pandas库是python中专门进行人工智能计算的库,在使用前首先要用import语句引入该库,例子如下,引入pandas打印版本号0.25.2:
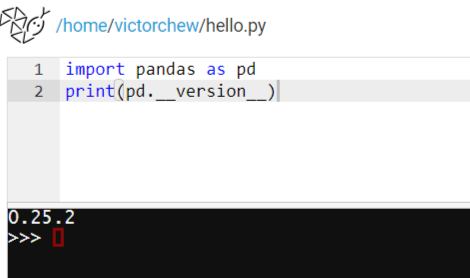
在pandas中series是基本的数据结构,相当于线性代数中的列向量,下面是建立series的例子,在下面的结果截图中左边那列数字是列向量的行标(从0开始),右边那列数字是列向量中各行的数值。:
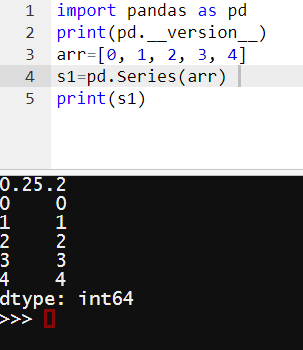
下面的例子是通过字典来创建列向量,左边的a,b,c,d,e是列向量的行标,右边的一列数字是列向量中各个行的值。

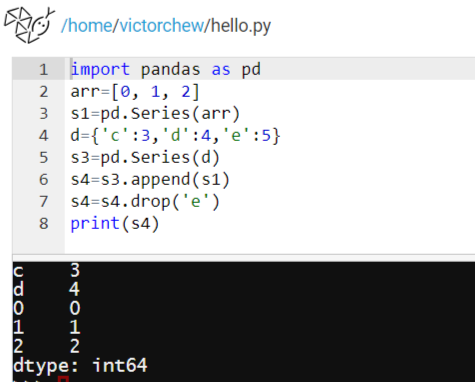
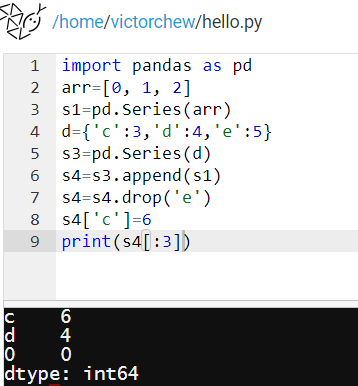
两个列向量可以拼接在一起形成更长的列向量:

扫描二维码关注公众号,回复:
11212432 查看本文章

可以使用drop语句来删除其中的e行:
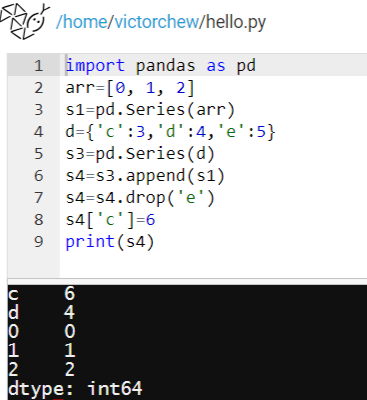
可以更改其中某个元素的值,把c行的值改为6:
可以用冒号语法输出s4列向量中前三行的元素的值:
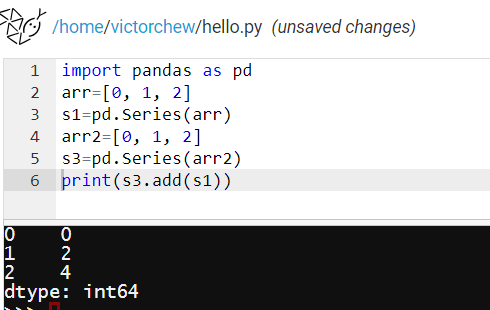
向量加法可以用add函数来实现:
类似的操作还有s3.sub(s1),s4.mul(s3),s4.div(s3)对应着减法,乘法和除法。

上面的代码可以对列向量求和,类似的函数还有max,min,median等函数。在pandas中series创建向量,dataframe可以创建一个二维数组(矩阵):

在上面的图中dates是行标,利用date_range函数创建6个日期,columns是列表,这个6行四列的矩阵里的元素值用numpy库中的randn函数创建,
该函数是生成一个六行四列的随机矩阵,矩阵里的每个随机数遵循标准正态分布。
下面这个例子是利用python字典创建一个二维矩阵:
