本文适合对Mysql有基本基础的童鞋食用,配合Mysql手册研究,基础实践效果更佳~
个人整理,心得体会,欢迎讨论指导.
这同志们在执行一些特殊重复性的sql语句的时候啊,需要频繁操作一大段的sql文件进行反复编辑。哥们前一阵就遇到一个某智慧消防设备心跳数据,大概每次操作都需要读取好多固定的sql进行操作,诶亚这就非常的烦人。这时候有人就说,封个公共类,直接用~!但是这使用太频繁了也不是个事儿,好几次sql进进出出磨磨蹭蹭来来回回…(已被和谐),非常耗费数据库资源。那么有没有一种操作,可以针对完成一段特定功能的SQL进行操作,而又集齐的节省资源呢?来来来,辩儿哥带你了解一下Mysql的“语句集”——存储过程。

一,使用变量的需求
变量的概念在流程控制中是最基础的知识了吧!(不了解的回炉一下子! )假设现在有这样一个简单的需求:编写存储过程,使用变量获取 users 表中 id 为 2 的用户名。怎么样!够简单吧!那么接下来就跟着哥们来实际盘一下:
在存储过程对于变量的用法依然是采用先声明后使用的流程,所以先使用 DECLARE 变量名 变量类型(长度) 默认值 的结构来声明一个变量:
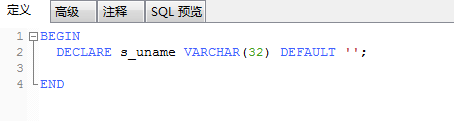
定义一个s_uname变量类型为字符型,长度限制32位,默认值为空。之后我们在select语句中使用INTO 可以将查询到的结果复制给我们定义好的变量。
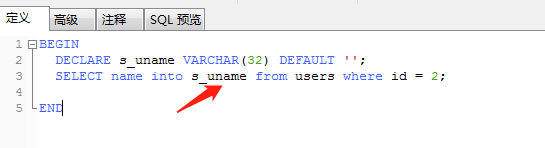
最后,查询变量的方式为 SELECT <变量名> ,查询赋值好的s_uname变量的值:
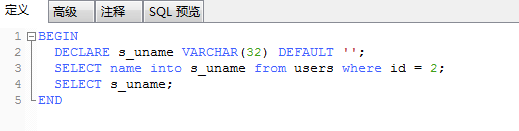
运行得出结果:
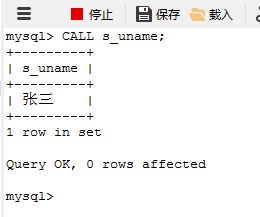
可以看到基于变量方式获取用户名的需求已经完成了,而且输出的字段名使我们定义好的变量名。OK~基本需求已经完成,这时候假如又新增了一个新的需求:要求在同一个存储过程中建立一个新的结果集,同时查询出goods表中id字段值为1的uname字段的时候,应该怎么做?咱们继续往下走。在存储过程中如果需要生成新的结果集,则需要在其内部增加新的 BEGIN—END 代码块,如下:

运行结果可得出:
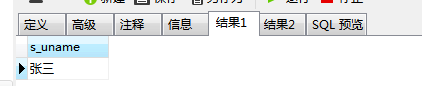
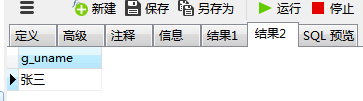
OK,这样我们就可以通过两个结果集来分别对多语句块内容进行查询。这个时候又要增加需求!要求在goods表中查询uname字段为users表中id为2的值(此处逻辑有些绕~多屡屡!)这个时候应该怎么办?有同学可能就说,那还不简单啊!代码块一中不是都定义好了变量么!直接拿过来用啊! 于是就得出了以下代码:

结果在运行保存的时候却一直在 报错 !
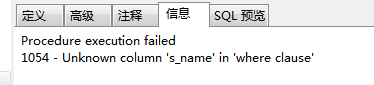
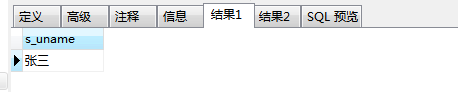
这是因为在存储过程中,每个变量都有属于自己的作用范围。 默认定义的变量作用范围为当前代码块 ,如果想在多个代码块中重复使用同一变量,则需要将变量设置为全局变量 ,将设置的变量写在所有内部BEGIN—END的最外层,即可定义为全局变量:

运行后即可得出正确查询结果:
二,总结
本篇主要重点为熟悉存储过程中变量的概念以及重点的使用,主要功能可概括为一下三点:
1.代码块中的作用范围只可以在自身代码中使用。
2.如果要在其他代码块中使用该变量需要将其变为全局变量。
3.将声明变量放在内部BEGIN-END中的最外层可使其变为全局变量。
想继续深入学习的同学可以继续关注辫儿哥接下来的坑文,不定期无规律看心情咕咕咕佛系更新!个人整理,欢迎批评指导~。

