile格式的单独文件中。LobFile格式能够存储非常大的单条记录(使用了64位的地址空间),每条记录保存一个大对象。LobFile格式允许客户端持有对记录的引用,而不访问记录内容,对记录的访问通过java.io.InputStream(用于二进制对象)或java.io.Reader(用于字符对象)来实现的。在导入一条记录时,所有的“正常”字段会在一个文本文件中一起被物化,同时还生成一个指向保存CLOB或BLOB列的LobFile文件的引用。
Sqoop导出底层工作原理
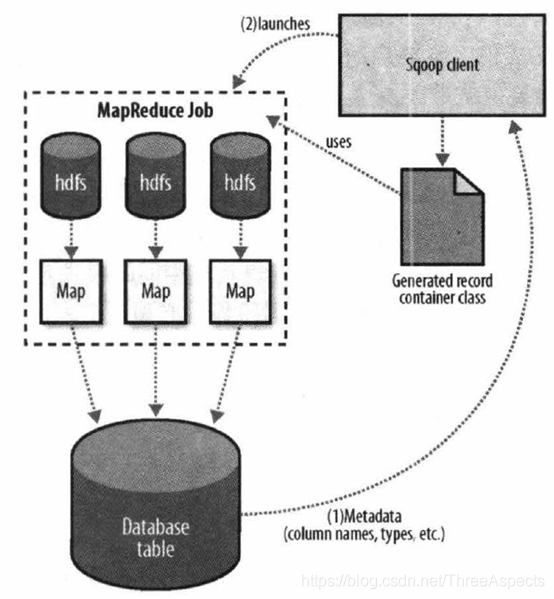
Sqoop在执行导出操作之前,Sqoop会根据数据库连接字符串来选择一个导出方法。一般为jdbc。然后,Sqoop会根据目标表的定义生成一个java类。这个生成的类能够从文本文件中解析记录,并能够向表中插入类型合适的值。接着会启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析记录,并且执行选定的导出方法。
基于jdbc的导出方法会产生一批insert语句,每条语句都会向目标表中插入多条记录。多个单独的线程被用于从HDFS读取数据并与数据库进行通信,以确保涉及不同系统的I/O操作能够尽可能重叠执行。
虽然HDFS读取数据的MapReduce作业大多根据所处理文件的数量和大小来选择并行度(Map任务的数量),但Sqoop的导出工具允许用户明确设定任务的数量。由于导出性能会受并行的数据库写入线程数量的影响,所以Sqoop使用CombineFileInput类将输入文件分组分配给少数几个Map任务去执行。