#Python中统计字典元素的个数
#首先我们可以来看这样一段程序

#下面是我们熟知的字典对象里面get方法

#使用格式:D.get(k,d),D为对象,k为指定键,d是你指定的值,指定值是输出的值,即字典里面的value元素
#注意,这里面是输出的值,而不是键,即字典里面的value****(重要的事情需要多加强调)

既然这样,我们是不是可以做点啥呢,好兴奋呀ヾ(o◕∀◕)ノヾ
**#我们接着来看一下上面的代码
**#for ch in z:
d[ch]=d.get(ch,0)+1**
#首先遍历z里面的元素,找到以后,输出0,但是立马就加1,怎么样,现在ch的值就是1了
#如果后面还有的话,是不是就又加1了呢,这样不就实现了统计的功能吗**
#(记住哦,ch是键,是永远不会变的)
#这样是不是很奇妙,结合字典里面的get方法,加循环的功能,实现了统计的功能
字典和循环结合,优势互补,实现了1+1>2的功能,是不是很奇妙
其实,Python里面类似这样的优势互补的程序合用还有很多,比如之前我们在列表里面学的remove方法
remove方法可以删除列表里面的指定元素,但是缺陷就在于,当要删除列表里面的元素有多个的时候,一次只能删除左边的第一个,而且由于Python的自动保存功能,有很多时候,使用remove方法,可能无法达到理想中要删除元素的功能,例如下面这个程序:
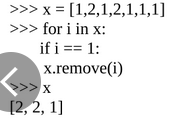
但是大家可以考虑一下,remove可以删除列表里面的指定元素,元素过多是删除左边第一个,我们可以转化思路,可以利用列表索引的方法,来代替指定元素,例如下列代码:

这样的结合方式是不是利用索引的方法将remove的缺点给弥补了,是不是特别奇妙

Python里面这样的结合方式还有很多很多,每一种方法都有它好的一面,也有它不好的一面,就像我们每一个人,都有自己的优点,也都有自己的缺点,但是只要我们合理利用,都可以创造属于自己的美好人生,大家说:对吗?
最后,祝福大家,在Python这一条路上,可以越走越远,让科技更好的服务于我们的生活!
记住:人生苦短,我用Python!
