-
synchronized
描述:synchronized可对方法或者类就行block。block住阻塞的线程,会再次尝试获取锁,但是只有一个线程可以获取到锁
底层的原理:1、synchronized底层的原理,是跟jvm指令和monitor有关系的。通过monitorenter和monitorexit两个指令。 2、每个对象都有一个关联的monitor,比如一个对象实例就有一个monitor,一个类的Class对象也有一个monitor, 如果要对这个对象加锁,那么必须获取这个对象关联的monitor的lock锁 3、monitorenter指令:monitor里面有一个计数器,从0开始的。如果一个线程要获取monitor的锁,就看看他的计数器是不是0, 如果是0的话,那么说明没人获取锁,他就可以获取锁了,然后对计数器加1。这个时候,其他的线程在 第一次synchronized那里,会发现对象的monitor锁的计数器是大于0的,意味着被别人加锁了, 然后此时线程就会进入block阻塞状态,什么都干不了,就是等着获取锁 4、重复加锁:如果一个线程第一次synchronized那里,获取到了myObject对象的monitor的锁,计数器加1, 然后第二次synchronized那里,会再次获取myObject对象的monitor的锁,这个就是重入加锁了, 然后计数器会再次加1,变成2
synchronized(myObject) {
。。。
synchronized(myObject) {
。。。
}
}
5、monitorexit指令:出了synchronized修饰的代码片段的范围,就会有一个monitorexit的指令,在底层。
此时获取锁的线程就会对那个对象的monitor的计数器减1,如果有多次重入加锁就会对应多次减1,直到最后,计数器是0
-
CAS:
描述: CAS在底层的硬件级别给你保证一定是原子的,同一时间只有一个线程可以执行CAS,先比较再设置,其他的线程的CAS同时间去执行此时会失败 -
ConcurrentHashMap:
描述:JDK并发包推出的ConcurrentHashMap 线程安全
底层的原理:1、在JDK 1.7以及之前的版本里,分段加锁。[数组1] , [数组2],[数组3] -> 每个数组都对应一个锁,分段加锁 2、JDK 1.8以及之后,做了一些优化和改进,锁粒度的细化,数组里每个元素进行put操作,都是有一个不同的锁, 刚开始进行put的时候,如果两个线程都是在数组[5]这个位置进行put,这个时候,对数组[5]这个位置进行put的时候, 采取的是CAS的策略 1)、同一个时间,只有一个线程能成功执行这个CAS,就是说他刚开始先获取一下数组[5]这个位置的值,null, 然后执行CAS,线程1,比较一下,put进去我的这条数据,同时间,其他的线程执行CAS,都会失败 2)、分段加锁,通过对数组每个元素执行CAS的策略,如果是很多线程对数组里不同的元素执行put, 大家是没有关系的,如果其他人失败了,其他人此时会发现说,数组[5]这位置,已经给刚才又人放进去值了。 就需要在这个位置基于链表+红黑树来进行处理,synchronized(数组[5]),加锁,基于链表或者是红黑树在这个 位置插进去自己的数据 3)、如果你是对数组里同一个位置的元素进行操作,才会加锁串行化处理;如果是对数组不同位置的元素操作, 此时大家可以并发执行的 -
线程池的底层工作原理
描述:系统是不可能说让他无限制的创建很多很多的线程的,会构建一个线程池,有一定数量的线程,让他们执行各种各样的任务,线程执行完任务之后,不要销毁掉自己,继续去等待执行下一个任务1、fixed线程池(fixed,队列,LinkedBlockingQueue,无界阻塞队列): ExecutorService threadPool = Executors.newFixedThreadPool(3) 2、提交任务,先看一下线程池里的线程数量是否小于corePoolSize(线程池中定义的数量)。如果小于, 直接创建一个线程出来执行你的任务。等于话会放入无界的LinkedBlockingQueue队列中。如果执行完你的任务之后, 这个线程是不会死掉的,他会尝试从一个无界的LinkedBlockingQueue里获取新的任务,如果没有新的任务, 此时就会阻塞住,等待新的任务到来 3、fixed线程配置: corePoolSize:3 线程数量 maximumPoolSize:Integer.MAX_VALUE 额外创建的线程数量 keepAliveTime:60s 额外创建的线程处理完任务后,多久销毁 new ArrayBlockingQueue<Runnable>(200) 设置线程池为有界队列 1)、比如说new ArrayBlockingQueue<Runnable>(200),那么假设corePoolSize个线程都在繁忙的工作,大量 任务进入有界队列,队列满了,此时怎么办? 这个时候假设你的maximumPoolSize是比corePoolSize大的,此时会继续创建额外的线程放入线程池里, 来处理这些任务,然后超过corePoolSize数量的线程如果处理完了一个任务也会尝试从队列里去获取任务 来执行 2)、如果额外线程都创建完了去处理任务,队列还是满的,此时还有新的任务来怎么办? 只能reject掉,他有几种reject策略,可以传入RejectedExecutionHandler (1)AbortPolicy (2)DiscardPolicy (3)DiscardOldestPolicy (4)CallerRunsPolicy (5)自定义 如果后续慢慢的队列里没任务了,线程空闲了,超过corePoolSize的线程会自动释放掉,在keepAliveTime之后就会释放 根据上述原理去定制自己的线程池,考虑到corePoolSize的数量,队列类型,最大线程数量,拒绝策略,线程释放时间 4、无界队列的弊端: 在远程服务异常的情况下,使用无界阻塞队列,队列变得越来越大,此时会导致内存飙升起来, 而且还可能会导致你会OOM,内存溢出 5、界队列,可以避免内存溢出: 1)、如果额外线程配置为无限(Integer.MAX_VALUE )一台机器上,有几千个线程,甚至是几万个线程, 每个线程都有自己的栈内存,占用一定的内存资源,会导致内存资源耗尽,系统也会崩溃掉 2)、如果线程池无法执行更多的任务了,自定义一个reject策略,此时建议你可以把这个任务信息持久化写入磁盘里去, 后台专门启动一个线程,后续等待你的线程池的工作负载降低了,他可以慢慢的从磁盘里读取之前持久化的任务, 重新提交到线程池里去执行 6、如果线上机器突然宕机,线程池的阻塞队列中的请求怎么办? 1、必然会导致线程池里的积压的任务实际上来说都是会丢失的 2、如果说你要提交一个任务到线程池里去,在提交之前,麻烦你先在数据库里插入这个任务的信息, 更新他的状态:未提交、已提交、已完成。提交成功之后,更新他的状态是已提交状态 3、系统重启,后台线程去扫描数据库里的未提交和已提交状态的任务,可以把任务的信息读取出来, 重新提交到线程池里去,继续进行执行 -
java内存模型
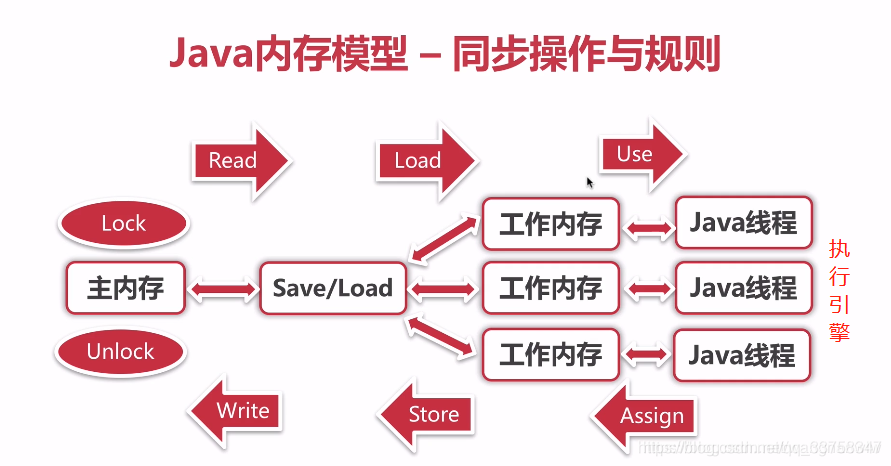
-
volatile关键字
描述:volatile关键字是用来解决可见性和有序性,在有些罕见的条件之下,可以有限的保证原子性,他主要不是用来保证原子性的。加上volatile关键字后的变量 在线程处理完后,JVM会发送一条 lock指令给CPU,CPU会强制写会主内存中的变量,同时因为有MESI缓存一致性协议,所以各个CPU都会对总线进行嗅探,自己本地缓存中的数据是否被别人修改,从而时其他线程失效。 -
happens-before原则
描述:编译器、指令器可能对代码重排序,乱排,要守一定的规则,happens-before原则,只要符合happens-before的原则,那么就不能胡乱重排,如果不符合这些规则的话,那就可以自己排序