tensorflow中的数据集类Dataset有一个shuffle方法,用来打乱数据集中数据顺序,训练时非常常用。其中shuffle方法有一个参数buffer_size,非常令人费解,文档的解释如下:
buffer_size: A tf.int64 scalar tf.Tensor, representing the number of elements from this dataset from which the new dataset will sample.
你看懂了吗?反正我反复看了这说明十几次,仍然不知所指。
首先,Dataset会取所有数据的前buffer_size数据项,填充 buffer,如下图
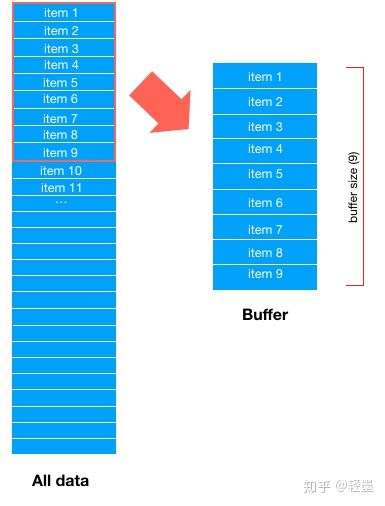
然后,从buffer中随机选择一条数据输出,比如这里随机选中了item 7,那么buffer中item 7对应的位置就空出来了
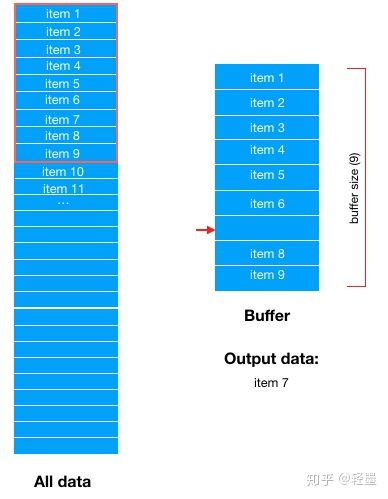
然后,从Dataset中顺序选择最新的一条数据填充到buffer中,这里是item 10
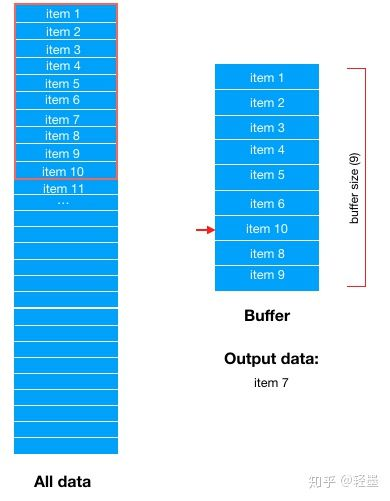
然后在从Buffer中随机选择下一条数据输出。
需要说明的是,这里的数据项item,并不只是单单一条真实数据,如果有batch size,则一条数据项item包含了batch size条真实数据。
shuffle是防止数据过拟合的重要手段,然而不当的buffer size,会导致shuffle无意义。
原文:https://zhuanlan.zhihu.com/p/42417456
也就是说,buffer_size的作用就是存放数据集中部分数据的缓冲区大小,每次取数据是从缓冲区中随机取出一个item,该item是一个batch,取出后再拿数据集中未在缓冲区出现过的数据去填充该缓冲区的空缺位置。