try、catch、finally 的理解
这三个关键字常用于我们捕捉异常的一整套流程,try 用来确定代码执行的范围,catch 捕捉可能会发生的异常,finally 用来执行一定要执行的代码块,除了这些,我们还需要清楚,每个地方如果发生异常会怎么办,举一个例子来演示一下:
public void testCatchFinally() {
try {
log.info("try is run");
if (true) {
throw new RuntimeException("try exception");
}
} catch (Exception e) {
log.info("catch is run");
if (true) {
throw new RuntimeException("catch exception");
}
} finally {
log.info("finally is run");
}
}
这个代码演示了在 try、catch 中都遇到了异常,代码的执行顺序为:try -> catch -> finally,输出的结果如下:

整个过程可以总结为两点:
- finally先执行后,再抛出catch的异常
- 最终捕获的异常是catch的异常,try抛出来的异常已经被catch吃掉了,所以当我们遇见catch也有可能会抛出异常时,我们可以先打印出try的异常,这样try的异常在日志中就能看到了。
Exception和Error的区别
-
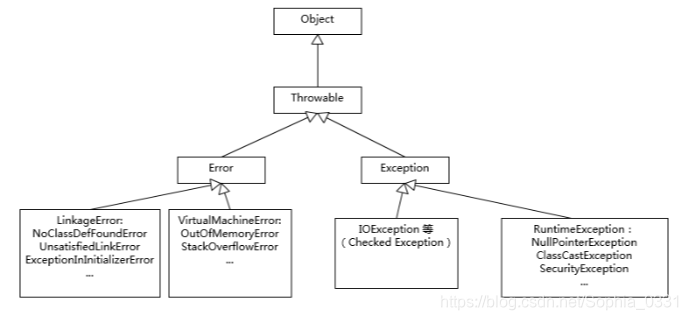
Exception和Error 都是继承了Throwable类,在java中只有Throwable类型的实例才可以被抛出或者捕获,它是异常处理机制的基本组成类型。
-
Exception和Error体现了Java平台设计者对不同异常情况的分类。Exception是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
-
Error 是指正常情况下,不大可能出现的情况,绝大部分的Error 都会导致程序(比如 JVM 自身)处于非正常的,不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如 OutofMemoryError之类,都是Error的子类。
-
Exception又分为可检查异常和不检查异常。
可检查异常:可检查异常在源代码里必须显式的进行捕获处理,这是编译器检查的一部分。不可查的Error,是Throwable 不是 Exception。
不检查异常:就是所谓的运行时异常,类似NullPointerException,ArrayIndexOutofBoundsException之类,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译期强制要求。
对比了这么多Exception和Error的区别,那类之间的关系是怎么样的呢?一张图胜过千言万语,下面展示Throwable ,Exception 和Error的设计分类图:
不规范的异常处理有哪些
1、 尽量不要捕获类似Exception这样的通用异常,而是应该捕获特定异常。
尽量让代码直观的体现出尽量多的信息,尽量不写Exception通用异常,异常信息最好更确切一些。
例如:在这里Thread.sleep()抛出的是InterruptedException,写InterruptedException异常要比Exception通用异常信息更确切,更好定位问题。
try{
//业务代码
//...
Thread.sleep(1000L);
}catch(Exception e){
//Ignore it
}
2、 不要生吞异常。
生吞异常,往往是基于假设这段代码可能不会发生,或者感觉忽略异常是无所谓的,但是千万不要在产品代码做这种假设。
如果不把异常抛出来,或者也没有输出到日志之类,程序可能会在后续代码以不可控的方式结束。没有人能轻易判断究竟是哪里抛出来的异常,以及是什么原因产生了异常。
例如:
try{
//业务代码
//...
}catch(IOException e){
e.printStackTrace();
}
在PrintStackTrace()的文档中,有写到“Prints this throwable and its backtrace to the standard error stream”。意思是,在稍微复杂一点的生产系统中,标准出错不是个合适的输出选项,因为你很难判断出到底输出到哪里去了。
尤其是对分布式系统,如果发生异常,但是无法找到堆栈轨迹(stacktrace),这纯属是为诊断设置障碍。所以最好使用产品日志,详细的输出到日志系统里。
自定义异常
自定义异常时,除了保证提供足够的信息,还有两点需要考虑:
- 是否需要定义成 Checked Exception,因为这种类型设计的初衷更是为了从异常情况恢复,作为 异常设计者,我们往往有充足信息进行分类
- 在保证诊断信息足够的同时,也要考虑避免包含敏感信息,因为那样可能导致潜在的安全问题。
从性能角度分析Java的异常处理机制
- try-catch 代码段会产生额外的性能开销,或者换个角度说,它往往会影响JVM对代码进行优化,所以建议仅捕获有必要的代码,尽量不要一个大的try包住整段的代码;同时,利用异常控制代码流程,也不是一个好主意,远比我们通常意义上的条件语句(if/else ,switch)要低效。
- Java每实例化一个Exception,都会对当时的栈进行快照,这是一个相对比较重的操作。如果发生的非常频繁,这个开销可就不能被忽略了。
小结
这篇文章对异常处理做了初步的了解,在实际项目应用上,当我们的服务出现反应变慢,吞吐量下降的时候,检查发生最频繁的Exceptin也是一种思路,可以从这方面去考虑。最后对异常处理总结了一句话:在做异常处理时,尽量遵循 『throw early,catch late』的原则去操作,让问题越早暴露越有利于我们定位问题,降低排查的难度。
