1.编写wordcount程序
package RDDTest
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object test03 {
def main(args: Array[String]): Unit = {
//构建SparkConf对象
val conf:SparkConf = new SparkConf().setAppName("wc").setMaster("spark://192.168.220.25:7077")
//构建上下文对象
val sc:SparkContext = new SparkContext(conf)
//读取文件
//这个args(0)表示获取从外部传入参数的第一个
val input:RDD[String] = sc.textFile(args(0))
//对该文件中的数据进行单词词频统计
val result:RDD[(String,Int)] = input.flatMap(_.split(" ")).map((_ ,1)).reduceByKey(_+_)
//将结果存储到文件中
//repartition(1)为了更直观的看到结果 这里将分区数设为 1
//这个args(1)表示获取从外部传入参数的第二个
result.repartition(1).saveAsTextFile(args(1))
//关闭连接
sc.stop()
}
}
2.将程序打包
点击package ,idea会开始自动打包

3.打包完成后会生成target目录,这个目录里就有我们需要的jar包

4.将jar包上传到集群

5.这个是hdfs上待统计单词文件的目录

6.将wordcount程序提交到spark集群上
注意:这里的输出目录output不需要自己创建,否则会报错。spark会自动创建
bin/spark-submit \
--class RDDTest.test03 \
--master spark://master:7077 \
./Spark-1.0-SNAPSHOT.jar \
hdfs://master:9000/spark/input/words.txt hdfs://master:9000/spark/output
7.等待程序运行完成

8.这里可用看到已经生成了结果文件
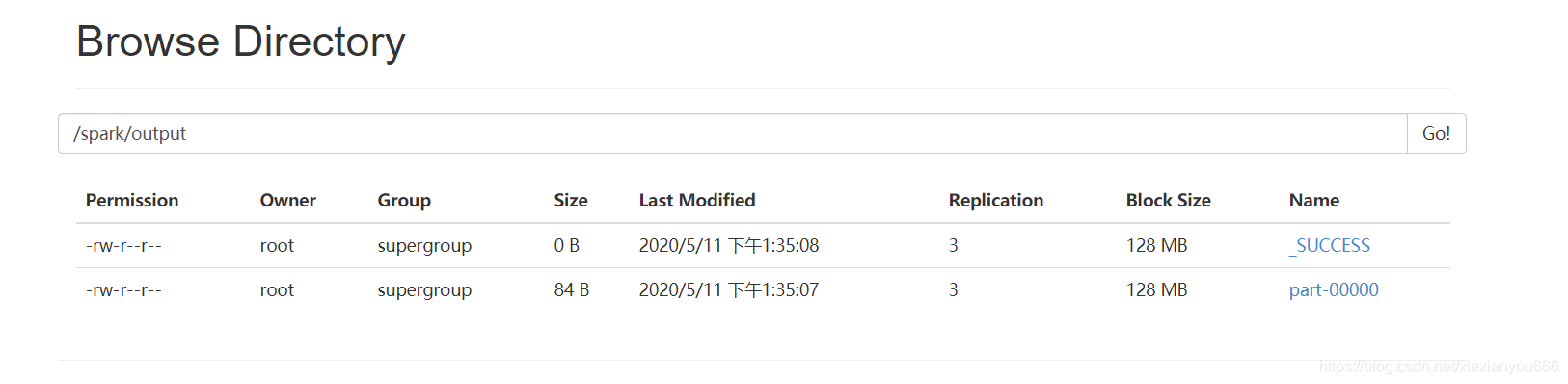
9.查看文件内容
