今天,再起床之后,还处于迷糊的状态,手机突然滴滴一下,在除了家里人和女朋友会给我发消息的时代,我居然手机居然想了,以迅雷不及。。。我一个朋友跟我说,能不能出版一个Flink的资源和任务调度的文章,反正这个五一也没什么地方出去,那就整理一下吧,毕竟我的手把手带你玩转大数据系列就是为了玩转Flink才产生的。(因为五一回家没带电脑,主要靠官网进行编辑文档)
说起flink,那真的大名鼎鼎 啊,尤其是在阿里为了适应自己的业务将其重写并改名为Blink之后,Flink在程序员这一行,尤其是大数据人工智能领域,更是无人不知无人不晓了,说了这么多,可能真的有一部分小伙伴不太清楚Flink(比方说我身边在看我码字的这个小迷糊),那就先做一个Flink的介绍吧
注:Flink的相关我接触的时间也不是很长,这里只是按照自己的理解整理知识点,有问题可以随时和小编联系
关于Flink,我总结他为以下这样的一个定义:
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算
而对于Flink为什么可以战胜spark和Storm,被大家如此重视,我觉得也是我定义中提到的几个特点:
1、处理无界和有界的数据
无界流有一个开始但没有定义的结束。它们不会在生成时终止并提供数据。必须持续处理无界流,即必须在摄取事件后立即处理事件。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断结果完整性。
有界流具有定义的开始和结束。可以在执行任何计算之前通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理。
Apache Flink擅长处理无界和有界数据集。精确控制时间和状态使Flink的运行时能够在无界流上运行任何类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而产生出色的性能。
2、随机部署应用程序
Apache Flink是一个分布式系统,需要计算资源才能执行应用程序。Flink与所有常见的集群资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以设置为作为独立集群运行。
3、以任何比例运行应用程序
Flink旨在以任何规模运行有状态流应用程序。应用程序可以并行化为数千个在集群中分布和同时执行的任务。因此,应用程序可以利用几乎无限量的CPU,主内存,磁盘和网络IO。而且,Flink可以轻松维护非常大的应用程序状态。其异步和增量检查点算法确保对处理延迟的影响最小,同时保证一次性状态一致性。
· 应用程序每天处理数万亿个事件,
· 应用程序维护多个TB的状态,以及
· 应用程序在数千个内核的运行
4、利用内存的性能
有状态Flink应用程序针对本地状态访问进行了优化。任务状态始终保留在内存中,或者,如果状态大小超过可用内存,则保存在访问高效的磁盘上数据结构中。因此,任务通过访问本地(通常是内存中)状态来执行所有计算,从而产生非常低的处理延迟。Flink通过定期和异步检查本地状态到持久存储来保证在出现故障时的一次状态一致性
那这些是关于Flink能力超群的原因的一些理解,相信对于没有接触过Flink的老铁们,应该有一点点的认知了吧,那难道Flink就是散出的上面几个特点就能支撑他这么高的受欢迎度吗?肯定不是的,从,mapreduce到Spark,资源和任务调度,了解过底层的朋友们,他们是有一定的区别的,这样导致spark的任务处理效率会相对提升一些(后面会一点点的进行讲解),那Flink是不是也是这样的呢?我们结合官网(建议每一个刚学大数据的朋友多去看一下官网)去看一下Flink的任务调度流程,也是今天的中心
Flink中的执行资源是通过任务槽定义的。每个TaskManager将具有一个或多个任务槽,每个任务槽可运行一个并行任务管道。流水线由多个连续的任务,如在 第n与一个MapFunction一起的并行实例第n一ReduceFunction的并行实例。请注意,Flink经常同时执行连续的任务:对于流式程序,无论如何都会发生,但对于批处理程序,它经常发生。
下图说明了这一点。考虑一个具有数据源,MapFunction和ReduceFunction的程序。Source和MapFunction以4的并行度执行,而ReduceFunction以3的并行度执行。管线由序列Source-Map-Reduce组成。在具有2个TaskManager(每个都有3个插槽)的群集上,将按以下说明执行程序。
![]()

在内部,Flink限定通过SlotSharingGroup 和CoLocationGroup 哪些任务可以共享的狭槽(许可),分别哪些任务必须严格放置到相同的时隙。
JobManager数据结构
在作业执行期间,JobManager会跟踪分布的任务,决定何时安排下一个任务(或一组任务),并对完成的任务或执行失败做出反应。
JobManager接收JobGraph,它是由操作符(JobVertex)和中间结果(IntermediateDataSet)组成的数据流的表示。每个运算符都有属性,例如并行性和它执行的代码。另外,JobGraph具有一组附加的库,这些库对于执行操作员的代码是必需的。
JobManager将JobGraph转换为ExecutionGraph。ExecutionGraph是JobGraph的并行版本:对于每个JobVertex,每个并行子任务都包含一个ExecutionVertex。并行度为100的运算符将具有一个JobVertex和100 ExecutionVertices。ExecutionVertex跟踪特定子任务的执行状态。来自一个JobVertex的所有ExecutionVertices都保存在 ExecutionJobVertex中,该对象可跟踪操作员整体的状态。除了顶点之外,ExecutionGraph还包含IntermediateResult和IntermediateResultPartition。前者跟踪IntermediateDataSet的状态,后者是其每个分区的状态。
![]()
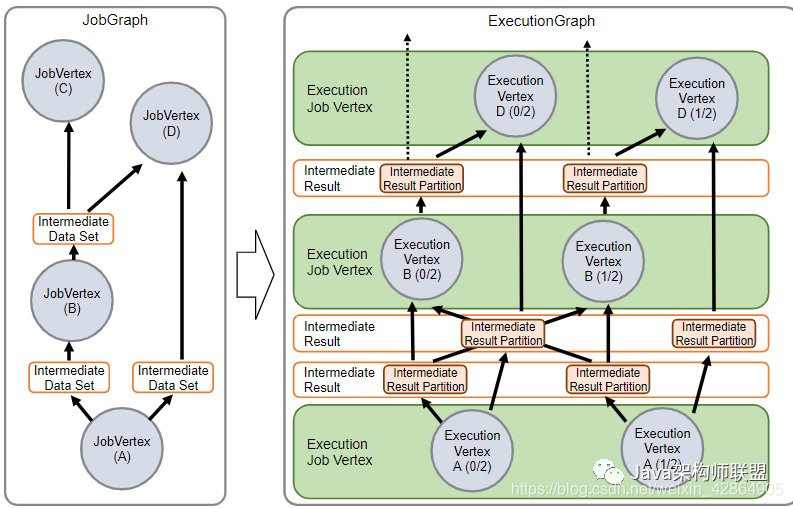
每个ExecutionGraph都有一个与之关联的作业状态。该作业状态指示作业执行的当前状态。
Flink作业首先处于创建状态,然后切换到运行状态,并在完成所有工作后切换到完成状态。发生故障时,作业会首先切换到失败,然后取消所有正在运行的任务。如果所有作业顶点均已达到最终状态并且该作业不可重新启动,则该作业将转换为failed。如果作业可以重新启动,则它将进入重新启动状态。作业完全重新启动后,它将达到创建状态。
如果用户取消作业,它将进入取消状态。这也需要取消所有当前正在运行的任务。一旦所有正在运行的任务都达到了最终状态,作业便转换为已取消状态。
与完成状态,取消状态和失败状态分别表示全局终端状态并因此触发清理作业的状态不同,挂起状态仅是本地终端状态。在本地终端意味着作业的执行已在相应的JobManager上终止,但是Flink群集的另一个JobManager可以从持久性HA存储中检索该作业并重新启动它。因此,达到挂起状态的作业不会被完全清除。
![]()

在执行ExecutionGraph的过程中,每个并行任务都经历了多个阶段,从创建到完成或失败。下图说明了状态以及状态之间的可能转换。一个任务可以执行多次(例如,在故障恢复过程中)。因此,在Execution中跟踪ExecutionVertex的执行。每个ExecutionVertex都有一个当前的Execution和先前的Execution。
![]()

而在上面我说过,Flink中的执行资源是通过任务槽定义的,那资源又是怎么分配的呢?接着看
Flink中每个真正执行任务的TaskManager都是一个JVM进程,其在多线程环境中执行一个或者多个子任务。为了控制一个JVM同时能运行的任务数量,flink引入了task slot的概念。每一个task solt代表了TaskManager资源的一个子集,比如,一个拥有3个solt的TaskManager,每一个solt可以使用1/3TM所管理的内存。进行资源分割意味着为子任务保留足够的内存,从而避免与其他子任务进行竞争。注意:当前solt还不能分割cpu资源,仅仅对内存进行了分割。
通过调整TMsolt的数量,用户可以确定子任务的隔离程度,比如,每个TM只设置一个solt,那么就意味着每一个任务组都在单独的JVM中执行。共用JVM的任务可以共享TCP链接,心跳消息,甚至可能共享数据集。
默认情况下,flink允许子任务共享slot只要这些子任务属于同一job。允许solt共享主要有以下两方面的好处:
-
flink计算一个job所需solt数量时,只需要确定所其最大并行度(parallelism),而不用计算每一个任务的并行度的总和。
-
能更好的利用资源,如果没有solt共享,那些资源需求不大的map子任务将和资源需求更大的window占用相同的资源。
当然Flink也提供了资源分组机制相关API,允许用户避免非预期的资源共享。
-
startNewChain 从此operator开始新的资源共享链
-
disableChaining 禁止把此operator加入到资源共享链中
-
slotSharingGroup 把此operator加入到指定的资源共享组中
资源分配逻辑
下图是fip6对架构改进过后JobManager与TaskManager主要交互图,可见job在执行中通过SlotProvider(即Scheduler)向ResourceManager申请资源,RM协调TaskManager满足JobManager资源请求。
![]()

下图是资源申请详细调用流程图:![]()

可见Execution在执行过程中,会根据是否设置资源共享组,考虑是否为多个Execution分配同一个Slot,其代码逻辑在SlotSharingManager中。资源分配的时候优先考虑SlotPool中是否有已分配资源能满足需求,如果不能再向ResourceManager申请。
Scheduler
-
通过allocateSlot向SlotPool申请资源
-
通过returnLogicSlot释放资源到SlotPool
![]()

SlotPool
![]()

与其他组件之间的交互:
-
Scheduler -> SlotPool: 调度器向SlotPool申请资源
-
SlotPool -> ResourceManager: SlotPool如果无法满足资源请求,向RM发起申请
-
JobMaster -> SlotPool: 从TaskManager获取的资源通过JobMaster分配给SlotPool
![]()

LogicalSlot
![]()

-
SingleLogicSlot包含一个SlotContext接口对象,PhysicalSlot接口继承了SlotContext
-
实现了PhysicalSlot.Payload接口,可以通过PhysicalSlot.tryAssignPayload把PhysicalSlot分配给LogicalSlot
PhysicalSlot
![]()

AllocatedSlot代表从TaskExecutor分配的资源一个资源槽,代表TaskExecutor上的一段资源。
如下代码把PhysicalSlot分配给LogicalSlot:
![]()

Slot资源共享
Flink实现了资源共享机制,相同资源组里的多个Execution可以共享一个Slot资源槽。具体共享机制又分两种:
-
CoLocationGroup: 保证把JobVertices的第n个运行实例和其他相同组内的JobVertices第n个实例运作在相同的slot中。
-
SlotSharingGroup: 允许不同的JobVertices的部署在相同的Slot中,但这是一种宽约束,只是尽量做到不能完全保证。
SlotSharingManager
每一个sharingGroup组用一个SlotSharingManager对象管理资源共享与分配。普通的slotsharing根据组内的JobVertices id 查找是否已有可以共享的Slot,如果有则直接使用,否则申请新的Slot。colocal类型根据组内每个ExecutionVertex关联的CoLocationConstraint查找是否有相同CoLocationConstraint约束已分配Slot可用(注:满足CoLocationConstraint约束的同一个资源共享组内的各节点相同序号n的并行实例,共享相同的CoLocationConstraint对象)
![]()

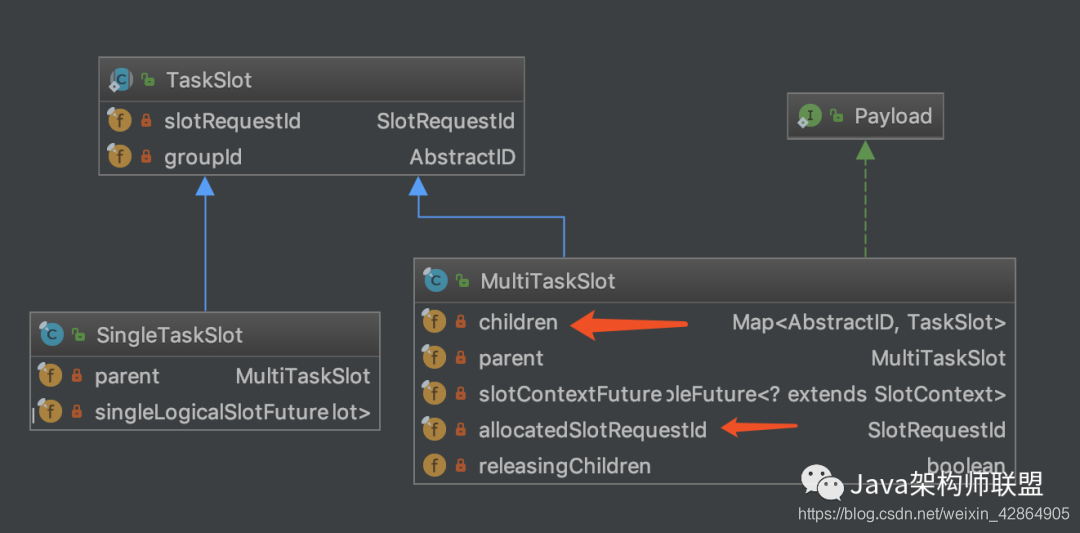
其他相关类
-
CoLocationConstraint
-
SingleLogicalSlot
-
MultiTaskSlot
![]()
![]()

至此,今天的flink就讲完了,后期会不断更新大数据相关技术,喜欢的朋友欢迎关注我,公众号:Java架构师联盟,不迷路哦

