ImageNet
ImageNet是一个包含超过1 500万幅手工标记的高分辨率图像的数据库,大约有22 000个类别。该数据库组织类似于WordNet的层次结构,其中每个领域叫同义词集合。每个同义词集合都是ImageNet层次结构中的一个节点。每个节点都包含超过500幅图像。
ImageNet大规模视觉识别挑战赛(ILSVRC)成立于2010年,旨在提高大规模目标检测和图像分类的最新技术。
LeNet-5
介绍
卷积神经网络算法是199年前就有的算法,是卷积神经网络的开山始祖。
原理
在这里插入图片描述
C1层是一个卷积层,由6个特征图Feature Map构成。特征图中每个神经元与输入为
的邻域相连。特征图的大小为
,这样能防止输入的连接掉到边界之外
。C1有156个可训练参数(每个滤波器
个unit参数和一个bias参数,一共6个滤波器,共
个参数),共
个连接。
S2层是一个下采样层,有6个 的特征图。特征图中的每个单元与C1中相对应特征图的 邻域相连接。S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。每个单元的 感受野并不重叠,因此S2中每个特征图的大小是C1中特征图大小的1/4(行和列各1/2)。S2层有 个可训练参数和 个连接。
C3层也是一个卷积层,它同样通过5x5的卷积核去卷积层S2,然后得到的特征map就只有10x10个神经元,但是它有16种不同的卷积核,所以就存在16个特征map了。C3中每个特征图由S2中所有6个或者几个特征map组合而成。为什么不把S2中的每个特征图连接到每个C3的特征图呢?原因有2点。第一,不完全的连接机制将连接的数量保持在合理的范围内。第二,也是最重要的,其破坏了网络的对称性。由于不同的特征图有不同的输入,所以迫使他们抽取不同的特征(希望是互补的)。
S4层是一个下采样层,由16个 大小的特征图构成。特征图中的每个单元与C3中相应特征图的 邻域相连接,跟C1和S2之间的连接一样。S4层有32个可训练参数(每个特征图1个因子和一个偏置 和 个连接。
F6层有84个单元(之所以选这个数字的原因来自于输出层的设计),与C5层全相连。有
个可训练参数。如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置。然后将其传递给sigmoid函数产生单元i的一个状态。
最后,输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。
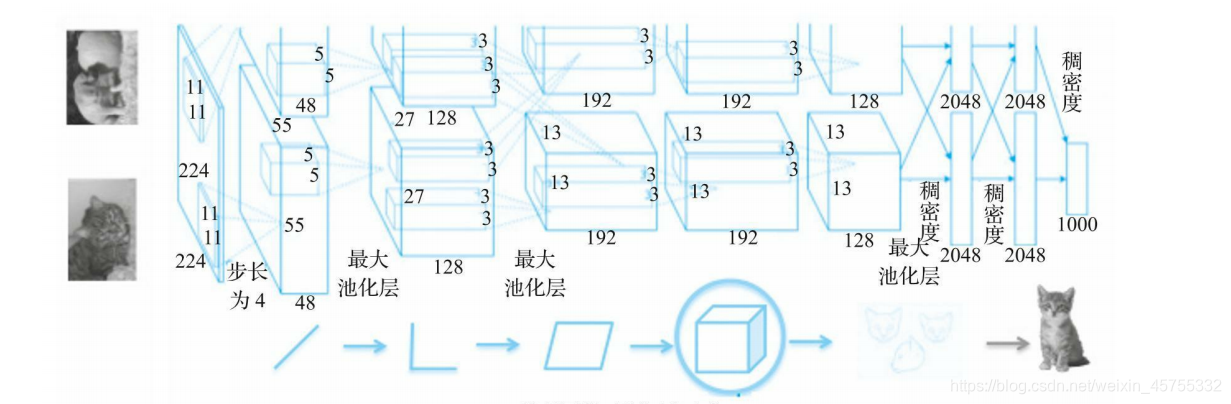
AlexNet架构
在第一次运行中,该网络使用ReLU激活函数和0.5概率的dropout来对抗过拟合。如图4-3所示,架构中使用了一个标准化层,但是由于该网络使用了大量的数据增强,因此在实践中不再使用该标准化层。虽然有更精确的网络可用,但由于AlexNet相对简单的网络结构和较小的深度,AlexNet在今天仍然广泛使用。
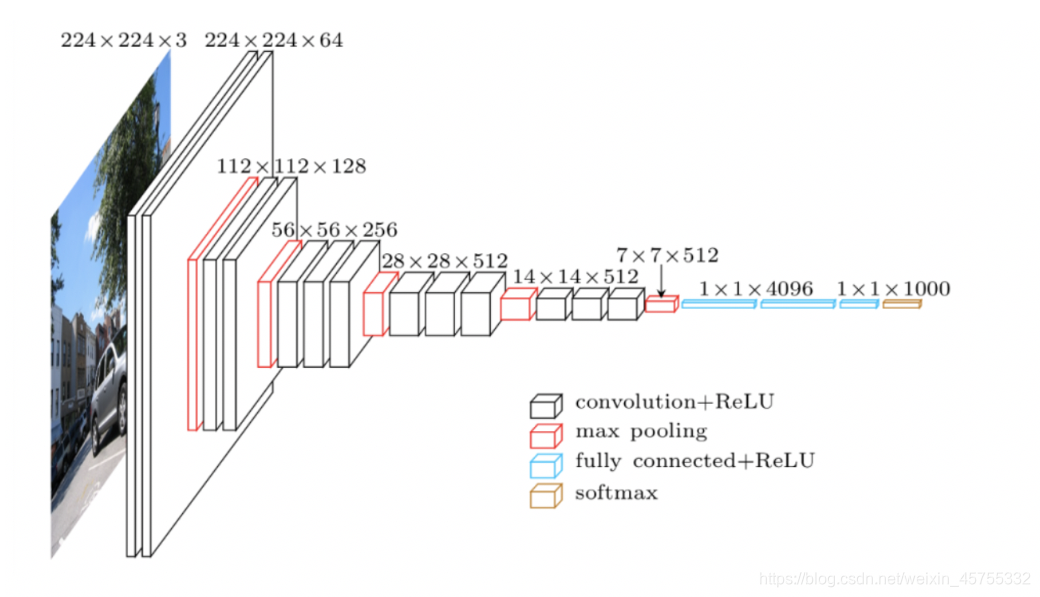
VGG网络架构
介绍
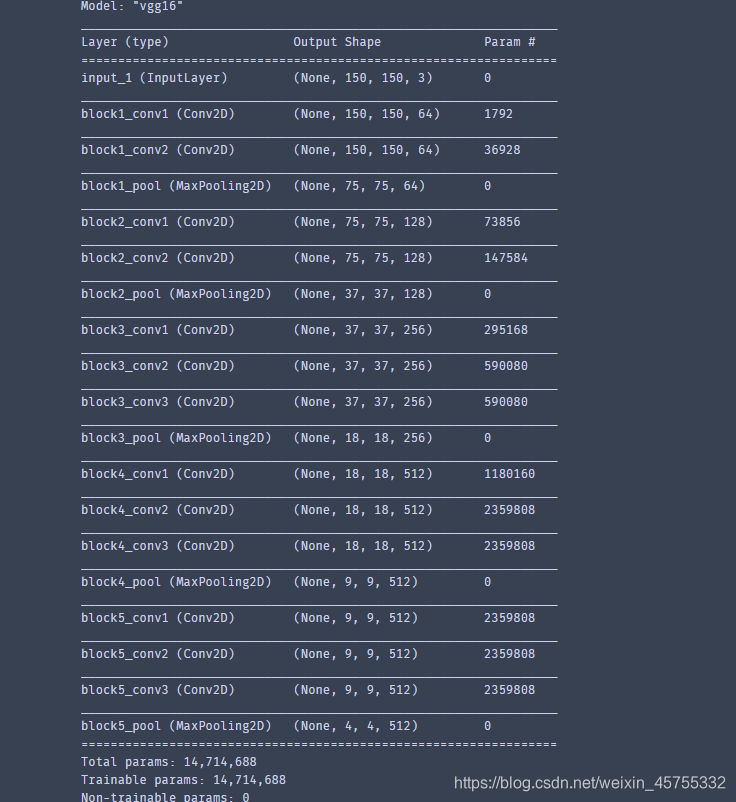
2012年 AlexNet 在 ImageNet 上显著地降低了分类错误率,深度神经网络进入迅速发展阶段。VGG有两种结构,分别是VGG16和VGG19,VGG16是一个16层的神经网络,不包括最大池化层和softmax层。因此被称为VGG16。VGG19由19个层组成,在Keras中,Theano和TensorFlow后端都有一个预先训练好的模型。
原理
这里的关键设计考虑是深度。基于所有层中大小为3×3的卷积滤波器,可以通过添加更多的卷积层来增加网络深度。这个模型的输入图像的默认大小是224×224×3。图像以步长1、填充值1通过一系列卷积层。整个网络中的卷积大小都是3×3。最大池化层以步长2通过2×2的窗口滑动,然后是另一个卷积层,后面是三个全连接层。前两个全连接层各有4 096个神经元,第三个全连接层有1 000个神经元,主要负责分类。最后一层是softmax层VGG16使用一个较小的3×3卷积窗口,相比之下,AlexNet的11×11卷积窗口要大得多。所有隐含层构建过程都使用了ReLU激活函数。VGGNet架构如图4-5所示。
由于小的3×3卷积滤波器,使得VGGNet深度增加。该网络的参数数量约为1.4亿个,大部分来自于第一个全连接层。在现代架构中,VGGNet的全连接层被全局平均池化(GAP)层替代,以最小化参数数量。
注意我们不需要全连接层,所以网络就定义到最后一个卷积层为止。使用全连接层会将输入大小限制为224×224,即ImageNet原图片的大小。这是因为如果输入的图片大小不是224×224,在从卷积过度到全链接时向量的长度与模型指定的长度不相符。
GoogLeNet架构
GoogLeNet最吸引人之处在于它的运行速度非常快,主要原因是由于它引入了一个叫inception模块的新概念,从而将参数数量减少到500万个,是AlexNet的1/12。同时它的内存和功耗也都更低。
GoogLeNet有22层,所以它是一个非常深的网络。添加的层数越多,参数的数量就越多,而且网络很可能出现过拟合。同时计算量将会更大,因为滤波器的线性增加将会导致计算量的二次方增大。所以设计人员使用了inception模块和GAP(Global Average Pooling,全局池化层)。因为全连接层容易过拟合,因此在网络末端将使用GAP替代全连接层。GAP没有需要学习或优化的参数。
模型概述
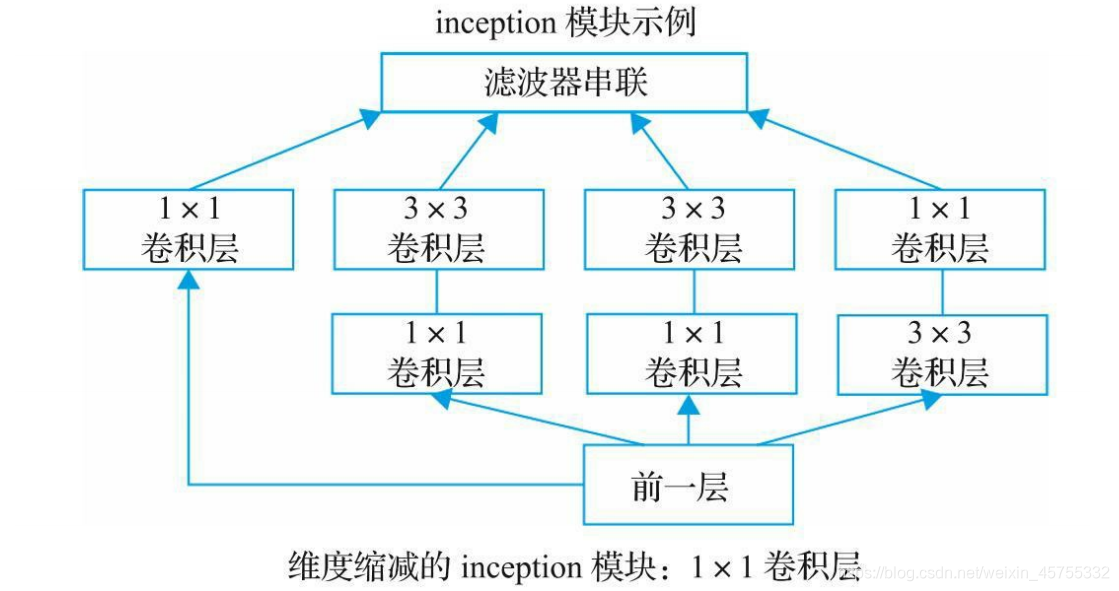
与前面架构不同,GoogLeNet设计人员没有选择特定的滤波器大小,而是将大小为1×1、3×3和5×5的所有三个滤波器和3×3的最大池化层都应用到同一个补丁中,并连接到单个输出向量中。
在GoogLeNet中,inception模块一个叠着一个。这种堆叠允许我们修改每个模块而不影响后面的层。例如,你可以增加或减少任何一层的宽度。

深度网络在反向传播过程中也会遇到所谓的梯度消失问题。通过在中间层添加辅助分类器可以避免这种情况。此外,在训练过程中,中间层的损失将乘以因子0.3计入总损失。
由于全连接层容易出现过拟合,所以用GAP层来替代。平均池化不排除使用dropout,这是一种在深度神经网络中克服过拟合的正则化方法GoogLeNet在60之后添加一个线性层和一个GAP层,通过运用转移学习技术来帮助其他层滑动自己的分类器。
inception模块
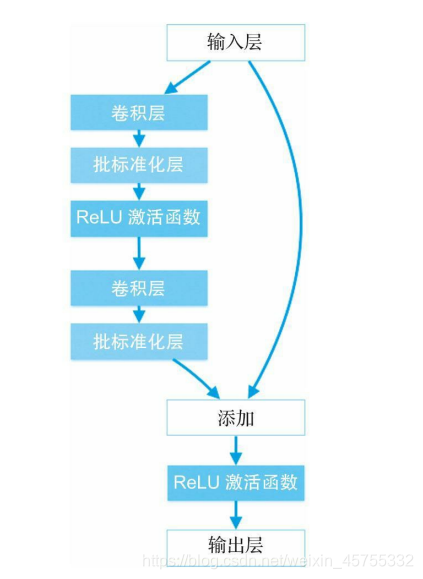
ResNet架构
在一定深度后,向前反馈convNet添加额外层会导致更高的训练误差和验证误差。性能只会随着层的增加而增加到一定深度,然后会迅速下降。在ResNet(残余网络)论文中,作者认为这种低度拟合未必是由梯度消失问题导致的,因为当使用批处理标准化技术时也会发生这种情况。因此,他们增加了一个新的概念叫残余块。ResNet团队向网络中添加了可以跳过卷积层的连接。