一、什么是爬虫
反爬虫一些手段:
-
合法检测:请求校验(useragent,referer,接口加签名,等)
-
小黑屋:IP/用户限制请求频率,或者直接拦截
-
投毒:反爬虫高境界可以不用拦截,拦截是一时的,投毒返回虚假数据,可以误导竞品决策
-
-
目标数据
-
来源地址
-
结构分析
-
实现构思
-
操刀编码
-
-
基本手段
-
破解请求限制
-
请求头设置,如:useragant为有效客户端
-
控制请求频率(根据实际情景)
-
IP代理
-
签名/加密参数从html/cookie/js分析
-
-
破解登录授权
-
请求带上用户cookie信息
-
-
破解验证码
-
简单的验证码可以使用识图读验证码第三方库
-
-
-
解析数据
-
HTML Dom解析
-
正则匹配,通过的正则表达式来匹配想要爬取的数据,如:有些数据不是在html 标签里,而是在html的script 标签的js变量中
-
使用第三方库解析html dom,比较喜欢类jquery的库
-
-
数据字符串
-
正则匹配(根据情景使用)
-
-
-
from urllib.request import urlopen url = 'http://www.baidu.com'
response = urlopen(url) print(response.read().decode())
2、常见方法
-
-
第一个参数url即为URL,第二个参数data是访问URL时要传送的数据,第三个timeout是设置超时时间。
-
第二三个参数是可以不传送的,data默认为空None,timeout默认为 socket._GLOBAL_DEFAULT_TIMEOUT
-
第一个参数URL是必须要传送的,在这个例子里面我们传送了百度的URL,执行urlopen方法之后,返回一个response对象,返回信息便保存在这里面。
-
-
response.read()
-
read()方法就是读取文件里的全部内容,返回bytes类型
-
-
response.getcode()
-
返回 HTTP的响应码,成功返回200,4服务器页面出错,5服务器问题
-
-
response.geturl()
-
返回 返回实际数据的实际URL,防止重定向问题
-
-
response.info()
-
返回 服务器响应的HTTP报头
-
五、转码
大部分被传输到浏览器的html,images,js,css, … 都是通过GET方法发出请求的。它是获取数据的主要方法
例如:www.baidu.com 搜索
Get请求的参数都是在Url中体现的,如果有中文,需要转码,这时我们可使用
from urllib.parse import urlencode args ={ 'key':'咸鱼', 'ID' :1 } print(urlencode(args))

六、headers
一般网站都有防爬机制,添加headers可以一定程度上绕过,herders一般就是所说的http协议的请求头和响应头(具体不再赘述)
F12开发者工具,发送一个请求,选择控制台,选择日志,查看消息头
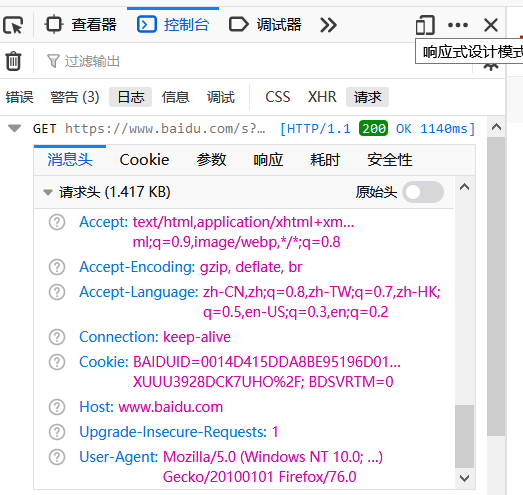
在爬虫脚本中
from urllib.request import Request,urlopen headers = { "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0' } #模拟这个浏览器访问 url = 'http://www.baidu.com' request = Request(url,headers=headers) response = urlopen(request) print(response.read().decode())
七、百度贴吧实战
访问贴吧,观察URL,GET方法,kw是搜索内容,ie是编码,pn以50的倍数控制页数,复制URL发现中文要转码,

思路:先模拟访问,再将爬取的页面保存文件
1)导入模块,搭建好框架
from urllib.request import Request, urlopen #请求模块 from urllib.parse import urlencode #转码
def get_html():
pass
def save_html():
pass
def main():
pass
if __name__ == '__main__':
main()
2)主函数,增加交互性,因为访问的页面不同,基URL+不同的参数拼接的URL由主函数传入URL给get_html()
content = input("请输入要爬取的内容")
num = input("请输入要爬取的页数")
base_url = 'https://tieba.baidu.com/f?'
for pn in range(int(num)):
args = {
"pn": pn * 50,
"kw": content
}
agrs = urlencode(args)
html_bytes = get_html(base_url.format(agrs))
3)爬取函数
def get_html(url):
headers = {
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0'
}
request = Request(url, headers=headers)
response = urlopen(request)
return response.read()由主函数传入一个URL,模拟访问,返回爬取的内容
4)主函数经过get_html爬取到内容保存在html_bytes变量中,然后在由主函数传给save_html函数文件名和文件内容
filename = "第" + str(pn + 1) + "页.txt" print("正在下载" + filename) html_bytes = get_html(base_url.format(args)) save_html(filename, html_bytes)
5)由主函数传入文件名和文件内容,save_html
def save_html(filename,html_bytes): with open(filename,"wb") as f: f.write(html_bytes)
6)完整代码
from urllib.request import Request, urlopen
from urllib.parse import urlencode
def get_html(url):
headers = {
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0'
}
request = Request(url, headers=headers)
response = urlopen(request)
print(response.read().decode())
return response.read()
def save_html(filename, html_bytes):
with open(filename, "wb") as f:
f.write(html_bytes)
def main():
content = input("请输入要下载的内容:")
num = input("请输入要下载多少页:")
base_url = "https://tieba.baidu.com/f?ie=utf-8&{}"
for pn in range(int(num)):
args = {
"pn": pn * 50,
"kw": content
}
args = urlencode(args)
filename = "第" + str(pn + 1) + "页.html"
print("正在下载" + filename)
html_bytes = get_html(base_url.format(args))
save_html(filename, html_bytes)
if __name__ == '__main__':
main()
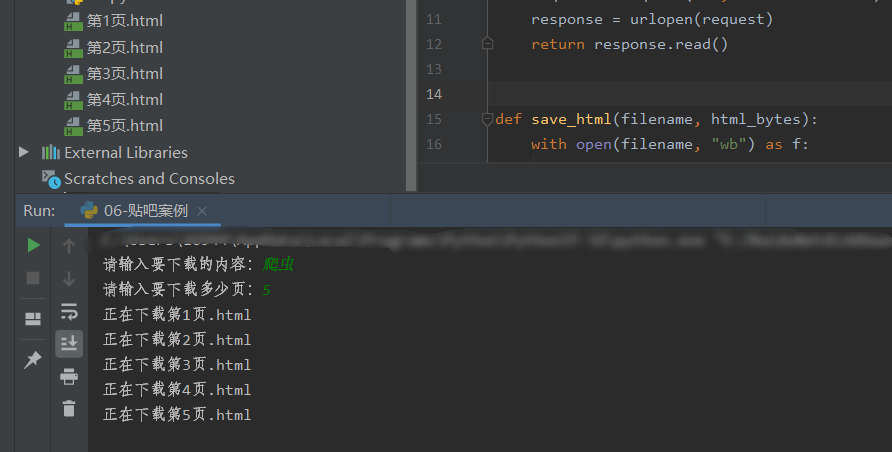
效果
参考
https://www.bilibili.com/video/BV1z541167mu
如果有错误和不足请联系,谢谢