背景:最近做了个需求,为了优化效率所以做了本地缓存和redis缓存,这个跟实际问题没有很大关系,但在排查问题时造成了一定的干扰,导致排查时间变长了,这个问题的现象是上线后cpu急剧增高,fullgc次数比younggc次数多,而且每次fullgc回收的内存很少,fullgc频繁。
1.问题现象图:
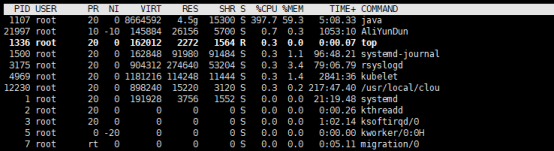
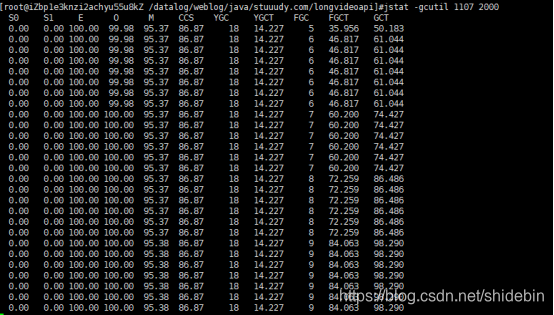
2.分析:通过gc的情况可以看出一直在进行fullgc而没有进行younggc,这种情况猜测是有大对象执行进入了老年代,而且在老年代回收时没有被回收掉,正好代码里也使用的本地缓存,在上之前是有计算本地缓存会占多大内存的,通过计算是不可能成为大对象,但出问题了也只能试试了,下面是解决问题的思路。
2.1把本地缓存减小,上一版之后观察了半小时没出问题,以为改好了,但过了一段时间又出现了。
2.2把本地缓存都去掉,上一台服务器之后观察了一下午没出问题,此时认为终于可以了,全量之后不久出问题。
2.3到此时就很头痛了,不知道从何下手,因为服务器的内存有14G,使用jmap命令dump下来文件过大,在本地分析不了内存情况,幸好此时同事提供一个命令:jmap -histo:live pid | head -n 100 // 查询前100个内存使用过高的java类,使用此命令一看才发现真正的问题所在:
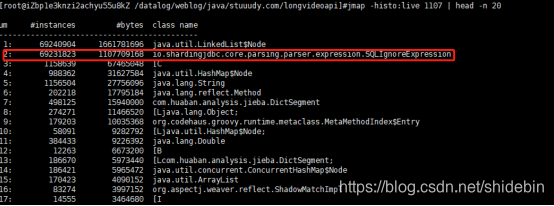
这个SQLIgnoreExpression说明sharingjdbc在执行sql报错了,在报错之后不停的在创建这个对象。然后再通过打印sql发现in里面有个空list。查看代码:
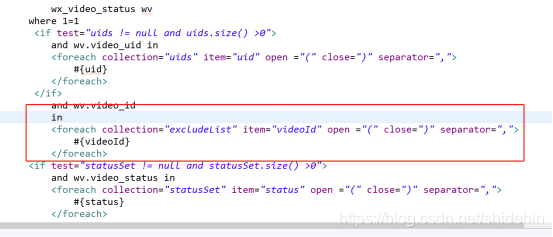
这个地方没有判空,这也算是sharingjdbc的一大坑,集合一定要判空,所以in操作都判空之后就没有问题了。
总结:通过此次事件发现jmap -dump:format=b,file=e.bin pid这个命令的局限性了,因为一般生产上的内存都挺大,dump下来本地根本就分析不了,感觉jmap -histo:live pid | head -n 100 // 查询前100个内存使用过高的java类这个命令还是挺好使的,可以快速的找个大对象。
记录一次sharingjdbc引起的fullgc频繁问题,总结一下fullgc频繁解决的方案
猜你喜欢
转载自blog.csdn.net/shidebin/article/details/106358993
今日推荐
周排行