HDFS 深入 理解
一. namenode和datanode的功能
namenode: 管理文件的元数据
处理来自客户端的请求
datanode: 保存数据本身
少量的元数据: 块的长度, 校验和, 时间戳
二. namenode从集群中的每个datanode周期性的接受心跳信息和块报告
- 心跳信息
心跳是每3秒一次
心跳返回结果带有NameNode给该DataNode的命令如(复制块,删除)
如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。 - 块报告
DataNode启动后向NameNode注册,通过后,
周期性(1小时)的向NameNode上报所有的块信息。
三. 数据块损坏处理
当DataNode读取block的时候,它会计算checksum,与block创建时值不一样,说明该block已经损坏。
Client读取其它DN上的block。
NameNode标记该块已经损坏,然后复制block达到预期设置的文件备份数
DataNode 在其文件创建后三周验证其checksum
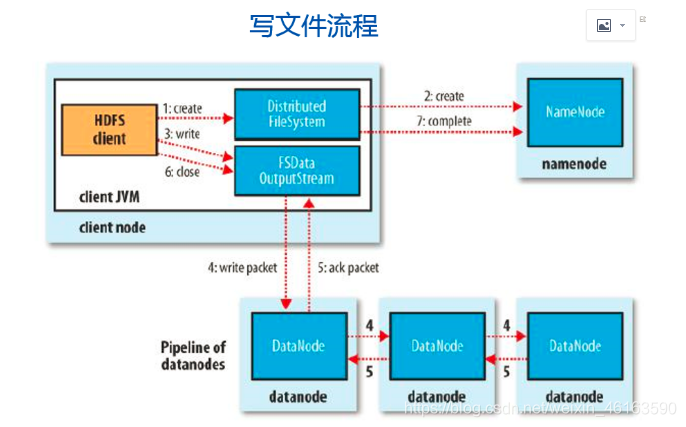
四、HDFS的读写流程

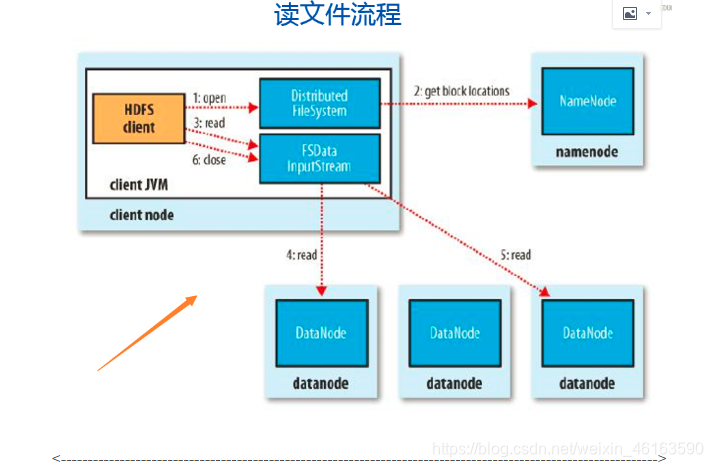
 、
、
HDFS的高可用?
HDFS的高可用指的是HDFS持续对各类客户端提供读、写服务的能力,因为客户端对HDFS的读、写操作之前都要访问name node服务器,客户端只有从name node获取元数据之后才能继续进行读、写。所以HDFS的高可用的关键在于name node上的元数据持续可用。
1 HDFS的运行机制?
HDFS集群中的节点分为两种角色:
一种角色负责管理整个集群的元数据,是名称节点(name node);
另一种角色负责存储文件数据块和管理文件数据块,是数据节点(datanode)
【转载注明出处,尊重原创 】
【作者水平有限,如有错误欢迎指正 .】

