Redis 作为广为人知的内存数据库,在玩具项目和复杂的工业级别项目中都看到它的身影,然而 Redis 却是使用单线程模型进行设计的,这与很多人固有的观念有所冲突,为什么单线程的程序能够抗住每秒几百万的请求量呢?这也是我们今天要讨论的问题之一。
除此之外,Redis 6.0 新版本却抛弃了单线程模型这一设计,原本使用单线程运行的 Redis 也开始选择性使用多线程模型,这一看似有些矛盾的设计决策是今天需要讨论的另一个问题。
这两个看起来有些矛盾的问题实际上并不冲突,我们会分别阐述对这个看起来完全相反的设计决策作出分析和解释,不过在具体分析它们的设计之前,我们先来看一下不同版本 Redis 顶层的设计:
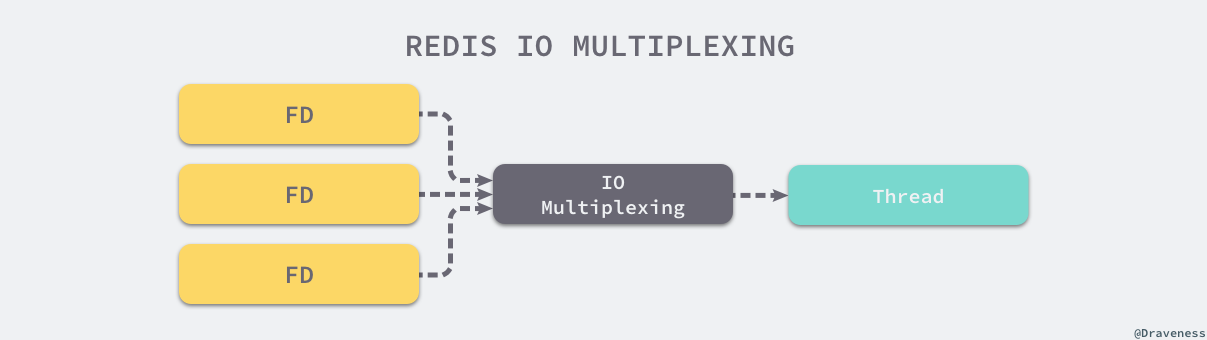
Redis 作为一个内存服务器,它需要处理很多来自外部的网络请求,它使用 I/O 多路复用机制同时监听多个文件描述符的可读和可写状态,一旦受到网络请求就会在内存中快速处理,由于绝大多数的操作都是纯内存的,所以处理的速度会非常地快。(I/O多路复用 与 redis 请看我的另外一篇博客:redis-10 redis和 I/O多路复用 )
单线程模型
Redis 从一开始就选择使用单线程模型处理来自客户端的绝大多数网络请求,这种考虑其实是多方面的,作者分析了相关的资料,发现其中最重要的几个原因如下:
- 使用单线程模型能带来更好的可维护性,方便开发和调试,提升效率(避免了锁的开销);
- 使用单线程模型也能并发的处理客户端的请求;
- Redis 服务中运行的绝大多数操作的性能瓶颈都不是 CPU;
上述三个原因中的最后一个是最终使用单线程模型的决定性因素,其他的两个原因都是使用单线程模型额外带来的好处,在这里我们会按顺序介绍上述的几个原因。
可维护性
可维护性对于一个项目来说非常重要,如果代码难以调试和测试,问题也经常难以复现,这对于任何一个项目来说都会严重地影响项目的可维护性。多线程模型虽然在某些方面表现优异,但是它却引入了程序执行顺序的不确定性,代码的执行过程不再是串行的,多个线程同时访问的变量如果没有谨慎处理就会带来诡异的问题。
并发处理
使用单线程模型也并不意味着程序不能并发的处理任务,Redis 虽然使用单线程模型处理用户的请求,但是它却使用 I/O 多路复用机制并发处理来自客户端的多个连接,同时等待多个连接发送的请求。
在 I/O 多路复用模型中,最重要的函数调用就是 select 或 epoll 以及类似函数,该方法能够同时监控多个文件描述符(也就是客户端的连接)的可读可写情况,当其中的某些文件描述符可读或者可写时,select/epoll 方法就会返回可读以及可写的文件描述符个数。
使用 I/O 多路复用技术能够极大地减少系统的开销,系统不再需要额外创建和维护进程和线程来监听来自客户端的大量连接,减少了服务器的开发成本和维护成本。
性能瓶颈
最后要介绍的其实就是 Redis 选择单线程模型的决定性原因 —— 多线程技术的能够帮助我们充分利用 CPU 的计算资源来并发的执行不同的任务,但是 CPU 资源往往都不是 Redis 服务器的性能瓶颈。哪怕我们在一个普通的 Linux 服务器上启动 Redis 服务,它也能在 1s 的时间内处理 1,000,000 个用户请求。
如果这种吞吐量不能满足我们的需求,更推荐的做法是使用分片的方式将不同的请求交给不同的 Redis 服务器来处理,而不是在同一个 Redis 服务中引入大量的多线程操作。
简单总结一下,Redis 并不是 CPU 密集型的服务,如果不开启 AOF 备份,所有 Redis 的操作都会在内存中完成不会涉及任何的 I/O 操作,这些数据的读写由于只发生在内存中,所以处理速度是非常快的;整个服务的瓶颈在于网络传输带来的延迟和等待客户端的数据传输,也就是网络 I/O,所以使用多线程模型处理全部的外部请求可能不是一个好的方案。
AOF 是 Redis 的一种持久化机制,它会在每次收到来自客户端的写请求时,将其记录到日志中,每次 Redis 服务器启动时都会重放 AOF 日志构建原始的数据集,保证数据的持久性。
多线程虽然会帮助我们更充分地利用 CPU 资源,但是操作系统上线程的切换也不是免费的,线程切换其实会带来额外的开销,其中包括:
- 保存线程 1 的执行上下文;
- 加载线程 2 的执行上下文;
频繁的对线程的上下文进行切换可能还会导致性能地急剧下降,这可能会导致我们不仅没有提升请求处理的平均速度,反而进行了负优化,所以这也是为什么 Redis 对于使用多线程技术非常谨慎。
引入多线程
redis 终于实现多线程了?打住,多线程是不可能多线程的,这辈子都不可能多线程。
为什么不能实现多线程,当然是:复杂性急剧增加 以及 锁的效率 等等。这里所说的多线程其实准确的说是 IO Threads,即针对客户端的这部分可以做成多线程。这个操作通过系统调用读/写操作,将客户端的输入输出缓冲中的数据通过多线程 IO 与 客户端交互。根据官方说法这部分通常能够占到 CPU 负载的 50%,将这部分通过多线程的方式处理,这样能进一步提升单实例的性能,尤其是我们当前服务器动辄就 64 核,不用白不用。然而核心流程仍然还是多线程,实现起来也比较简单,性价比也高。