1.这次大作业做的非常的艰难,先是mooc视频一遍遍看,只是把数据提取的相关知识了解了一下。
2.真正自己上手的时候,真的是困难重重:
我用的win10系统,我找到网址之后不会查看源代码,弄了半天不会,最后听取了龙俊杰同学的建议下载了另外一个浏览器才查查看了源代码,
数据提取一个网址一个样,我的那个网站包涵了160多个国家的数据,非常庞大,导致我还是不会提取,最终还是在龙俊杰同学的帮助下完成,
数据可视化我实在是不会,只能借鉴其他同学的博客,最终还好弄成了。
源代码:
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import numpy as np
url="https://www.phb123.com/city/wenhua/36357.html"
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
html=r.text
except:
print("产生异常")
soup=BeautifulSoup(html,'html.parser')
a=soup.find_all("td")
b=[]
for i in range(len(a)):
b.append(a[i].get_text())
m=[]
for i in b:
i=i.replace('\r\n\t\t\t\t','')
m.append(i)
n=len(m)
l=[]
for i in range(1,n,6):
l.append(m[i])
l.pop(0)
j=[]
for i in range(11,n+1,6):
j.append(eval(m[i]))
j.pop(0)
l=l[:10]
j=j[:10]
print(l,j)
n=10
x=np.arange(n)
plt.rcParams['font.sans-serif'] = ['SimHei']
pl=plt.bar(x,height=j,width=0.5,label='世界遗产数量',tick_label=l)
for a,b in zip(x,j):
plt.text(a,b+0.05,'%.0f'%b,ha='center',va='bottom',fontsize=10)
plt.legend()
plt.show()
效果图:
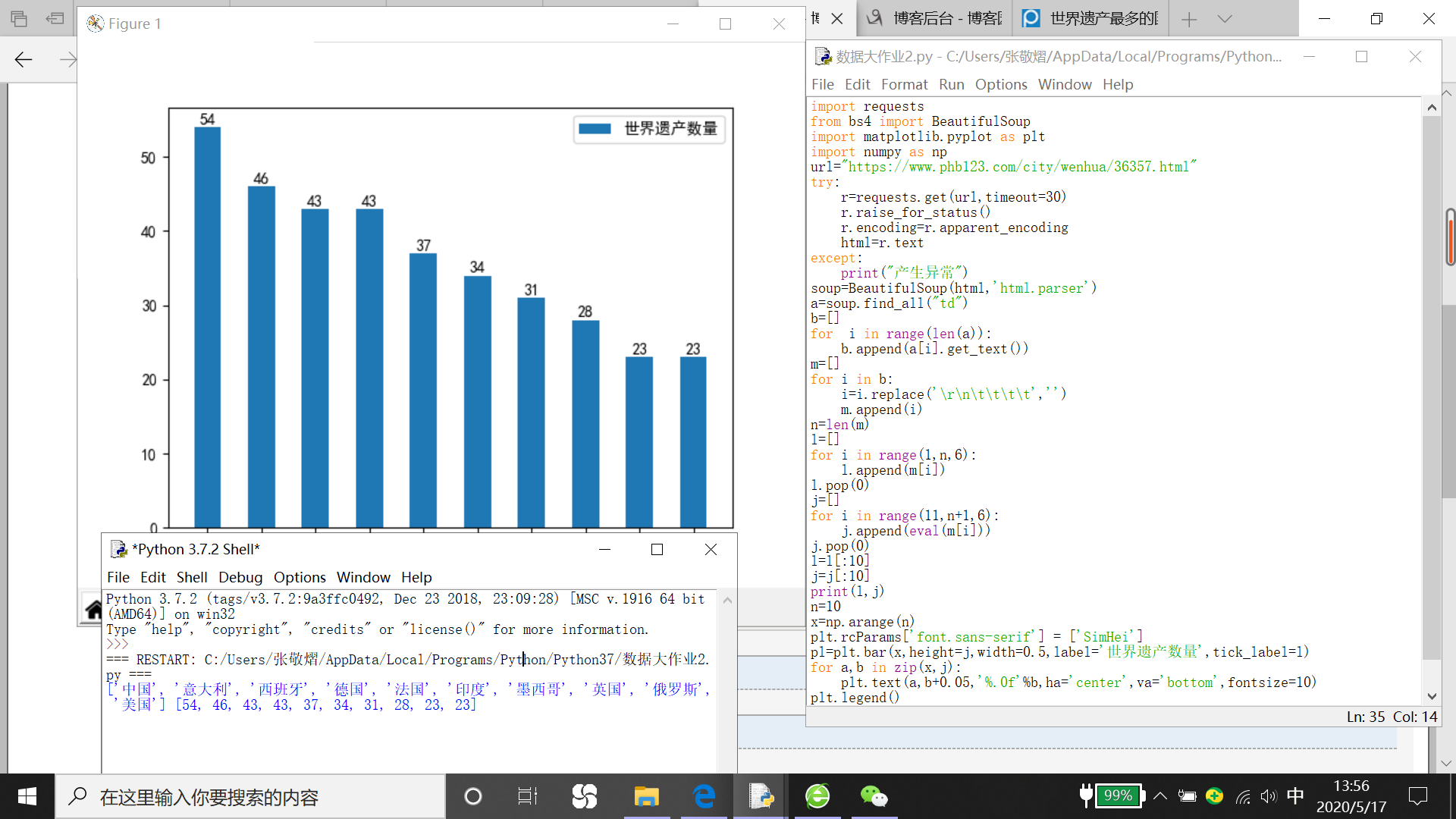
最后感谢龙俊杰同学的帮助。