软件测试会用到正则表达式吗?答案是肯定的:
正则表达式的应用场景有很多,一般是用来验证字符串,提取字符串和替换字符串。
在接口测试或性能测试中,经常需要从响应结果中提取数据作。经常用提取方法方式包括XPath和正则表达式提取法(例如:Jmeter中的正则表达式提取器)。
XPath的应用在前边UI自动化中已经介绍,今天主要学习下正则表达式的应用。
一、概念
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母,0-9之间的数字)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
比如:
表达式“ab+” 可以匹配 'ab', 'abb','abbbbb'等,+号代表前面的字符必须出现一次活多次。
表达式“ab*c”可以匹配‘ac’、‘abc’、‘abbbbc’等,*号代表前边的字符可以不出现,也可以出现一次或多次。
表达式“ab?c”可以匹配‘ac’、‘abc’,?代表前面的字符最多出现一次,也可能是零次。
二、语法
1、普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符
所有大写和小写字母、所有数字、所有标点符号和一些其他符号都属于普通字符的范畴。
2、非打印字符
换行(\n)、回车(\r)等都属于非打印字字符。正则表达式前均会加‘\’来表示。
3、特殊字符
一些有特殊含义的字符,比如*、\、$、()、^、|等。
4、限定符
用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。
有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
*、+、{n}、{n,}、{n,m}配合?使用,可以实现最少匹配*?表示重复0次或多次,但尽可能少的重复,以此类推。
5、定位符
定位符用来描述字符串或单词的边界,用于正则表达式固定到行首或行尾。
^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
常用元字符对照说明表,基本满足日常应用:
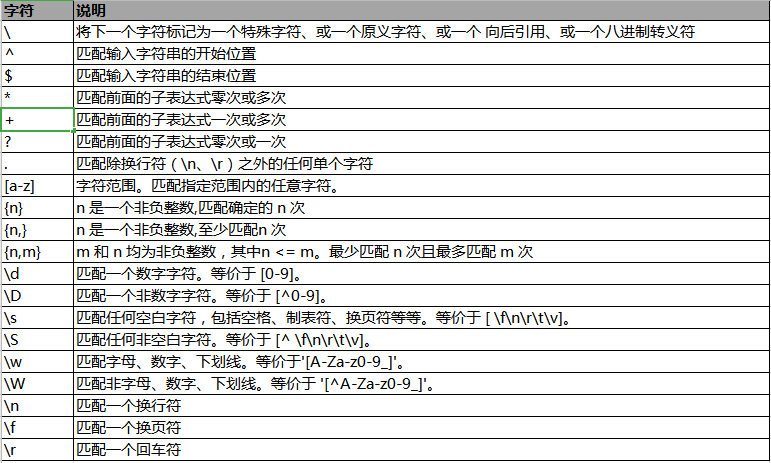
注意:如果要匹配*、\、+、?等特殊符号本身,必须要使用字符"转义",即,将反斜杠字符\ 放在它们前面 。
比如:获取*用表达式\*,获取+用表达式\+。
6、贪婪与非贪婪
当正则表达式中包含限定符时,都是尽可能多的字符,这中匹配方式叫做贪婪匹配。
为了避免重复多次的匹配,实现最小匹配,引入非贪婪,通常在限定符后边加?实现。
{
code123
}
贪婪写法:code(\d+)
匹配结果:123
非贪婪写法:code(\d+?)
匹配结果:1
三、运算符优先级
从左到右进行计算,并遵循优先级顺序;相同优先级的从左到右进行运算,不同优先级的运算先高后低。

四、示例
结合Jmeter正则表达式,我们来看下正则表达式的应用。
1、正则表达式提取器
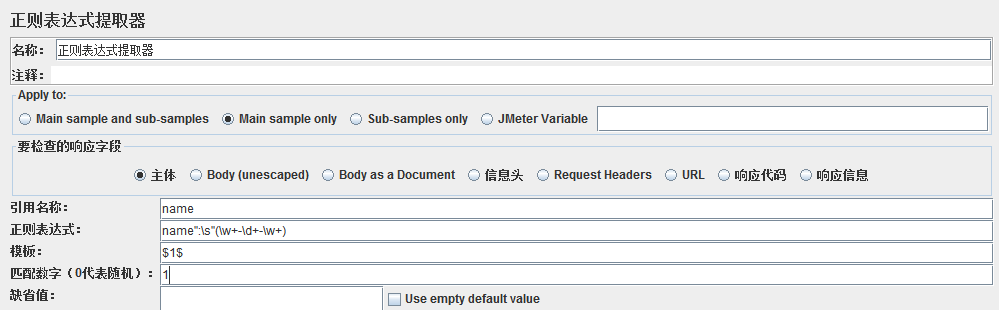
Apply to:应用范围。
要检查的响应字段:样本数据源。
引用名称:引用时的变量名称,使用时输入${name}替换参数即可。
正则表达式:用于匹配数据,()括号里面的内容为真实需要的值。
模板:用于从找到的匹配项创建字符串的模板。这是一个带有特殊元素的任意字符串,用于引用正则表达式中的组。
引用组的语法是:'$1$'引用组1,'$2$ '引用组2。$0$引用整个表达式匹配的内容。
通过正则表达式测试器,更直观的感受一下$1$,$0$对应的值是什么。

匹配数字:正则表达式匹配数据的所有结果可以看做一个数组,匹配数字即可看做是数组的第几个元素。
-1表示全部,0随机,1第一个,2第二个,以此类推。若只要获取到匹配的第一个值,则填写1
缺省值:匹配失败时的默认值,可以指定一个默认值,或不指定均可以。
2、正则表达式练习
示例1:获取code值,用于其它接口的入参
{ "code": "205520", "name": "test-20-header" }
正则表达式1:code":\s"([0-9]+)
正则表达式2:code":\s"(\d+)
说明:要取的值在括号里面,使用\s是不确定中间是否有空格等特殊符号,后边用+是防止有多个空格,[0-9]+等价于\d
示例2:获取code值,用于其它接口的入参
{
"code": "520",
"name": "test-520",
"code": "521"
}
获取第1个code的正则表达式:"code":\s"(\d+)",\s+"name
获取第2个code的正则表达式:name":\s+\S+\s+"code":\s"(\d+)
说明:当一个返回体中,同一个元素具有多个时,如何取值呢?
我们看看两个code有什么特征:
第1个code下面接着是name参数,可以根据name向上找code
第2个code上面是name参数,可以根据name向下找code
示例3:获取第1个code值,用于其它接口的入参
{
"id": "22ui45abc3i3902334",
"code": "520",
"name": "test-520",
"code": "521",
"name": "test-521"
}
正则表达式:id":\s+"\S+\s+"code":\s"(\d+)
说明:code没有第2个实例的特征了,但是发现第一个code的前边是id参数,可以根据id找第一个code值