现在爱豆都靠直拍圈粉,直拍越炫酷,就越能圈粉,怎么把视频加个我们自己想要的风格滤镜,用AE?找个会剪辑视频的?

作为一个工具人,想着能不能创造一个工具,通过我上传一张图片,比如一下面这张图片属于国画风格

然后上传我需要加这个风格滤镜的视频,比如安崎小甜心的主题曲直拍视频,然后把这个视频搞上面的国画风格

前面看过我前几章的朋友,可能知道我之前就在倒腾PaddleHub,不熟悉的朋友朋友指路:
各位集美兄得看过来! 利用AI给青春有你2的选手们做数据分析挖掘(一):爬虫选手信息
各位集美兄得看过来! 利用AI给青春有你2的选手们做数据分析挖掘(二):统计并展示数据
各位集美兄得看过来! 利用AI给青春有你2的选手们做数据分析挖掘(三):看图像识选手
各位集美兄得看过来! 利用AI给青春有你2的选手们做数据分析挖掘(四):AI分析谁最容易出道
回到正题,如何实现我上面说的将视频风格转成一张图片的风格,PaddleHub提供了一个有趣的模型
stylepro_artistic
风格迁移模型介绍
艺术风格迁移模型可以将给定的图像转换为任意的艺术风格。本模型StyleProNet整体采用全卷积神经网络架构(FCNs),通过encoder-decoder重建艺术风格图片。StyleProNet的核心是无参数化的内容-风格融合算法Style Projection,模型规模小,响应速度快。模型训练的损失函数包含style loss、content perceptual loss以及content KL loss,确保模型高保真还原内容图片的语义细节信息与风格图片的风格信息。预训练数据集采用MS-COCO数据集作为内容端图像,WikiArt数据集作为风格端图像。
具体原理图:
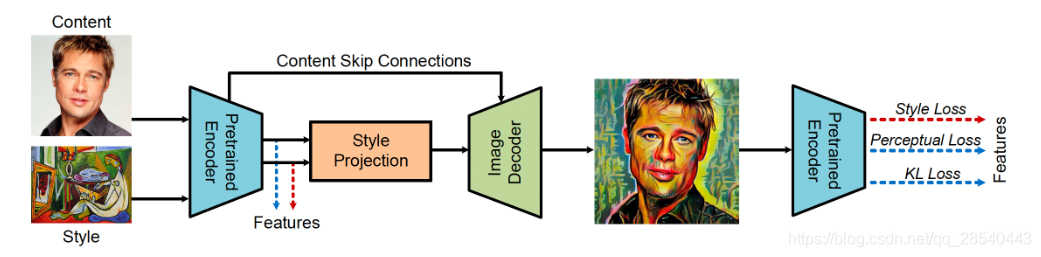
利用这个模型就能实现我们视频风格迁移了。是不是很牛逼?
效果视频提前披露
效果绝了!

还有帅气的

具体思路
实现视频风格迁移的具体思路如下:
- 将视频逐帧读取成图片;
- 处理图片干扰数据,比如灯光之类的;
- 调用
stylepro_artistic模型实现风格迁移 - 重新将图片合成视频
- 将原视频的音频输出并整合到新视频
全程只使用python代码编写,不需要借助外部视频编辑工具
环境准备
下载相关库,这里需要使用paddlepaddle最新版,得upgrade一下。
pip install --upgrade paddlepaddle
pip install --upgrade paddlehub
#相关库的导入
import os
import cv2
import paddlehub as hub
from moviepy.editor import *
from matplotlib import pyplot as plt
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from PIL import ImageFont, ImageDraw, Image
import requests
下载模型
终端输入以下命令
hub install stylepro_artistic
hub install deeplabv3p_xception65_humanseg
引入模型
stylepro_artistic = hub.Module(name="stylepro_artistic")
humanseg = hub.Module(name="deeplabv3p_xception65_humanseg")
处理视频
处理视频主要实现将视频逐帧读取成图片集合并存储
具体实现如下:
def CutVideo2Image(video_path, img_path):
"读取视频,获取每帧画面,输出为图片"
"video_path:输入视频路径"
"img_path:输出图片路径"
cap = cv2.VideoCapture(video_path)
index = 0
global size_y ,size_x
while(True):
ret,frame = cap.read()
if ret and index < 2000:
cv2.imwrite(img_path + '%d.jpg' % index, frame)
index += 1
else:
break
size_x = frame.shape[0]
size_y = frame.shape[1]
cap.release()
print('Video cut finish, all %d frame' % index)
print("imge size:x is {1},y is {0}".format(size_x,size_y))
去除图片干扰因素
喜欢背景的可以跳过这一步,主要我这边的视频灯光太强了,我需要抠图。
抠图主要使用deeplabv3p_xception65_humanseg模型
DeepLabv3+ 是Google DeepLab语义分割系列网络的最新作,其前作有 DeepLabv1,DeepLabv2, DeepLabv3。在最新作中,作者通过encoder-decoder进行多尺度信息的融合,同时保留了原来的空洞卷积和ASSP层, 其骨干网络使用了Xception模型,提高了语义分割的健壮性和运行速率,在 PASCAL VOC 2012 dataset取得新的state-of-art performance。该PaddleHub Module使用百度自建数据集进行训练,可用于人像分割,支持任意大小的图片输入。
import os
# 抠图
def delete_bg(path):
"抠图去除多余背景"
"path:需要抠图的图片目录"
img_list= [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.jpg')]
num=100 #定义每组包含的元素个数
for i in range(0,len(img_list),num):
humanseg.segmentation(data={"image":img_list[i:i+num]},output_dir='h_out/')
输出结果如下,这是一张png图片

png图片对于后面转视频处理不友好(就是不行的意思) ,因此我们得加个白底给他,这里涉及图象合成技术,图象合成代码实现如下:
,因此我们得加个白底给他,这里涉及图象合成技术,图象合成代码实现如下:
from PIL import Image
# 合成图片
## base_image_path:背景路径
## fore_image_path:前景路径
## save_path: 输出图片路径
## is_resize 是否大小统一
def composition_img(base_image_path,fore_image_path,save_path,is_resize):
base_image = Image.open(base_image_path).convert('RGB')
if is_resize== True:
fore_image = Image.open(fore_image_path).resize(base_image.size)
else:
fore_image = Image.open(fore_image_path)
# 图片加权合成
scope_map = np.array(fore_image)[:,:,-1] / 255
scope_map = scope_map[:,:,np.newaxis]
scope_map = np.repeat(scope_map, repeats=3, axis=2)#表示将矩阵沿着每个元素复制3次
res_image = np.multiply(scope_map, np.array(fore_image)[:,:,:3]) + np.multiply((1-scope_map), np.array(base_image))
#保存图片
res_image = Image.fromarray(np.uint8(res_image))
res_image.save(save_path)
添加白色背景转成JPG格式图片具体实现如下:
# 添加白色背景转成jpg
def add_white_bg(path,bgout_path,output_path):
num = os.listdir(path)
for i in range(0,len(num)-1):
img_black = np.zeros((size_x,size_y,3), np.uint8)
img_black.fill(255)
img_black_path =bgout_path + str(i) + ".jpg"
cv2.imwrite(img_black_path,img_black)
for i in range(0,len(num)-1):
# 合成图片
composition_img(img_black_path,path+str(i)+'.png',output_path+str(i)+'.jpg',True)
# add_white_bg('h_out/','data/img/bgout/','data/img/bgres/')
风格迁移
利用模型实现风格迁移,老简单了
客官且看
def change_style(img_list,output_dir):
"""
调用模型进行风格转换
img_list: 需要转换的图片对象集合
output_dir:图片输出目录
"""
print(img_list)
result = stylepro_artistic.style_transfer(
paths=img_list,
# use_gpu=True,
visualization=True,
output_dir=output_dir,
alpha=0.5
)
def get_img_list(frame_path):
"""
组装转换风格imglist
frame_path:需要转换风格的原图目录
"""
num = os.listdir(frame_path)
img_list=[]
for i in range(0,len(num)-1):
img_path =frame_path + str(i) + ".jpg"
img={}
styles=['work/style/timg3.jpg']
img['styles']=styles
img['content']=img_path
img_list.append(img)
return img_list
视频合成
将我们转换好风格的图片转成视频
def comp_video(comb_path):
"""
视频合成
comb_path: 合成图片所在目录
"""
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
video_tmp_name = comb_path.split("/")[2]
video_name = "video/" + str(video_tmp_name) + ".mp4"
files = os.listdir(comb_path)
out = cv2.VideoWriter(video_name,fourcc,30.0,(size_y, size_x))
# 排序
files = sorted(files, key=lambda x: os.path.getmtime(os.path.join(comb_path, x)))
print("一共有{}帧图片要合成".format(len(files)))
for i in range(len(files)):
img = cv2.imread(comb_path+files[i])
out.write(img) # 保存帧
out.release()
视频音频合成
将新生成的视频合成原视频的音频,使得视频更加完整
主要是通过提取原视频的音频,然后合并到video里面
具体实现
def getMusic(video_name):
"""
获取指定视频的音频
"""
# 读取视频文件
video = VideoFileClip(video_name)
# 返回音频
return video.audio
def addMusic(video_name, audio,output_video):
"""实现混流,给video_name添加音频"""
# 读取视频
video = VideoFileClip(video_name)
# 设置视频的音频
video = video.set_audio(audio)
# 保存新的视频文件
video.write_videofile(output_video)
调用方式
说好的超巨简单就超巨简单
# 算上我注释,加起来5行代码调用,简单不简单
if __name__ == "__main__":
change_style(get_img_list('work/aq/bgres/'),'work/aq/style_img/')
comp_video('work/aq/style_img/')
addMusic('video/style_img.mp4',getMusic('video/aq_base4.mp4'),'video/voice_frame2.mp4')

参考
https://www.paddlepaddle.org.cn/hubdetail
源码
https://github.com/llzz9595/qcyn
项目地址
https://aistudio.baidu.com/aistudio/projectdetail/449477