-------目录------------------------------------------------------------------------------------------------------
3.Hadoop简介
8.Hadoop-MapReduce的shuffle过程及其他
-------------------------------------------------------------------------------------------------------------
MapReduce
1、概述
1.思考
求和:1+3+5+8+2+7+3+4+9+...+Integer.MAX_VALUE。
这是一个简单的加法,如果这道题单台机器线性执行的话,可以想想这个时间的消耗有多大,如果我们换一种思维来进行计算那么这个时间就可以减少很多,将整个加法分成若干个段进行相加,最后将这些结果段再进行相加。这样就可以实行分布式的计算。
上述的方法的思想就是:分而治之,然后汇总。
2.MapReduce分布式计算框架
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
Apache对其做了开源实现,整合在hadoop中实现通用分布式数据计算。
MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。大大简化了分布式并发处理程序的开发。
Map阶段就是进行分段处理。
Reduce阶段就是进行汇总处理。汇总之后还可以进行数据的一系列美化操作,然后再输出。
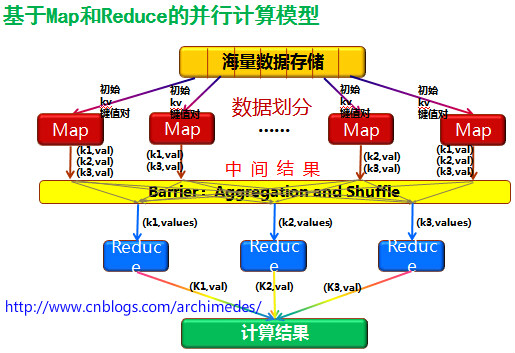
3.MapReduce原理
MapReduce原理图: 此图借鉴的网上的。具体出处如图上的地址。
2、Map、Reduce的入门案例
1.入门案例
1>实现WordCount
①WcMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable k1, Text v1, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// 1.得到行
String line = v1.toString();
// 2.切行为单词
String[] wds = line.split(" ");
// 3.输出单词和数量,即k2、v2
for (String w : wds) {
context.write(new Text(w), new IntWritable(1));
}
}
}②WcReduce
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3s,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 1.获取单词
String word = k3.toString();
// 2.遍历v3s,累计数量
int count = 0;
Iterator<IntWritable> it = v3s.iterator();
while (it.hasNext()) {
count += it.next().get();
}
// 3.输出结果
context.write(new Text(word), new IntWritable(count));
}
}③WcDerver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WcDriver {
public static void main(String[] args) throws Exception {
// 1.声明一个作业
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2.声明作业的入口
job.setJarByClass(WcDriver.class);
// 3.声明Mapper
job.setMapperClass(WcMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 4.声明Reducer
job.setReducerClass(WcReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5.声明输入位置
FileInputFormat.setInputPaths(job, new Path("hdfs://yun01:9000/wcdata/words.txt"));
// 6.声明输出位置
FileOutputFormat.setOutputPath(job, new Path("hdfs://yun01:9000/wcresult"));
// 7.启动作业
job.waitForCompletion(true);
}
} 将程序成打成jar,提交到集群中运行。
集群搭建可以参见:伪分布式集群搭建点我、完全分布式集群搭建点我
以下的介绍中,我将使用k1代替mapper第一次输入的数据key,v1代表mapper第一次输入的数据的value值,k2代表mapper输出数据的key,v2代表mapper输出数据的value;k3代表reducer接收数据的key,v3代表reducer接收数据的value;
2>Eclipse导出jar包
导出jar包有下面四个页面:
右键项目-export:搜索jar-java-JAR file-next。
选择要打包的项目-去掉.classpath和.project的勾选-JAR file:输出路径及jar包名字-next。
next。
main class:选择主类-Finish。
hadoop jar xxx.jar
环境问题
在eclipse中使用hadoop插件开发mapreduce可能遇到的问题及解决方案:
①空指针异常
本地hadoop缺少支持包,将winutils和hadoop.dll(及其他)放置到eclips关联的hadoop/bin下,并将hadoop/bin配置到PATH环境变量中。如果还不行,就再放一份到c:/windows/system32下。
②不打印日志
在mr程序下放置一个log4j.properties文件。
③null\bin\winutils.exe
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
解决方法1:
配置HADOOP_HOME环境变量,可能需要重启电脑。
解决方法2:
如果不想配置环境变量,可以在代码中写上。
System.setProperty("hadoop.home.dir", "本机hadoop地址");
④ExitCodeException
本地的Hadoop程序中hadoop-2.7.1\share\hadoop\common\hadoop-common-2.7.1.jar中NativeIO这个类加载不出来,需要将这个类重新打包。
2.map任务处理
文件逻辑切片,每一个切片对应一个Mapper。
Mapper读取输入切片内容,每行解析成一个k1、v1对(默认情况)。每一个键值对调用一次map函数。执行map中的逻辑,对输入的k1、v1处理,转换成新的k2、v2输出。
3.shuffle阶段
分配map输出的数据到reduce其中会将k2、v2转换为k3、v3。
中间包括buffer、split、partition、combiner、grouping、sort、combiner等操作。
4.reduce任务处理
输入shuffle得到的k3、v3执行reduce处理得到k4、v4,把k4、v4写出到目的地。
3、MR内部执行流程
MR可以单独运行,也可以经由YARN分配资源运行。这里先简单说一下Yarn,后面会有具体讲Yarn的文章更新。
YARN框架的组成:
1.0版本:JobTracker、2.0版本:ResourceManager。
1.0版本:TaskTracker 、2.0版本:NodeManager。
Mapper、Reducer。
1.运行Job
客户端提交一个mr的jar包给JobClient。
提交方式为执行Hadoop的提交命令:
hadoop jar [jar包名]2.请求作业
JobClient通过RPC和ResourceManager进行通信,表明要发起一个作业,ResourceManager返回一个存放jar包的地址(HDFS)和jobId。
3.上传作业资源
client将jar包和相关配置信息写入到HDFS指定的位置。
path=hdfs上的地址+jobId。
4.提交作业
当作业资源上传完毕之后,Client联系ResourceManager提交作业任务。此处提交的作业任务,只是任务的描述信息,不是jar包。
任务描述包括:jobid,jar存放的位置,配置信息等等。
5.初始化作业
ResourceManager得到Client提交的作业任务信息,会根据信息进行作业初始化,创建作业对象。
6.计算分配任务
创建好作业对象之后,ResourceManager读取HDFS上的要处理的文件,开始计算输入分片split,规划出Mapper和Reducer的数量,规划分配任务方案,通常采用本地化策略将任务分配给NodeManager。ResourceManager不会主动联系NodeManager,而是等待NodeManager心跳报告。
本地化任务策略:数据在那个节点上存储,就将任务交给那个节点。
7.领取任务
NodeManager通过心跳机制领取任务。这里领取的只是任务的描述信息(即数据的元数据)。通过任务描述信息,NodeManager访问hdfs获取所需的jar,配置文件等。准备进行任务工作。
8.进行任务
当准备任务完成之后,NodeManager会启动一个单独的java child子进程:worker进程,让worker进程来执行具体的任务。Worker中运行指定的Mapper或Reducer,最终将结果写入到HDFS当中。
这里另外启动一个进程来执行具体的任务,其实可以算是NodeManager的一个自保机制,因为Mapper和Reducer的代码是工程师编写的,这里面避免不了会存在导致线程崩溃的代码,或者意外情况,导致线程中断。这样做可以保护NodeManager一直处于正常工作状态,不会因为执行Mapper和Reducer代码导致NodeManager死亡。NodeManager还有重启任务的机制,保证在意外情况下导致Mapper和Reducer执行中断,可以完成任务。
整个过程传递的是代码,而不是数据。即数据在哪里,就让运算发生在哪里,减少对数据的移动,提高效率。
4、MR的序列化机制
由于集群工作过程中需要用到RPC操作,所以想要MR处理的对象的类必须可以进行序列化/反序列化操作。
Hadoop并没有使用Java原生的序列化,它的底层其实是通过AVRO实现序列化/反序列化,并且在其基础上提供了便捷API。
1.AVRO API
之前用到的Text、LongWritable、IntWritable……其实都是在原有类型上包装了一下,增加了AVRO序列化、反序列化的能力。
我们也可以使用自己定义的类型来作为MR的kv使用,要求是必须也去实现AVRO序列化反序列化。
1>Job
用于整个作业的管理。
①重要方法
1)getInstance(Configuration conf,String Jobname);
获取job对象。
2)setJarByClass(class<?> cal);
设置程序入口。
3)setMapperClass(class<?> cal);
设置Mapper类。
4)setMapOutputKeyClass(class<?> cal);
设置Mapper类输出的key值的类型。
5)setMapOutputValueClass(class<?> cal);
设置Mapper类输出的value值类型。
6)setReducerClass(class<?> cal);
设置Reducer类。
7)setOutputKeyClass(class<?> cal);
设置Reducer类输出的key值类型,如果Mapper类和Reducer类的输出key值一样,可以只设置这一个。
8)setOutputValueClass(class<?> cal);
设置Reducer类输出的value值类型,如果Mapper类和Reducer类的输出value值类型型一样,可以只设置这一个。
9)waitForCompletion(boolean fg);
开启job任务。true开启,false关闭。
2>Writable
序列化标识接口,需要实现里面的write()和readFileds()两个方法。
①重要方法
1)write(DataOutput out);
此方法用于序列化,属性的序列化顺序要和反序列化顺序一致。
2)readFields(DataInput in);
此方法是用于反序列化的方法,属性的反序列化顺序要和序列化顺序一致。
3>WritableComparable
此接口用于序列化和排序的标识接口。WritableComparable = Writable + Comparable。
①重要方法
1)write(DataOutput out);
2)readFields(DataInput in);
3)compareTo();
此方法用来实现排序比较的,java基础有讲过。返回负数表明调用此方法的对象小,返回0表明两个对象相等,返回整数表明调用此方法的对象大。
4>应用
如果对象只是用作k1、k4或value则只实现Writable接口即可。
如果对象用作k2、k3则类除了实现Writable接口外还要实现Comparable接口,也可以直接实现WritableComparable效果是相同的。
案例
统计流量(文件:flow.txt)自定义对象作为keyvalue。
文件样例:
13877779999 bj zs 2145
13766668888 sh ls 1028
13766668888 sh ls 9987
13877779999 bj zs 5678
13544445555 sz ww 10577
13877779999 sh zs 2145
13766668888 sh ls 99871>FlowBean
写一个Bean实现Writable接口,实现其中的write和readFields方法,注意这两个方法中属性处理的顺序和类型。
public class FlowBean implements Writable {
private String phone;
private String addr;
private String name;
private long flow;
public FlowBean() {}
public FlowBean(String phone, String addr, String name, long flow) {
super();
this.phone = phone;
this.addr = addr;
this.name = name;
this.flow = flow;
}
//对应的get/set方法,这里省略
//对应的toString()
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phone);
out.writeUTF(addr);
out.writeUTF(name);
out.writeLong(flow);
}
@Override
public void readFields(DataInput in) throws IOException {
this.phone = in.readUTF();
this.addr = in.readUTF();
this.name = in.readUTF();
this.flow = in.readLong();
}
}编写完成之后,这个类的对象就可以用于MR了。
2>FlowMapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1.获取行,按照空格切分
String line = value.toString();
String attr[] = line.split(" ");
// 2.获取其中的手机号,作为k2
String phone = attr[0];
// 3.封装其他信息为FlowBean,作为v2
FlowBean fb = new FlowBean(attr[0], attr[1], attr[2], Long.parseLong(attr[3]));
// 4.发送数据。
context.write(new Text(phone), fb);
}
}3>FlowReducer
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
public void reduce(Text k3, Iterable<FlowBean> v3s, Context context) throws IOException, InterruptedException {
// 1.通过k3获取手机号
String phone = k3.toString();
// 2.遍历v3s累计流量
FlowBean fb = new FlowBean();
Iterator<FlowBean> it = v3s.iterator();
while (it.hasNext()) {
FlowBean nfb = it.next();
fb.setAddr(nfb.getAddr());
fb.setName(nfb.getName());
fb.setPhone(nfb.getPhone());
fb.setFlow(fb.getFlow() + nfb.getFlow());
}
// 3.输出结果
context.write(new Text(phone), fb);
}
}4>FlowDriver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowDriver {
public static void main(String[] args) throws Exception {
// 1.创建作业对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
// 2.设置入口类
job.setJarByClass(FlowDriver.class);
// 3.设置mapper类
job.setMapperClass(FlowMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 4.设置Reducer类
job.setReducerClass(cn.tedu.flow.FlowReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 5.设置输入位置
FileInputFormat.setInputPaths(job, new Path("hdfs://yun01:9000/flowdata"));
// 6.设置输出位置
FileOutputFormat.setOutputPath(job, new Path("hdfs://yun01:9000/flowresult"));
// 7.启动作业
if (!job.waitForCompletion(true))
return;
}
}5、排序
Map执行过后,在数据进入reduce操作之前,数据将会按照K3进行排序,利用这个特性可以实现大数据场景下排序的需求。
1.案例:计算利润
计算利润,进行排序(文件:profit.txt)。
数据样例:
1 ls 2850 100
2 ls 3566 200
3 ls 4555 323
1 zs 19000 2000
2 zs 28599 3900
3 zs 34567 5000
1 ww 355 10
2 ww 555 222
3 ww 667 1921>分析
此案例,需要两个MR操作,合并数据、进行排序。
在真实开发场景中 对于复杂的业务场景,经常需要连续运行多个MR来进行处理。
2>代码实现
①ProfitMapper
public class ProfitMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1.获取行,按照空格切分
String line=value.toString();
String attr[]=line.split(" ");
// 2.获取人名作为k2
String name=attr[1];
// 3.获取当月收入和支出计算利润
int sum=Integer.parseInt(attr[2])-Integer.parseInt(attr[3]);
// 4.输出数据
context.write(new Text(name), new IntWritable(sum));
}
}②ProfitReducer
public class ProfitReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text k3, Iterable<IntWritable> v3s, Context context) throws IOException, InterruptedException {
// 1.通过k3获取人名
String name = k3.toString();
// 2.遍历v3累计利润
Iterator<IntWritable> it = v3s.iterator();
int cprofit = 0;
while (it.hasNext()) {
cprofit += it.next().get();
}
// 3.输出数据
context.write(new Text(name), new IntWritable(cprofit));
}
}③ProfitDriver
public class ProfitDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "profit_job");
job.setJarByClass(ProfitDriver.class);
job.setMapperClass(ProfitMapper.class);
job.setReducerClass(ProfitReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://yun01:9000/pdata"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://yun01:9000/presult"));
if (!job.waitForCompletion(true))
return;
}
}④ProfitBean
创建Bean对象实现WritableComparable接口实现其中的write readFields compareTo方法,在Map操作时,将Bean对象作为Key输出,从而在Reduce接受到数据时已经经过排序,而Reduce操作时,只需原样输出数据即可。
public class ProfitBean implements WritableComparable<ProfitBean> {
private String name;
private int profit;
public ProfitBean() {
}
public ProfitBean(String name, int profit) {
this.name = name;
this.profit = profit;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getProfit() {
return profit;
}
public void setProfit(int profit) {
this.profit = profit;
}
@Override
public String toString() {
return "ProfitBean [name=" + name + ", profit=" + profit + "]";
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(profit);
}
@Override
public void readFields(DataInput in) throws IOException {
this.name=in.readUTF();
this.profit=in.readInt();
}
@Override
public int compareTo(ProfitBean profit) {
return this.profit-profit.getProfit()<=0?1:-1;
}
}⑤ProfitSortMapper
public class ProfitSortMapper extends Mapper<LongWritable, Text, ProfitBean, NullWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String attr[]=line.split("\t");
ProfitBean pb=new ProfitBean(attr[0],Integer.parseInt(attr[1]));
context.write(pb, NullWritable.get());
}
}⑥ProfitSortReducer
public class ProfitSortReducer extends Reducer<ProfitBean, NullWritable, Text, IntWritable> {
public void reduce(ProfitBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
String name=key.getName();
int profit=key.getProfit();
context.write(new Text(name), new IntWritable(profit));
}
}此案例中也可以没有Reducer,MapReduce中可以只有Map没有Reducer,如果不配置Reduce,hadoop会自动增加一个默认Reducer,功能是原样输出数据。
⑦ProfitSortDriver
public class ProfitSortDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "pro_sort_job");
job.setJarByClass(ProfitSortDriver.class);
job.setMapperClass(ProfitSortMapper.class);
job.setMapOutputKeyClass(ProfitBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(ProfitSortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://yun01:9000/presult"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://yun01:9000/psresult"));
if (!job.waitForCompletion(true))
return;
}
}6、Partitioner分区
分区操作是shuffle操作中的一个重要过程,作用就是将map的结果按照规则分发到不同reduce中进行处理,从而按照分区得到多个输出结果。
1.Partitionner
Partitioner是partitioner的基类,如果需要定制partitioner也需要继承该类。
HashPartitioner是mapreduce的默认partitioner。计算方法是:
which reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
注:默认情况下,reduceTask数量为1。
很多时候MR自带的分区规则并不能满足我们需求,为了实现特定的效果,可以需要自己来定义分区规则。
2.案例:改造流量统计
改造如上统计流量案例,根据不同地区分区存放数据。
1>分析
开发Partitioner代码,写一个类实现Partitioner接口,在其中描述分区规则。
2>代码实现
①FlowBean
public class FlowBean implements Writable{
private String phone;
private String addr;
private String name;
private long flow;
//……无参、有参构造……
//……get/set……
//……toString()……
//……read/write……
}②FlowMapper
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context)
throws IOException, InterruptedException {
String line=value.toString();
String attr[]=line.split(" ");
String phone=attr[0];
FlowBean fb=new FlowBean(attr[0], attr[1], attr[2], Integer.parseInt(attr[3]));
context.write(new Text(phone), fb);
}
}③FlowReducer
public class FlowReducer extends Reducer<Text, FlowBean, Text, NullWritable> {
@Override
protected void reduce(Text k3, Iterable<FlowBean> v3s, Reducer<Text, FlowBean, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
Iterator<FlowBean> it=v3s.iterator();
FlowBean fb=new FlowBean();
while(it.hasNext()){
FlowBean nextFb=it.next();
fb.setAddr(nextFb.getAddr());
fb.setName(nextFb.getName());
fb.setPhone(nextFb.getPhone());
fb.setFlow(fb.getFlow()+nextFb.getFlow());
}
Text t=new Text(fb.getName()+" "+fb.getPhone()+" "+fb.getAddr()+" "+fb.getFlow());
context.write(t, NullWritable.get());
}
}④FlowCityPartitioner
public class FlowCityPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text k2, FlowBean v2, int num) {
// 1.获取流量所属地区信息
String addr = v2.getAddr();
// 2.根据地区返回不同分区编号 实现 不同Reducer处理不同 地区数据的效果
switch (addr) {
case "bj":
return 0;
case "sh":
return 1;
case "sz":
return 2;
default:
return 3;
}
}
}⑤FlowDriver
public class FlowDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Flow_Addr_Job");
job.setJarByClass(cn.tedu.flow2.FlowDriver.class);
job.setMapperClass(cn.tedu.flow2.FlowMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setReducerClass(cn.tedu.flow2.FlowReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//--设置Reducer的数量 默认为1
job.setNumReduceTasks(4);
//--设置当前 job的Partitioner实现根据城市分配数据
job.setPartitionerClass(FlowCityPartitioner.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop:9000/f2data"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop:9000/f2result"));
if (!job.waitForCompletion(true))
return;
}
}Partitioner将会将数据发往不同reducer,这就要求reducer的数量应该大于等于Partitioner可能的结果的数量,如果少于则在执行的过程中会报错。
7、Combiner合并
每一个MapperTask可能会产生大量的输出,combiner的作用就是在MapperTask端对输出先做一次合并,以减少传输到reducerTask的数据量。
combiner是实现在Mapper端进行key的归并,combiner具有类似本地的reduce功能。
如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成在Mapper的本地聚合,从而提升速度。
job.setCombinerClass(WCReducer.class);1.案例:改造WordCount
改造WordCount案例,增加Combiner,从而提高效率。
1>WcMapper
public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String attr[] =line.split(" ");
for(String w:attr){
context.write(new Text(w), new IntWritable(1));
}
}
}2>WcReducer
public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3s,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
Iterator<IntWritable> it=v3s.iterator();
int count=0;
while(it.hasNext()){
count+=it.next().get();
}
context.write(k3, new IntWritable(count));
}
}3>WcDriver
public class WcDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Wc_addr_Job");
job.setJarByClass(cn.tedu.wc2.WcDriver.class);
job.setMapperClass(cn.tedu.wc2.WcMapper.class);
job.setReducerClass(cn.tedu.wc2.WcReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//为当前job设置Combiner
job.setCombinerClass(WcReducer.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop:9000/wdata"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop:9000/wresult"));
if (!job.waitForCompletion(true))
return;
}
}MapReduce的重点树shuffle的过程,这个我会单独出一篇文章进行讲解。