项目一:第六届全国社会媒体处理大会(SMP2017) 第四名 2017.06-2017.08
具体内容应该是一个文档分类的任务,但是自己没有负责到模型的构造里面来.
负责的是whoosh检索工具的构建.
纯Python的全文搜索库,Whoosh是索引文本及搜索文本的类和函数库。它能让你开发出一个个性化的经典搜索引擎。
Whoosh 自带的是英文分词,对中文分词支持不太好,使用 jieba 替换 whoosh 的分词组件
项目二:第七届全国社会媒体处理大会(SMP2018) 第一名 2018.06-2018.08
做的是文本分类的任务,用到了十几个模型,包括 RNN RCNN TextCNN gru.
模型的使用上又包括了词和句子的
最后用到的集成工具是lightgbm
这里是把模型的输出做了一次后处理,当然也试过用伪标签的做法(只是不好用)
项目三:Kaggle - Quora Insincere Questions Classification 银牌 2018.12-2019.02
1\预处理:一些标点符号以及特殊符号的去除
数字的去除\把英文的缩写扩展
特征的构建" 句子长度+词的数量+大小写的个数
2\ 词向量用到的是 fasttext + glove + param

1\用到了一个新的损失函数:focal loss
今年的AAAI 2019论文 Gradient Harmonized Single-stage Detector 提出了一个新的视角——梯度分布上看待样本数量和难易不均衡
其主要是为了限制离群点和平衡容易区分开的样本之间的类别,我也在kernel 里面尝试了使用 GHM-C Loss,结果是和用focal loss差不多的,成绩上没有提升。
2\模型输出之后的后处理的话考虑用的是pesudo-labeling 方法
3\quroa里面存在了很多关于性别和种族的误分类样本,把错误样本输出观察发现是这两个种类的
然后对他们进行进一步的特征抽取
论文一:A Fusion Model of Multi-data Sources for User Profiling in Social Media NLPCC 2018 第四作者
user_predict_area_tfidf.py 是用tfidf+lsi+SVM进行地区预测 user_predict_area_d2w.py 是用d2w+SVM进行地区预测 user_predict_gender_kf.py 是用卡方校验+tfidf+svm进行性别预测 user_predict_gender_lda.py 是用lda+tfidf+svm进行性别预测 text_hstack.py 是用dbow + dm 两种doc2vec模型融合进行预测
论文二:基于多特征Bi-LSTM-CRF 的影评人名识别研究 CCL 2018
我用的就是CRF 的C++版本,结合工具包自己写了一个规则,去训练隐马尔可夫链模型
深度学习这块模型,用到的是RNN+CRF的结构,就是在隐藏层表示完词语之后.

其中 表示句子的第 个字在字典中的id,进而可以得到每个字的one-hot向量,维数是字典大小。
模型的第一层是 look-up 层,利用预训练或随机初始化的embedding矩阵将句子中的每个字 由one-hot向量映射为低维稠密的字向量(character embedding) , 是embedding的维度。在输入下一层之前,设置dropout以缓解过拟合。
模型的第二层是双向LSTM层,自动提取句子特征。将一个句子的各个字的char embedding序列 作为双向LSTM各个时间步的输入,再将正向LSTM输出的隐状态序列 与反向LSTM的 在各个位置输出的隐状态进行按位置拼接 ,得到完整的隐状态序列
在设置dropout后,接入一个线性层,将隐状态向量从 维映射到 维, 是标注集的标签数,从而得到自动提取的句子特征,记作矩阵 。可以把 的每一维 都视作将字 分类到第 个标签的打分值,如果再对 进行Softmax的话,就相当于对各个位置独立进行 类分类。但是这样对各个位置进行标注时无法利用已经标注过的信息,所以接下来将接入一个CRF层来进行标注。
模型的第三层是CRF层,进行句子级的序列标注。CRF层的参数是一个 的矩阵 , 表示的是从第 个标签到第 个标签的转移得分,进而在为一个位置进行标注的时候可以利用此前已经标注过的标签,之所以要加2是因为要为句子首部添加一个起始状态以及为句子尾部添加一个终止状态。如果记一个长度等于句子长度的标签序列 ,那么模型对于句子 的标签等于 的打分为
可以看出整个序列的打分等于各个位置的打分之和,而每个位置的打分由两部分得到,一部分是由LSTM输出的 决定,另一部分则由CRF的转移矩阵 决定。进而可以利用Softmax得到归一化后的概率:
模型训练时通过最大化对数似然函数
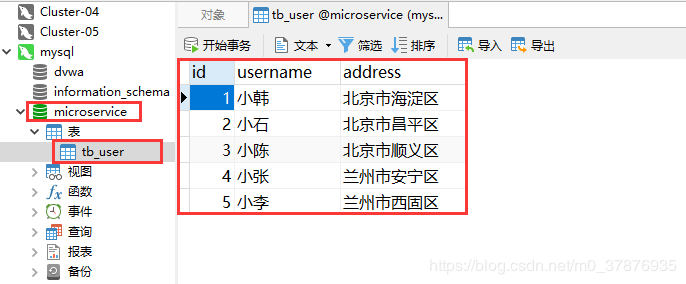
python 连接的版本:
import pymysql
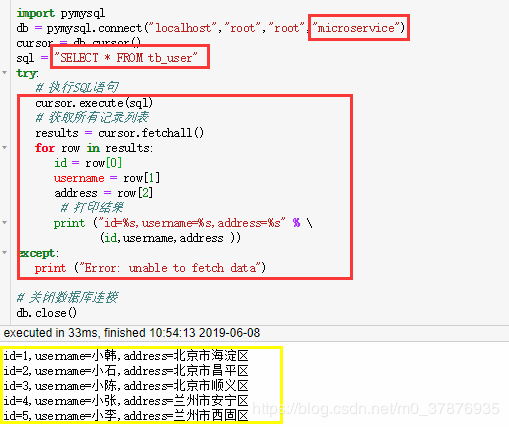
(就是直接掉包来运行mysql,存储数据的话也是如此,用爬虫下来的数据,直接一个代码保存进服务器里面)
xshell
首先我们来尝试使用上传功能,先输入rz,回车就会弹出文件选择对话框,选择本地的文件就可以上传,如下图所示。
rz 上传文件
sz 下载文件
在那边后台查看mysql表的情况

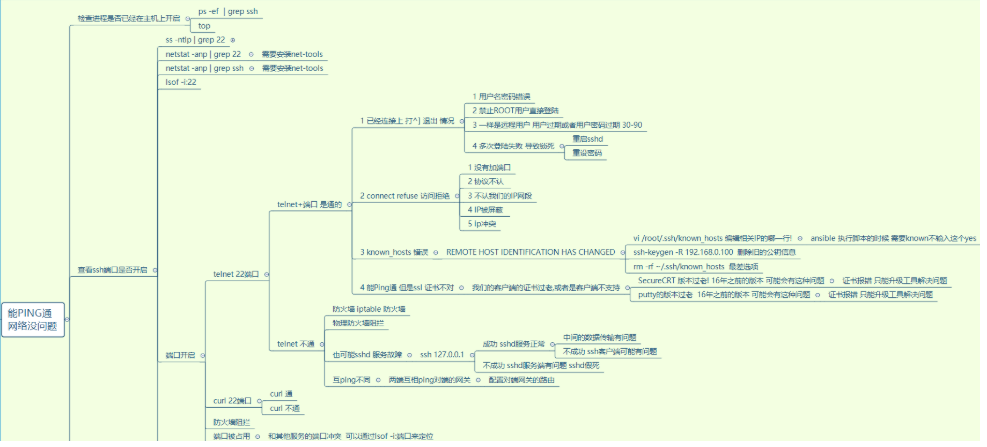
莫名其妙的断开:
【1、sshd服务未开启
#service sshd status(查看sshd状态)
#service sshd start (开启sshd服务)
#service network restart (重启网络服务)
设置为开机自启动,避免每次出现同一原因。
#chkconfig sshd on
可以再查看sshd的运行级别状态:
#chkconfig --list sshd
sshd 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
2、防火墙阻挡
#service iptables stop(关闭防火墙再次登录远程服务)
相关命令如下
#iptables -L (查看防火墙状态)
#service iptables start(开启防火墙)3、端口被占用或者未开启
查看sshd的配置端口号(默认为22号端口)
#cat /etc/ssh/sshd_config
#netstat -antlp | grep 22】

docker
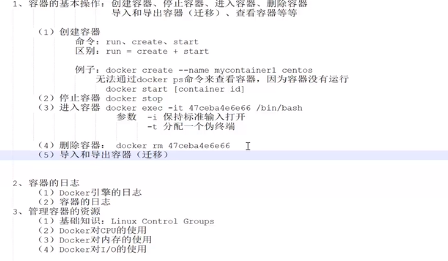
Docker三大核心组件:(运行起来的镜像就可以称作容器)
- Docker 镜像--Dcoker images:类比与类
- Docker 仓库--Docker registeries:
- Docker 容器-- Dcoker conrainers:类比于实例化的对象
跑起来一个docker容器:
docker的导入和导出:(直接tar包)

上传镜像和下载镜像
sudo docker push [option]
把你想要传的东西穿上去,目前国内被墙了,再看看
sudo docker pull
常用指令:


搜索镜像 docker search 镜像名称 下载镜像 docker pull 镜像 查看已安装镜像列表 docker images 删除镜像 docker rmi 镜像id 运行镜像生成新的容器 docker run -d -it 镜像名称:版本号 eg: docker run -d -it -p 8080:8080 tomcat:7 -p 端口映射,前者宿主机端口,后者容器端口,多个端口 -p 8080:8080 -p 9090:9090 -d 后台运行容器 -it 以交互模式运行容器 eg: docker run -d -it -p 8080:8080 --name test -v /opt:/opt tomcat:7 -v 数据挂载 进入容器 docker exec -it 容器id /bin/bash 容器的启动停止 docker start 容器id docker stop 容器id 删除容器 docker rm 容器id 查看容器日志 docker logs 容器id -f
和队友统一化环境(算法、测试、运维)
- docker是一个开源的软件部署解决方案;
- docker也是轻量级的应用容器框架;
- docker可以打包、发布、运行任何的应用。
在我看来,就是类似虚拟机的东西,只是不同点是虚拟机的硬件都是靠CPU虚拟出来的,而docker可以调用你的本地硬件进行计算,而且docker的封装更为精简。
Nvidia-Docker是英伟达官方出品的docker插件,专门用来允许container直接调用本地的英伟达GPU。不过目前只支持linux系统,需要在你的本机安装好CUDA和CUDNN
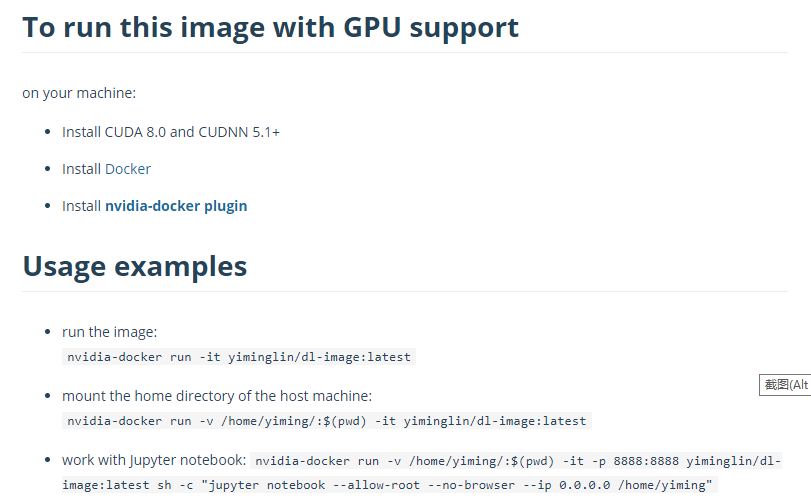
分享到dockerhub上面去,队友有需要就可以下载或者run整一个container,实现环境和代码的封装。
备份:(直接加载container到本地,或者用数据卷、或者用tar命令打包下来)
载入home路径到docker的container
需要注意的是一旦你退出某个container,所有你做的东西都不会保存,所以为了保存数据和代码,我们可以把某个目录载入到container中,这样我们在docker中对该目录所做的修改都会保存到本机了。
nvidia-docker run -v /home/yiming/:$(pwd) -it yiminglin/dl-image:latest上述命令把加载了我本地的home路径,在container就可以在/home/目录中看到我本地机器上保存在home目录的所有东西:
利用数据卷容器来备份、恢复、迁移数据卷
可以利用数据卷对其中的数据进行进行备份、恢复和迁移。(实验室的一些重要数据,用来做备份。模型、代码)
3.1 备份
首先使用 --volumes-from 标记来创建一个加载 dbdata 容器卷的容器,并从本地主机挂载当前到容器的 /backup 目录。命令如下:
$ sudo docker run --volumes-from dbdata -v $(pwd):/backup ubuntu tar cvf /backup/backup.tar /dbdata容器启动后,使用了 tar 命令来将 dbdata 卷备份为本地的 /backup/backup.tar
3.2 恢复
如果要恢复数据到一个容器,首先创建一个带有数据卷的容器 dbdata2。
$ sudo docker run -v /dbdata --name dbdata2 ubuntu /bin/bash然后创建另一个容器,挂载 dbdata2 的容器,并使用 untar 解压备份文件到挂载的容器卷中。
$ sudo docker run --volumes-from dbdata2 -v $(pwd):/backup busybox tar xvf /backup/backup.tar