1. Introduction
在CNN的计算过程中,各级存储层次(DRAM、on-chip global buffer、Regs)之间的数据传输很复杂,从功耗的观点来看,当前的CNN加速器是通信主导的,最小化通信是提高CNN加速器能效的关键。
最大化数据复用可以减少通信,数据复用依赖于卷积数据流,当前研究设计的数据流基于直觉/启发式的分析,不能保证是最优的。
在给定的硬件资源(On-chip memory)下,搜索出一种数据流和架构最小化通信具有实用意义。
2. Background
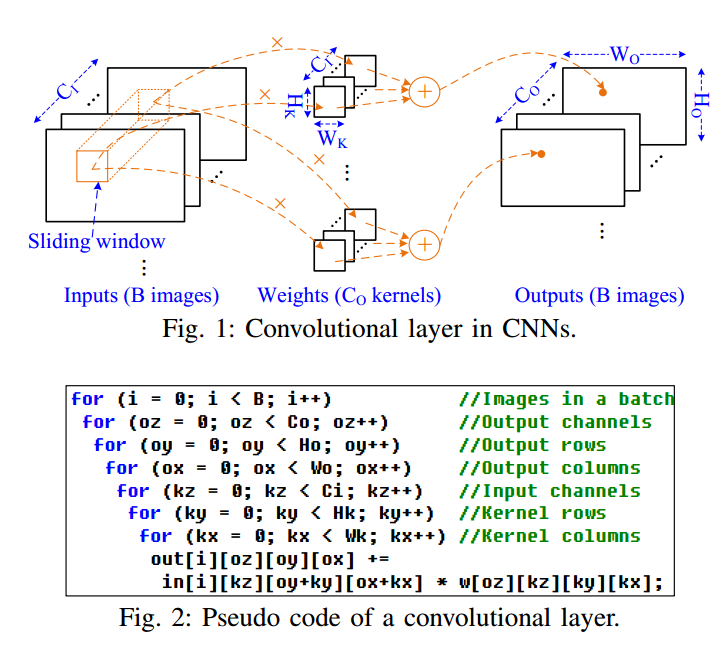
图2展示了卷积的基本计算过程,它是一个7层的循环,包含对多种数据复用方式,如输入复用(InR,一个输入被多个卷积核使用)、卷积窗复用(WndR,一个输入被多个重叠的滑动窗口复用)、权重复用(WtR,一个权重被多个输入使用)、输出复用(OutR,在整个计算过程中,输出驻留在片上)。