K8s、CRI与container
https://zhuanlan.zhihu.com/p/102897620
本篇文章梳理一下 K8s 与 CRI(Container Runtime Interface)、contaier 之间的关系。首先,我们需要知道 K8s 大体的工作流程原理。
K8s 如何工作
在 K8s 中,存在一个控制面板,也就是我们所说的 master node, 上面运行着 apiserver、controllerManager、kubeScheduler、kubedns 等组件。当我们想要创建一个应用(deployment、statefulset)时,主要流程如下:
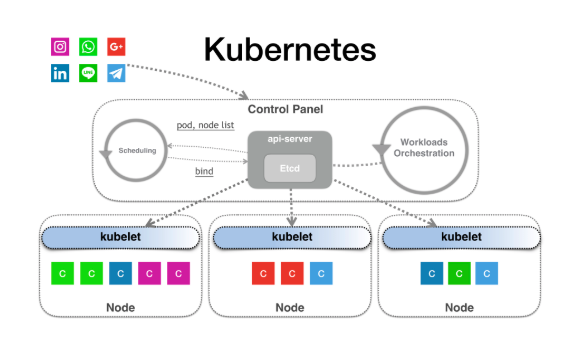
- 通过 kubectl 命令向 apiserver 提交, apiserver 将资源保存在 etcd 中
- controllermanager 通过控制循环,获取新创建的资源,并创建 pod 信息。注意这里只创建pod,并未调度和创建容器
- kube-scheduler 也会循环获取新创建但未调度的pod,并在执行一系列调度算法后,将 pod 绑定到一个 node上,并更新 etcd 中的信息。具体方式是在 pod 的 spec 中加入
nodeName字段。 - Kubelet监视所有Pod对象的更改。当发现Pod已绑定到Node,并且绑定的Node本身时,Kubelet会接管所有后续任务,包括创建 pod 网络,container等。
- kubelet 会通过 CRI 调用 container runtime 创建 pod 中的 container。
下图中 containerd 作为 high-level runtime,并调用 runC 创建 namespace 隔离和 cgroup 资源限制。

Container Runtime Interface (CRI)
CRI 在 Kubernetes 1.5 中引入,并充当 kubelet 和容器运行时之间的桥梁。 期望与Kubernetes集成的高级容器运行时将实现CRI。预期runtimes将负责镜像的管理,并支持Kubernetes pods,以及管理各个容器。CRI仅具有一个功能:对于Kubernetes,它描述了容器应具有的操作以及每个操作应具有的参数。
CRI 是以容器为中心的API,设计 CRI 的初衷是不希望向容器(比如 docker)暴露 pod 信息或 pod 的api,Pod始终是Kubernetes编排概念,与容器无关,因此这就是为什么必须使该API以容器为中心。
CRI 工作在 kubelet 与 container runtime之间,目前常见的 runtime 有:
- docker: 目前 docker 已经将一部分功能移至 containerd 中,CRI 可以直接与 containerd 交互。 因此,Docker本身并不需要支持CRI(containerd已经支持)。
- containerd:containerd 可以通过 shim 对接不同 low-level runtime,这部分后文会详细介绍
- cri-o:一种轻量级的 runtime,支持runc和Clear Containers作为low-level runtimes。
CRI 是如何工作的
CRI 大体包含三部分接口:Sandbox 、 Container 和 Image,其中提供了一些操作容器的通用接口,包括 Create Delete List 等。
Sandbox 为 Container 提供一定的运行环境,这其中包括 pod 的网络等。 Container 包括容器生命周期的具体操作,Image 则提供对镜像的操作。
kubelet会通过 grpc 调用 CRI 接口,首先去创建一个环境,也就是所谓的 PodSandbox。当 PodSandbox 可用后,继续调用 Image 或 Container 接口去拉取镜像和创建容器。其中,shim 会将这些请求翻译为具体的 runtime API,并执行不同 low-level runtime 的具体操作。

PodSandbox
上文所说的 Sandbox 到底是什么东西呢? 我们从虚拟机和容器化两方面来看,这两者都使用 cgroups 做资源配额,而且概念上都抽离出一个隔离的运行时环境,只是区别在于资源隔离的实现。因此 Sandbox 是 K8s 为兼容不同运行时环境预留的空间,也就是说 K8s 允许 low-level runtime 依据不同的是实现去创建不同的 PodSandbox,对于 kata 来说 PodSandbox 就是虚拟机,对于 docker 来说就是 Linux namespace。当 Pod Sandbox 建立起来后,Kubelet 就可以在里面创建用户容器。当到删除 Pod 时,Kubelet 会先移除 Pod Sandbox 然后再停止里面的所有容器,对 container 来说,当 Sandbox 运行后,只需要将新的 container 的 namespace 加入到已有的 sandbox 的 namespace中。
在默认情况下, CRI 体系里,Pod Sandbox 其实就是 pause 容器。Kubelet 代码引用的 defaultSandboxImage 其实就是官方提供的 gcr.io/google_containers/pause-amd64 镜像。
shim v2
现在由于多种不同的 low-level runtime 的发展,比如 kata container 和 gVisor,其 shim 的实现方式均不同,需要在 CRI shim 与 low-level runtime 之间增加一层。 以 kata container 为例,依照上文 PodSandbox 所说,由于底层的 low-level runtime 不同,CRI shim 并不能直接用于操作 kata container。目前,kata container 所作的是提供一套 kata shim,可以将 CRI shim 的操作转换为对 kata 的操作。
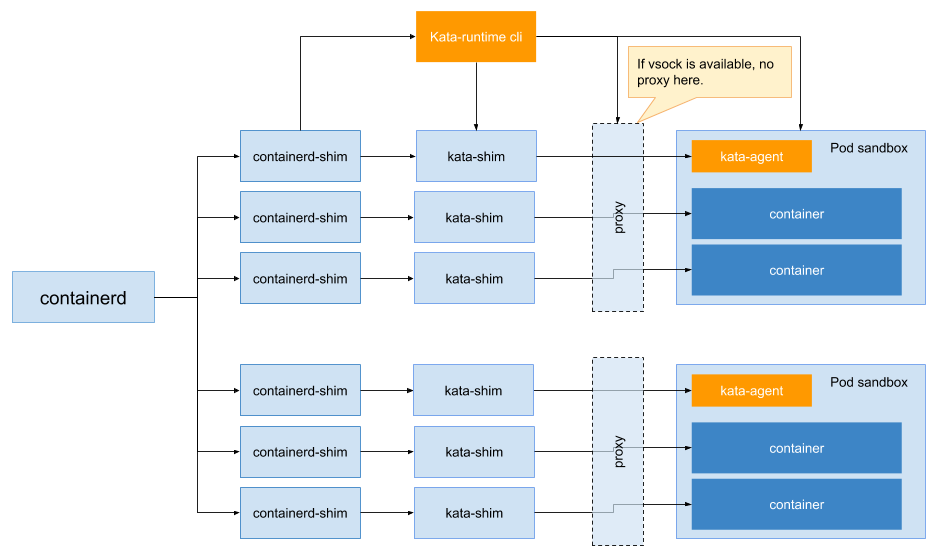
这么做的问题很明显,每个容器启动时,都需要 shim 做填充,而加入 kata shim 后需要将 shim 操作与 CRI 一一匹配,这会导致严重的性能损失。最终其实并不希望每个容器都匹配一个 shim,但是 sandbox 会匹配一个shim。此外这种方式对于其他 CRI 开发者不利。
Shim v2 希望在 containerd -> OCI runtime 中增加一层,提供各种运行时都可以实现的API,以在容器化的同时添加支持仍然可以控制状态和抽象动作。具体的proposal 见 issue:https://github.com/containerd/containerd/issues/2426
使用 shim v2 可以为每个 pod 指定一个 shim,当在创建的沙箱中调用start时,即启动了一个shim。但是,当下次调用该API时,即上一个CRI中的Container API,将不再启动一个shim。也就是说,一个 pod 只会启动一个shim,接管这个 pod 中所有 container 的 shim 操作。
还是以 kata 为例,当替换为 shim v2 之后,其调用如图:
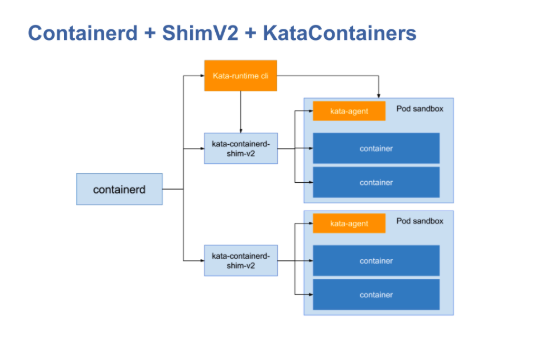
当执行create和start操作时,所有这些操作都映射在 Shimv2 的具体实现上,而不必考虑如何映射和实现CRI。
如果喜欢,请关注我的公众号,或者查看我的博客 http://packyzbq.coding.me. 我会不定时的发送我自己的学习记录,大家互相学习交流哈~