1. SQL是经久不衰的基础
能经过时间考验的SQL,其优点毋庸置疑。
对于日常处理数据的朋友们(BI顾问,数据开发,数仓建模,数据研发,ETL工程师,AI工程师等),SQL更是一项非常重要的基础技能。
这里就不再列举SQL的优点了(很多),而只谈谈SQL使用中的一些问题,这里是系列文章的开篇:复杂SQL不易理解。
2. 讲故事
先讲个故事来示例,注:
示例中的表和场景都是经过简化的,实际中可能复杂非常多
示例的SQL都不保证是最优的写法
示例中的表结构也只是示例作用
数据开发工程师小吴在一家零售企业工作,他最近的工作就是帮助运营小胡分析客户画像。
公司有2张表,都是直接存储在最简单好用的 Postgresql 12.2 数据库中:
orders:订单表
customers:客户表
具体内容如下:
orders:
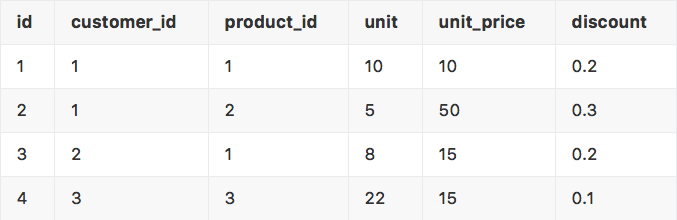
customers
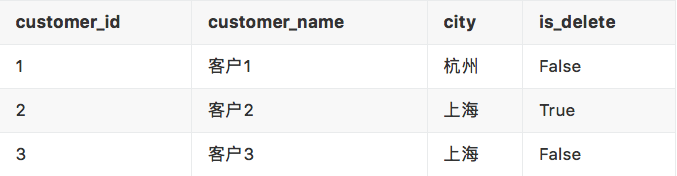
2.1 Step1 - 需要统计每个 customer_id 的总消费额
小吴快速的写了个SQL:
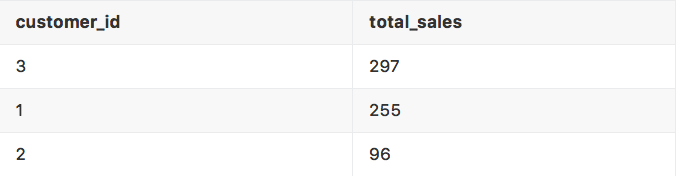
SELECTcustomer_id,SUM(unit * unit_price *(1- discount)) AS total_salesFROM ordersGROUP BY customer_idORDER BY total_sales DESC
注:小吴是处女座的,所以SQL还是要经过排版的, 数据也是排好序的。
得到了如下结果:
2.2 Step2 - 加上客户名和过滤掉非正常用户
小胡很快给出了反馈:
虽然你是开发,你熟悉于直接用ID称呼客户,但是我不习惯, 我需要看中文名字
这个客户ID 2, 我记得很清楚, 是我们的测试用户,上次我们上线后,我就把它从数据库中标记 is_delete 为 True 了,你需要去除掉
小吴说:好的
在解决了如下问题后:
查阅了JOIN的几种语法
通过表别名解决了错误:column reference "customer_id" is ambiguous
通过 max() 解决了错误:column "customers.customer_name" must appear in the GROUP BY clause or be used in an aggregate function
得到了如下SQL (注意:修改散落在多个地方)
SELECTorders.customer_id,MAX(customer_name) AS customer_name,SUM(unit * unit_price *(1- discount)) AS total_salesFROM orders JOIN customersON orders.customer_id = customers.customer_idWHERE customers.is_delete=FalseGROUP BY orders.customer_idORDER BY total_sales DESC
得到结果:

2.3 Step3 - 复杂的任务来了,要把客户分等级了
运营同学在阿里进修了一门《人人都可以当运营》课程,回来对数据小吴说:小吴呀,我们的会员体系要做起来呀,会员是我们以后上市的支柱,即使对我们的天使轮也是非常有用的呀。而且我学到了:“一定要结合客户所在地做会员分级”,所以,我决定:
对于所在地在”上海“的客户:如果他/她的消费额 >= 300, 那么他/她是白金会员,如果在区间 [100, 300), 则是黄金会员,否则就是普通会员
对于所在地为”杭州“的客户:如果他/她的消费额 >= 250, 那么他/她是白金会员,如果在区间 [80, 250), 则是黄金会员,否则就是普通会员
小吴这下要好好考虑这个问题了。
2.3.1 同一层SQL上改
首先,他试着在上步骤的SQL中,直接把会员等级这个直接算出来,
SELECTorders.customer_id,MAX(customer_name) AS customer_name,SUM(unit * unit_price *(1- discount)) AS total_sales,CASE cityWHEN '上海' THENCASE WHEN SUM(unit * unit_price *(1- discount))>=300 THEN '白金'WHEN SUM(unit * unit_price *(1- discount))>=100 THEN '黄金'ELSE '普通'ENDWHEN '杭州' THENCASE WHEN SUM(unit * unit_price *(1- discount))>=250 THEN '白金'WHEN SUM(unit * unit_price *(1- discount))>=80 THEN '黄金'ELSE '普通'ENDENDas customer_rankFROM orders JOIN customersON orders.customer_id = customers.customer_idWHERE customers.is_delete=FalseGROUP BY orders.customer_idORDER BY total_sales DESC
得到结果:

2.3.2 重构
小吴突然想起了自己在从事“数据工程师”之前,自己在某电商公司还做过两年"软件工程师",当时的研发经理,天天用发音不太准的英语告诉小吴:
Do Not Repeat Yourself!
虽然没直接问研发经理,不过爱好学习的小吴猜测经理可能是从小吴也看过的经典著作《重构》 (《Refactoring》)中看来的。
带上“软件工程师”的帽子后,小吴看看自己写的SQL,除了感慨“同样是工程,为啥SQL工程和软件工程差别咋就这么大呢”。也发现了上面SQL还有不少问题:
重复的内容也太多了, 比如计算消费总额的时候, 不停的写 SUM(unit * unit_price * (1 - discount))
嵌套的CASE WHEN也太复杂(虽然小吴分别用了CASE WHEN的两种写法,但是并没有感觉到茴香豆的几种写法所带来的快感),另外,如果以后客户不光是“上海”,“杭州”了怎么办?
所以,小吴仔细重构了一版
SELECTcustomer_id,customer_name,total_sales,CASE WHEN total_sales >= baijin_bar THEN '白金'WHEN total_sales >= huangjin_bar THEN '黄金'ELSE '普通'ENDas customer_rankFROM (SELECTorders.customer_id,MAX(customer_name) AS customer_name,MAX(city) AS city,SUM(unit * unit_price *(1- discount)) AS total_salesFROM orders JOIN customersON orders.customer_id = customers.customer_idWHERE customers.is_delete=FalseGROUP BY orders.customer_idORDER BY total_sales DESC) t1 JOIN (VALUES ('上海',300,100),('杭州',250,80))AS rank_dict(city, baijin_bar, huangjin_bar)ON t1.city = rank_dict.city
得到结果:
小吴看到:
没有重复的计算“消费额”的逻辑
关于会员等级的计算, 通过查表的方式解决了不同城市不同计算方法的问题。
虽然:
SQL多了一层子查询
也请忽略程序员常见的中英文结合的名字, 比如:baijin_bar(白金会员入门门槛), huangjin_bar
小吴看着SQL很满意,向欣赏一件艺术品一样欣赏了10分钟,并额外花了5分钟调整了一下缩进和空格, 觉得自己同时是:
写SQL最好的程序员
写程序最好的SQL工程师
2.3.3 冲突
客户觉得自己收到了重视,营业额多了2个百分点,公司很高兴, 多找了一个数据开发工程师大吴来一起做数据(写SQL)。
大吴第一天来找小吴熟悉之前写的SQL,但是大吴花了半天时间仍没有理解到底小吴写的SQL是啥。因为:
业务需求是逐步增加的
SQL是那种写的时候知道自己在做什么,但是写好后就不知道每个地方都是做了什么了。
不过大吴经验丰富,很快和小吴达成了如下共识,并说是实现了小吴很欣赏的“逻辑隔离”。他们每做一个来自运营小胡的新需求,就在之前的SQL上套上一层以上SQL,经过一段时间, SQL变为:
--- add byDaWuSELECT col1,col2,col3FROM (--- add byXiaoWu, feature 123SELECT col3, col4FROM (--- add byDaWuSELECT col5,col6,col7,col8FROM(-- add byXiaoWu, skip check...........................................................................)ttt) t99) ttabc
当SQL行数超过了200 行,小吴觉得好像这样不太好,不过大吴告诉小吴:别着急,我之前所在的银行, 普通的SQL都有几千行,我们这算小菜一碟。
另外,小吴在向大吴提出了几次缩进要求(每行要比上一个逻辑块空出4个空格,不要写TAB)后,也不再提了,因为随着层级太多, 每行开头有几百个空格也实在是对不齐了。而且小吴也听过之前关于LISP程序员的程序最后一页全是“)))))))”的笑话。于是,小吴继续空4个空格写,大吴继续不留空格写逻辑,两个人竟仿佛达到了像一起工作多年的伙伴一样的默契。
3. 扪心自问
在2020年初,经过了一个漫长的寒假后,小吴也在长假中有了机会思考一下之前SQL的问题,于是发起了“扪心自问”
写上面那些意大利面式(spaghetti)的SQL好吗?看着不太好
意大利面式SQL有自己的优势吗?有,从小吴和大吴的SQL的和谐相处可以看出还是有价值的
我自己能看懂SQL所有的部分都是做什么的吗?不能。
又带上“软件工程师”的“帽子”,小吴陷入了沉思。
3.1 是否能用 temp table 解决
小吴想了半天,最终还是放弃了。
意大利面式的SQL的子查询嵌套层级实在太多了,每个临时数据都存到新的临时表中, 实在是太多空间了
那么是否写一些 drop table 命令,来在该临时表不用时马上释放掉?想了想后,表示:自己也不知道啥时候临时表不用了
临时表不光是占空间, 而且还没有索引,以及统计信息(statistics)等, 需要手工建立索引, 以及手工分析(ANALYZE) 来生成必要的统计信息
3.2 如何才能结合软件工程的实践
小吴又仔细读起了 PostgreSQL 的文档:https://www.postgresql.org/docs/current/index.html
突然有了灵感。WITH Queries (Common Table Expressions):https://www.postgresql.org/docs/current/queries-with.html 好像可以。
于是小吴结合自己之前的编程经验,把这个方案详细的写了下来
4. 初步方案
大吴的意大利面SQL的写法有其优势:
每次的业务需求就是一层SQL
虽然放在一起比较难看,但是分开写好像会比较清晰
比如:要做到第2章的例子,小吴可以这样写:
Steps:- name: step_filter_customer1comment:过滤掉非法客户sql:|-SELECT *FROM customersWHERE customers.is_delete=False- name: step_calculate_total_salescomment:计算客户的总消费额sql:|-SELECT orders.customer_id,MAX(customer_name) AS customer_name,MAX(city)as city,SUM(unit * unit_price *(1- discount)) AS total_salesFROM orders JOIN step_filter_customer1ON orders.customer_id = step_filter_customer1.customer_idGROUP BY orders.customer_idORDER BY total_sales DESC- name: step_rank_dictcomment:存储根据城市和消费额来决定会员等级的记录sql:|-SELECT *FROM(VALUES ('上海',300,100),('杭州',250,80))AS rank_dict(city, baijin_bar, huangjin_bar)- name: step_compute_customer_rankcomment:计算客户的会员等级sql:|-SELECT step_calculate_total_sales.*,CASE WHEN total_sales >= baijin_bar THEN '白金'WHEN total_sales >= huangjin_bar THEN '黄金'ELSE '普通'ENDas customer_rankFROM step_calculate_total_sales JOIN step_rank_dictON step_calculate_total_sales.city = step_rank_dict.city
小吴选取了最新最流行的 YAML 文件格式,而没选择之前的:INI,XML,JSON等格式,小吴也觉得自己还是挺 In Time 的。
这样, 我们就可以:
把编写SQL分成:面向人的SQL和面向数据库的SQL。面向人的SQL注重可读性,面向数据库的则注重效率。这一点有点像编程中的高级语言JAVA和面向机器的汇编语言之前的关系
把复杂的SQL拆分成多个小的SQL,每个小的SQL只负责一小块逻辑
把各个步骤之前的SQL按照引用关系,转为一个有向无环图(Directed Acyclic Graph, DAG), 这样我们可以用比较成熟的DAG遍历来组合成最终的SQL
通过读取上面人工编写的yaml文件, 经过我们的小的程序转化后, 面向机器执行的SQL变为:
WITH step_calculate_total_sales AS (WITH step_filter_customer1 AS (SELECT *FROM customersWHERE customers.is_delete=False)SELECT orders.customer_id,MAX(customer_name) AS customer_name,MAX(city)as city,SUM(unit * unit_price *(1- discount)) AS total_salesFROM orders JOIN step_filter_customer1ON orders.customer_id = step_filter_customer1.customer_idGROUP BY orders.customer_idORDER BY total_sales DESC), step_rank_dict AS (SELECT *FROM(VALUES ('上海',300,100),('杭州',250,80))AS rank_dict(city, baijin_bar, huangjin_bar))SELECT step_calculate_total_sales.*,CASE WHEN total_sales >= baijin_bar THEN '白金'WHEN total_sales >= huangjin_bar THEN '黄金'ELSE '普通'ENDas customer_rankFROM step_calculate_total_sales JOIN step_rank_dictON step_calculate_total_sales.city = step_rank_dict.city
得到结果:

Yeah,成功把复杂SQL拆分成面向人的多个SQL,并最终执行时, 还是有翻译好的高效的面向机器的唯一SQL。
4.2 如何利用DAG来易化“转化程序”的书写
其实DAG是计算机领域非常成熟的概念,以 Apache DolphinScheduler 中的相关代码为例,
注:Apache DolphinScheduler是国人发起的“分布式易扩展的可视化工作流任务调度“开源项目,并已经进入Apache孵化,笔者作为早期参加者和PPMC,也非常希望能吸引更多的人士加入到DolphinScheduler的开发。DolphinScheduler的项目地址在:https://github.com/apache/incubator-dolphinscheduler
比如DolphinScheduler中的DAG类:https://github.com/apache/incubator-dolphinscheduler/blob/dev/dolphinscheduler-common/src/main/java/org/apache/dolphinscheduler/common/graph/DAG.java
publicclass DAG<Node,NodeInfo,EdgeInfo>{// add node informationpublicvoid addNode(Node node,NodeInfo nodeInfo)publicboolean addEdge(Node fromNode,Node toNode)publicboolean containsNode(Node node)// whether this edge is containedpublicboolean containsEdge(Node fromNode,Node toNode)// get node descriptionpublicNodeInfo getNode(Node node)publicint getNodesCount()publicint getEdgesCount()publicCollection<Node> getBeginNode()publicCollection<Node> getEndNode()// Gets all previous nodes of the nodepublicSet<Node> getPreviousNodes(Node node)// Get all subsequent nodes of the nodepublicSet<Node> getSubsequentNodes(Node node)// Gets the degree of entry of the nodepublicint getIndegree(Node node)// whether the graph has a ringpublicboolean hasCycle()// DAG has a topological sortpublicList<Node> topologicalSort()throwsException}
这个流程变为:
遍历yaml中最上层数组的每个记录
对于每条记录,判断是否有前置依赖(有的话加 edge),把本身作为 node 加入 DAG
进行拓扑排序(topologicalSort)
把排序好的节点从前到后一个一个处理,通过WITH语句串起来
4.3 上面只是一种可行思路, 但是细节是魔鬼
上面的思路,感觉对Postgresql的SQL可读性做了非常棒的探索。但是,真正能用用于商业还是有很多细节的, 比如:每个步骤的schema信息,每个步骤的预览,以及某一步的schema变化后的处理。
所以,除了自行探索,也可以使用现成的商业产品。比如:笔者所在的创业公司——观远数据,就有丰富的数据可视化和数据开发平台等多个产品,欢迎访问官网进行了解:https://www.guandata.com/
注:文中所描述的方法并不是观远数据系统ETL中所使用的实现方法,观远数据系统中有着更先进、完善的实现。
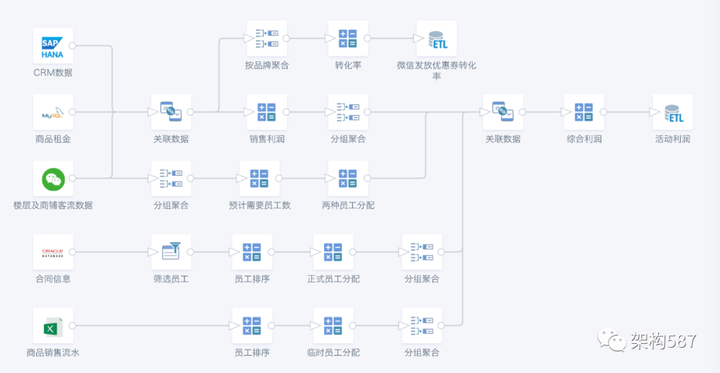
5. 想象空间
有了上面的方案, 我们可以把SQL变为可拆分,容易读懂的方式,并且每一步转化都是有注释的可以理解的小步骤。
我们还可以继续参考”软件工程“中的其它实践来管理SQL, 比如:
SQL yaml文件上传到github,进行版本控制
也可以编写单元测试
通过Github的Action做CI/CD, 自动化测试等
从此SQL也逐渐软件工程起来。
正所谓:
软件工程用的好,SQL写的好
软件工程用的好,下班早,头发多
软件工程用的好,彻底重写少
注:本文来自于观远数据吴宝琪原创,转载或更多交流请关注公众号:架构578