聊一聊高可用的实践
最近面试的人比较多,聊起高可用的话题,大家往往都会陷入某一个细节,很少有全面总结,我们去年的高可用基本做到了4个9以上,今天抛砖引玉和大家聊聊我们处理高可用的整体思路。
一、高可用的评价维度
划重点:如果要实现4个9的高可用,年度停机时间是53分钟,意味着我们整个服务链路的所有环节都要实现高可用。

二、先梳理清楚整个服务链路
如图是我们整个服务调用链路,从域名解析开始、CDN、交换机、LVS、nginx集群、应用服务、缓存集群、数据库、上游服务、消息服务、监控。。。

三、首要做的事情是监控
| 监控类型 | 监控项目 |
|---|---|
| 基础设施监控 | 网络、交换机、流量、丢包、连接数等 |
| 系统层监控 | cpu、内存、磁盘、本机的流量等 |
| 应用层监控 | 数据库、缓存、接口QPS、响应时间、失败率、异常等 |
| 业务监控 | 在线主播数、在线用户数、送礼、涉黄。。。 |
| 端用户监控(客户端上报) | 主播曝光、请求时延、功能故障。。。 |
应用层监控,我们使用的是cat,业务监控是根据业务的特性进行个性化实现,端用户上报包括BI埋点,还有公司统一建设的APM告警平台。
四、针对链路的各个环节做高可用
4.1 机房整体的高可用
如图:思路是域名解析,CDN节点,机房网络,单边机房服务都有可能出现故障,至少需要一个备点,由客户端感知并发起重试。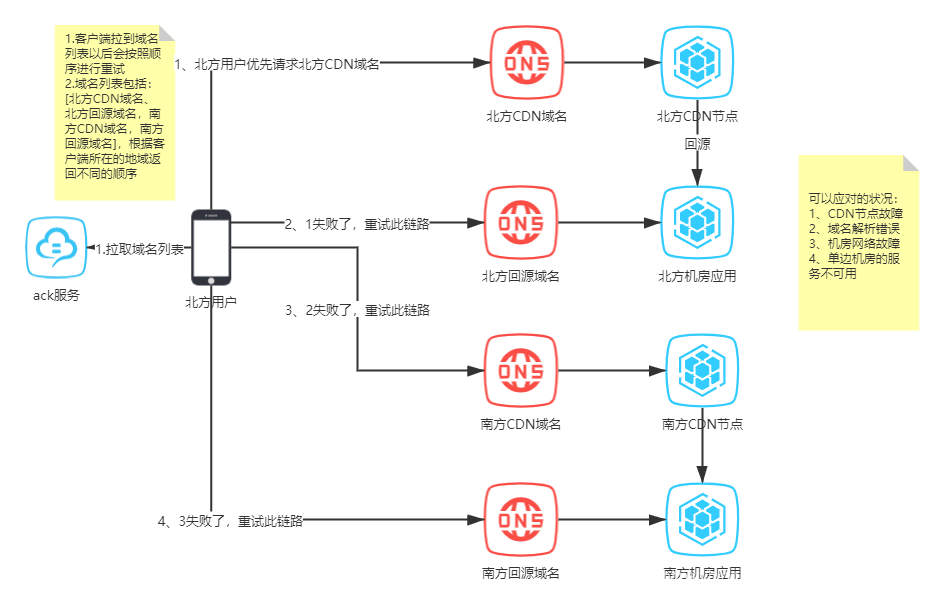
4.2 数据库服务高可用
1.同个机房的数据库主从通过mha来保证高可用。
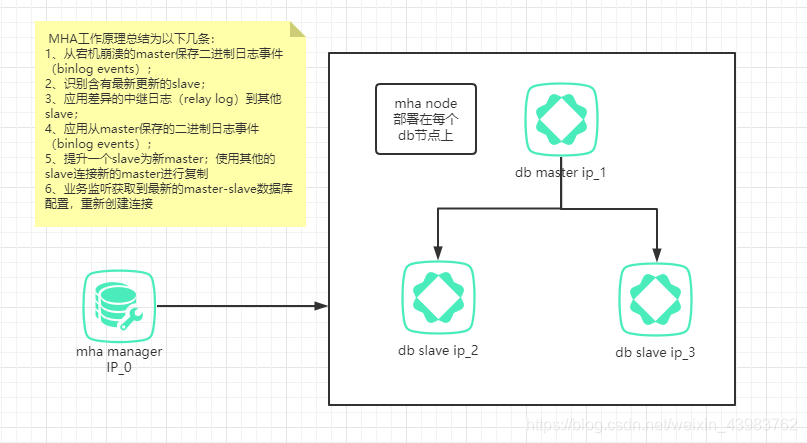
2.跨机房数据库双写,通过otter进行数据库同步.

4.3 内部服务调用的高可用
1、内部服务调用通过proxy的模式进行,proxy实现服务发现,路由,负载均衡,熔断,重试、超时等工作。
2、proxy分为local proxy和remote proxy ,当local proxy节点故障时,可以通过备用链路remote proxy进行调用,实现高可用。

4.4 redis集群高可用
1、使用redis 3以上的版本做集群。
2、主节点失败,集群自动提升slave节点为主。

五、做好业务隔离和拆分
1、定义好业务的重要等级,从S级到1级、2级、3级。
2、根据业务功能、业务等级的不同,在设计上做好业务的隔离,拆分。
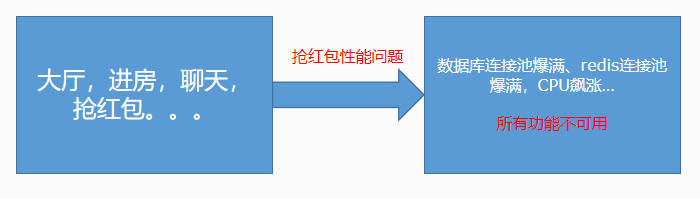
分享一个惨痛经历:
K房业务,所有的功能都打包在一个服务里,因为其中一个功能出问题,导致所有功能不可用,故障指数报表。
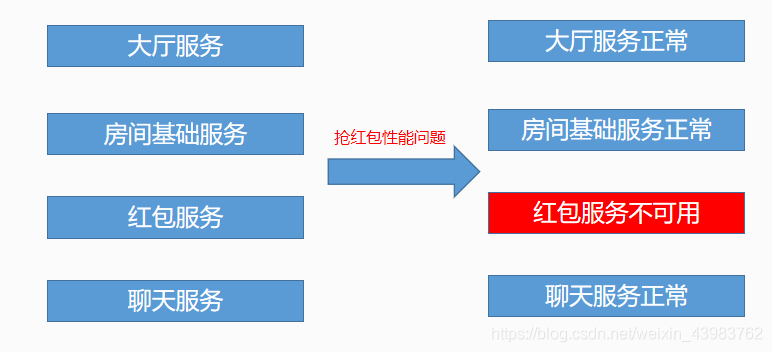
改进:
六、性能优化是提升服务高可用的重要手段
性能优化是提升服务高可用的有效有段,观察公司几次发生的重大故障都是因为性能问题导致。常用的性能优化手段:
1、关注接口时延,我们使用cat进行监控。
2、关注慢查询,运维监控。
3、关注不合理的IO请求,比如高频的redis key,大KEY。
4、关注锁的粒度,让锁的范围尽量小。
。。。
七、快速响应,处理故障
要达到4个9的高可用,年度停机时间是53分钟,在故障出现的时候,响应的速度尤为重要。
1、合适的业务日志。
2、调用链监控。
3、善于使用工具。对于java服务,有jvm工具,arthas,还有公司自建的一些工具。
4、合理配置告警。
5、线上故障优先,开发人员具备快速响应的意识。
八、结语
本文更多的是从整体上提供一些高可用解决的思路,受限于篇幅,各个环节的处理并没有深入,甚至还有不准确的地方,同时各环节的处理方案也不是唯一的,核心的思路大概就是冗余吧。
感谢阅读,欢迎拍砖,from rongjianping