通过前面的博客的讲解,我们学会了编写自己的第一个爬虫。下面介绍在redhat 6.5上使用Crontab定期执行该爬虫。
首先按照前面的步骤新建爬虫项目,然后再新建一个start.sh脚本文件。

测试crontab
编写脚本,并测试效果。我们先测试一下crontab的执行效果,在脚本文件中写上如下代码
cd /home/soft/tutorial echo test >> ./test.txt

执行crontab -e编辑任务,如下*/1 * * * * sh /home/soft/tutorial/start.sh ,也即是每分钟执行一次任务。
查看crontab日志
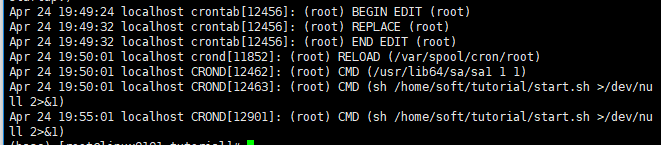
看cron的执行日志的方法:
- 针对Linux系统的查询方法(含Redhat、SUSE):看 /var/log/cron这个文件就可以,可以用tail -f /var/log/cron观察
- mail任务(Linux UNIX)在 /var/spool/mail/root 文件中,有crontab执行日志的记录,用tail -f /var/spool/mail/root 即可查看最近的crontab执行情况。
使用命令:cat /var/log/cron
编写脚本
这里start.h脚本主要的是执行爬虫程序的命令,也就是/root/anaconda3/bin/python -m scrapy crawl quotes -a num=10这条命令。
编写crontab任务,任务为每小时的第0分钟执行任务:

这里的crontab -l是查看各个任务的命令
| 类型 | 文件描述符 | 默认情况 | 对应文件句柄位置 |
|---|---|---|---|
| 标准输入(standard input) | 0 | 从键盘获得输入 | /proc/slef/fd/0 |
| 标准输出(standard output) | 1 | 输出到屏幕(即控制台) | /proc/slef/fd/1 |
| 错误输出(error output) | 2 | 输出到屏幕(即控制台) | /proc/slef/fd/2 |
/dev/null 代表 linux 的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”
-
/dev/null 意思就是把错误输出到“黑洞”
-
/dev/null 2>&1 默认情况是 1,也就是等同于 1>/dev/null 2>&1 。 意思就是把标准输出重定向到“黑洞”, 还把错误输出 2 重定向到标准输出 1 ,也就是标准输出和错误输出都进了“黑洞”
- 2>&1 >/dev/null 意思就是把错误输出 2 重定向到标准出书 1 ,也就是屏幕,标准输出进了“黑洞”,也就是标准输出进了黑洞,错误输出打印到屏幕
CRONTAB运行PYTHON脚本不生效,但是手动执行却正常的问题
一开始编写start.sh的内容时,我直接写的是python -m scrapy crawl quotes -a num=10,报错内容是没有找到scrapy模块。也就是说在当前环境中找不到该模块,但是我们在anaconda中装了爬虫模块的。但是我们直接在shell执行时就能够运行python -m scrapy crawl quotes -a num=10或scrapy crawl quotes -a num=10。
通过尝试发现执行conda config --set auto_activate_base false,退出conda的base虚拟环境也不能够执行上面的代码。从中可以分析可能是该redhat系统环境变量中没有该anaconda的python环境。这个可能是引入虚拟环境的好处,就是不破坏原有的python环境。
解决方案就是在conda的base虚拟环境中,调用python时要严格指定anaconda的python命令的绝对路径。
运行crontab定时作业里边的东西,都要写绝对路径,python环境最好也写绝对路径。