Redis高级篇
先熟悉一下redis的配置文件redis.conf
服务器端配置
daemonize yes|no 设置服务器已守护进程方式运行
bind 127.0.0.1 绑定主机地址
port 6379 设置端口号
databases 16 设置数据库数量
日志配置
loglevel debug|vorbose|notice|warning 默认级别是vorbose
日志记录文件名 logfile 端口号.log
客户端配置
设置同一时间最大客户端连接数maxclients 0
客户端闲置等待最大时长,达到最大值后关闭,如需该功能设置为0 timeout 300 秒
多服务器的快捷配置
include /path/server-端口号.conf 创建公共的配置
高级数据类型
Bitmaps
标记统计
命令
获取:getbit key offset
设置:setbit key offset value // 0 或 1
交、并、或异
bitop op destkey key1 key2
op:
交:and
并:or
非:not
异或:xor
统计指定key中1的数量:bitcount key [start end]
HyperLogLog
基数统计
命令
1.添加:pfadd key element [element1]
2.统计:pfcount key [key1]
3.合并:pfmerge destkey sourcekey [sourcekey1]
主从复制
主从复制就是将master数据及时有效的复制到slave中
一个master可以拥有多个slave,一个slave值对应一个master

职责:
master:写数据
执行写操作,将出现变化的数据自动同步到slave中
读数据(可忽略)
slave:读数据
写数据(禁止)
主从复制作用:
1 读写分离
2 负载均衡
3 数据恢复
4 数据冗余
5 高可用
主从复制工作流程
slave连接master,同步数据,反复同步
三个阶段:
建立连接阶段:
1salve和master进行连接,在salve端保存master信息,
2在slave会创建一个信息通道socket
3 发送ping指令
4 身份验证,master保存slave端口
连接操作方式一:
1 启动服务器6379和6380
2 连接到客户端6380 redis-cli -p 6380
3 发送指令 slaveof 127.0.0.1 6379
4 此时连接数据同步,在6379客户端set数据,在6380端取出
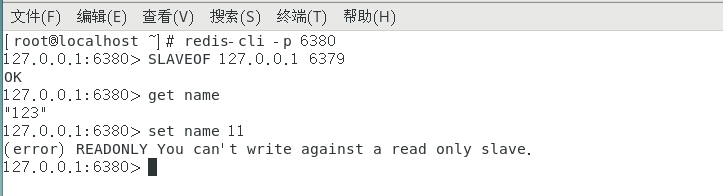
slave不允许写数据。
连接操作方式二:
1在启动6380服务器时加参数,redis-server conf/redis-6380.conf --slaveof 127.0.0.1 6379
连接操作方式三:配置文件
1 vim conf/redis-6380.conf
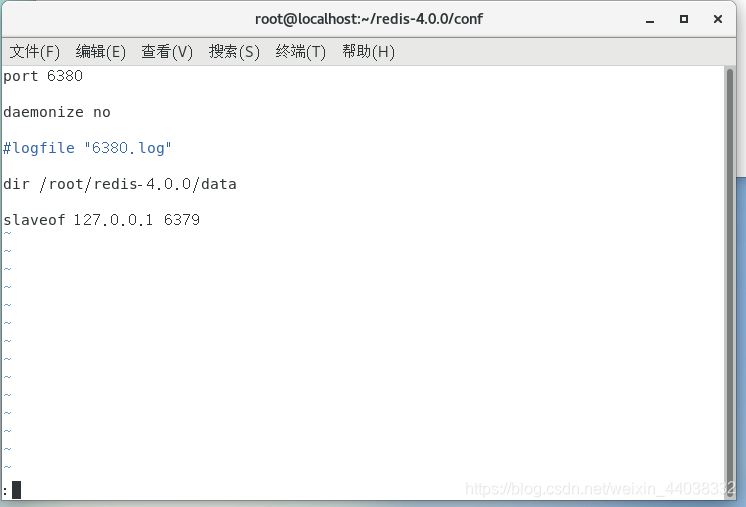
输入info查看信息
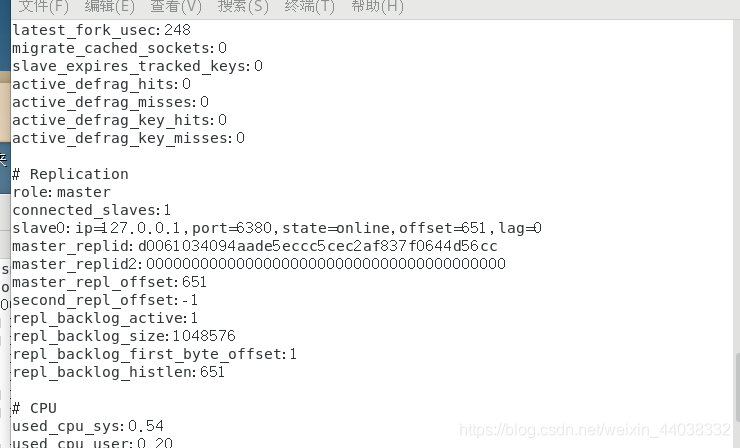
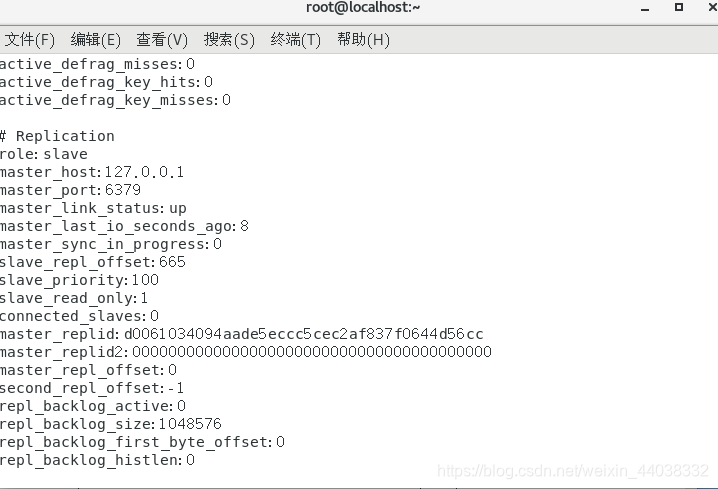
从服务器断开操作:slaveof no one
数据同步阶段
1 slave请求数据同步,master执行bgsave,
2创建RBD同步数据,创建命令缓存区,生成rbd
3 恢复RDB同步数据
123是全量复制,但是没有命令缓存区的数据
4 master发送复制缓冲区信息,
5 slave接受信息,执行bgrewriteaof重写,恢复数据
45是部分复制
注意:1 如果master数据量大,要避开高峰期
2 master复制缓冲区设置大小不合理,会导致数据溢出。slave会进行全量复制死循环。
配置master的repl-backlog-size 1mb
设置客户端slave对外写服务关闭slave-serve-state-data yes|no
命令传播阶段
断网现象:
网络闪断闪连 忽略
短时间网络中断 部分复制
长时间网络中断 全量复制
部分复制的三个核心要素:
1服务的运行id
2 主服务器的复制积压缓冲区
3 主从服务器的复制偏移量
服务器运行id:服务器运行id是每一台服务器运行的身份识别码,一台服务器多次运行可以生成多个运行id
复制缓冲区:是一个先进先出的队列,用于存储服务器执行过的命令,每次传播命令,master都会将传播的命令记录下来,并存储到复制缓冲区。
复制缓冲区由偏移量和字节值两部分组成。offset偏移量
数据同步+命令传播工作流程
心跳机制
进入命令传播阶段。
master心跳:
指令:Ping
周期:由repl-ping-slave-period决定,默认10秒
作用:判断slave是否在线
slave心跳任务:
指令:REPLCONF{offset}
周期:1秒
作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令
作用2:判断master是否在线
查看rdb文件 redis-check-rdb dump-6379.rdb
哨兵模式
哨兵(sentinel)是一个分布式系统,对主结构的每台服务器进行监控,当出现故障时,通过投票机制选择新的master,并将所有的slave连接到新的master
启动哨兵模式
配置三个哨兵(配置相同,端口不同)
参看sentinel.conf
启动哨兵
redis-sentinel sentinel-端口号.conf
查看哨兵文件cat sentinel.conf|grep -v “#”|grep -v “^$”

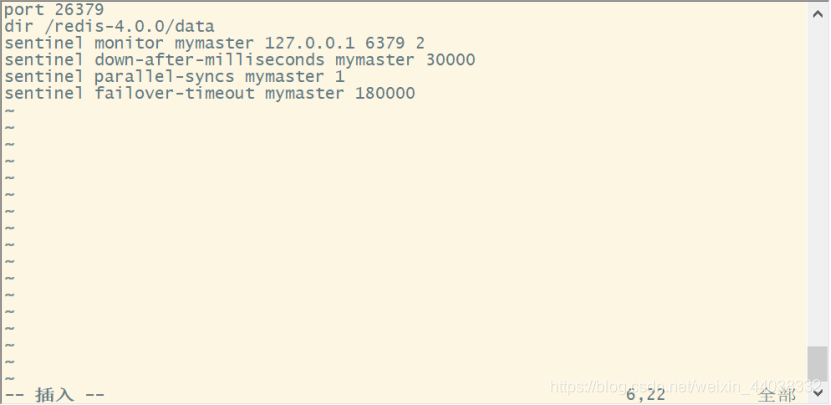
sentinel monitor mymaster 127.0.0.1 6379 2 监视服务器,后面的2是,两个哨兵认为挂了就挂了,通常是哨兵数量一半加1
sentinel down-after-milliseconds mymaster 30000主连接的多长时间没响应就认为挂了,毫秒单位
sentinel parallel-syncs mymaster 1 有几条线开始数据同步
sentinel failover-timeout mymaster 180000 多长时间同步完成算超时
复制到conf目录下cat sentinel.conf |grep -v “#”|grep -v “^$” > ./conf/sentinel-26379.conf
复制一个26380文件 sed ‘s/26379/26380/g’ sentinel-26379.conf > sentinel-26380.conf
复制一个26381文件 sed ‘s/26379/26381/g’ sentinel-26379.conf > sentinel-26381.conf
复制一个redis6381的配置文件sed ‘s/6380/6381/g’ redis-6380/conf > redis-6381.conf
三个哨兵都是监听127.0.0.1 6379这个master
先启动master 6379,再启动slave 6380 6381 ,一个master下面两个slave

启动哨兵
redis-sentinel sentinel-6379.conf
redis-sentinel sentinel-6380.conf
redis-sentinel sentinel-6381.conf
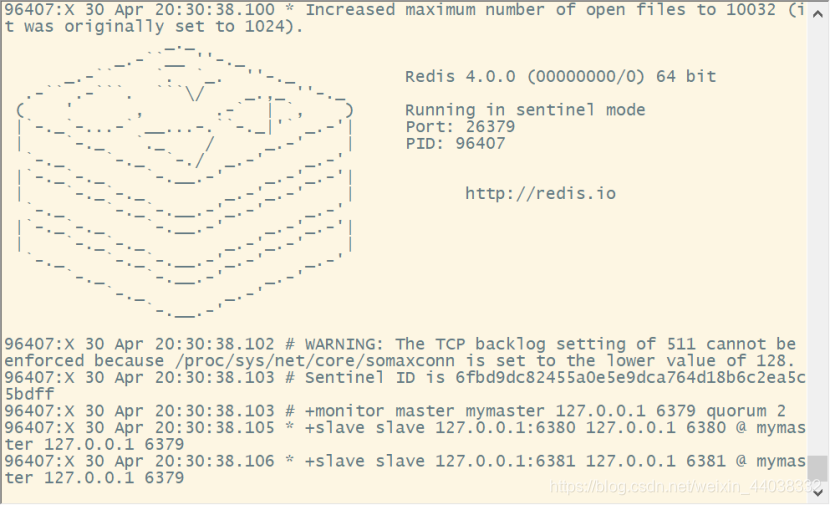
登录哨兵客户端redis-cli -p 26379
这是sentinel-6379.conf配置文件发生改变
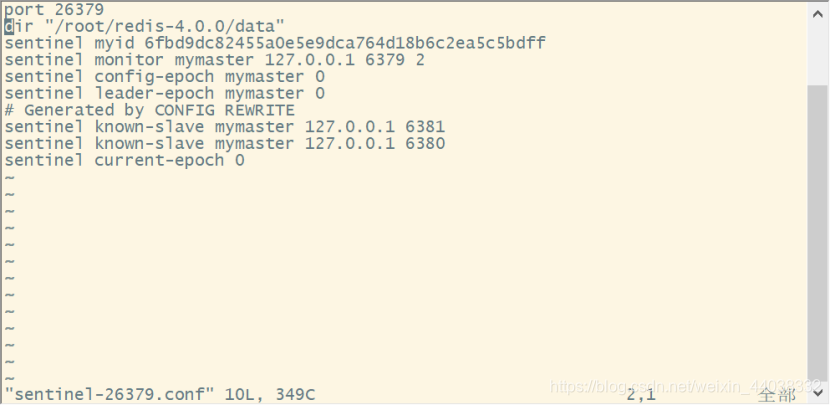
启动第二个哨兵
redis-sentinel conf/sentinel-26380.conf
redis-sentinel conf/sentinel-26381.conf
1 停掉6379master
2 哨兵尝试重连,30秒后重新选举

3 master变成6381,把6380和6379连到6381上
4 等6379再活过来,就变成slave了
哨兵工作原理
监控阶段:同步各个节点信息,主从和各个哨兵是否在线,获取master状态,获取slave属性。先连接master,拿到info。sentinel和master建立cmd连接,保存哨兵状态。通过info去连接每个slave,sentinel和sentinel之间发布订阅。
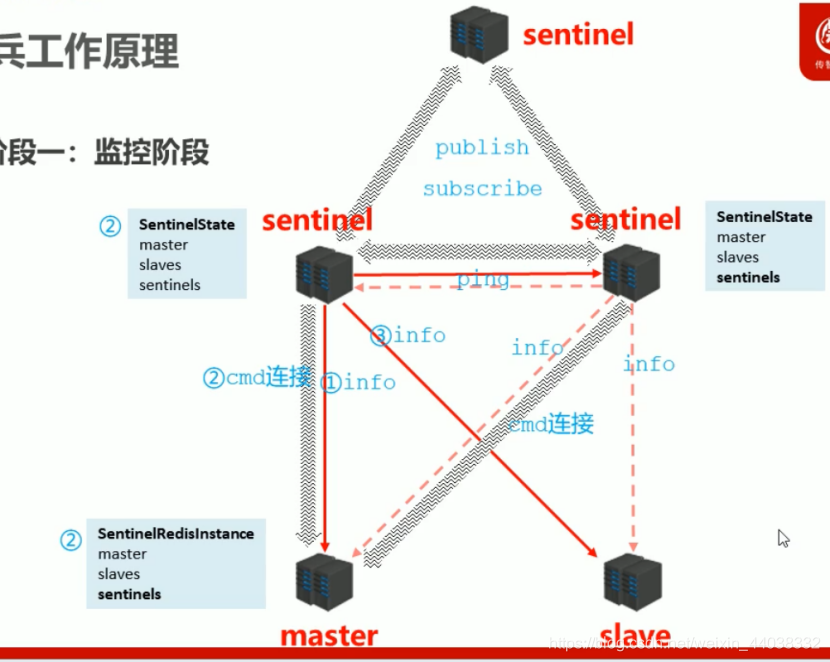
阶段二:通知阶段
阶段三:故障转移阶段
Redis集群 cluster
内存可扩展,单点故障问题
多个master多个slave
Redis存储数据槽 16384
多个redis会平分16384个数据槽,
key会通过一个算法生成一串数字,去和16384取余找到数据槽。
每个redis节点之间通信,都会存储每个节点拥有的槽位
这样key访问有可能一次命中,有可能两次命中
配置信息:
配置 cluster-enabled yes 说明这是一个cluster节点
cluster-config-file nodes-6379.conf配置节点名称
cluster-node-timeout 1000 一旦下线10秒反馈
master链接slave最小数:cluster-migration-barrier count
一共配置6个文件对应的宽口6379 到6384
sed “s/6379/6380/g” redis-6379.conf > redis-6382.conf
一次启动各个节点
通过ps-ef |grep redis查看进程

通过redis下src目录下的redis-trib.rb命令
下载ruby
下载gem
ruby和gem版本需要升级,centos7的ruby最高版本2.0问题
执行命令
yum -y install ruby ruby-devel rubygems rpm-build
ruby -v
yum -y install ruby ruby-devel rubygems rpm-build
yum install rh-ruby24 -y
scl enable rh-ruby24 bash
ruby -v
gem install redis

ruby最少要2.3,centos7最大支持2.0
要进入redis的src目录下执行./redis-trib.rb 配置节点
执行命令进行集群配置
./redis-trib.rb create --replicas 1(这个1是指一个主对应一个从节点)
127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382
127.0.0.1:6383 127.0.0.1:6384
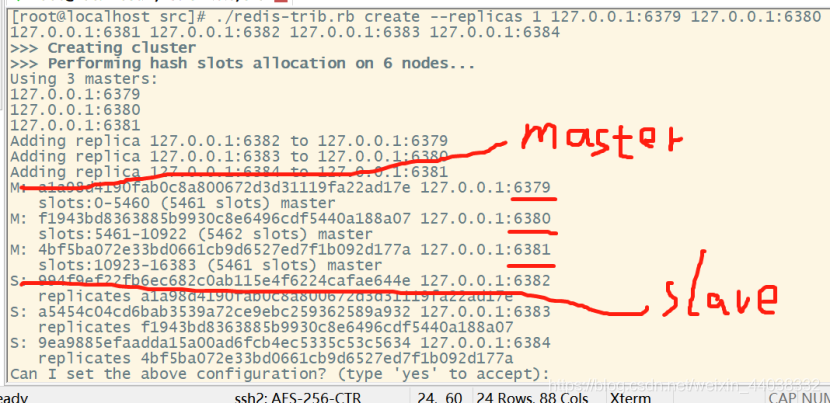
输入yes生成配置文件
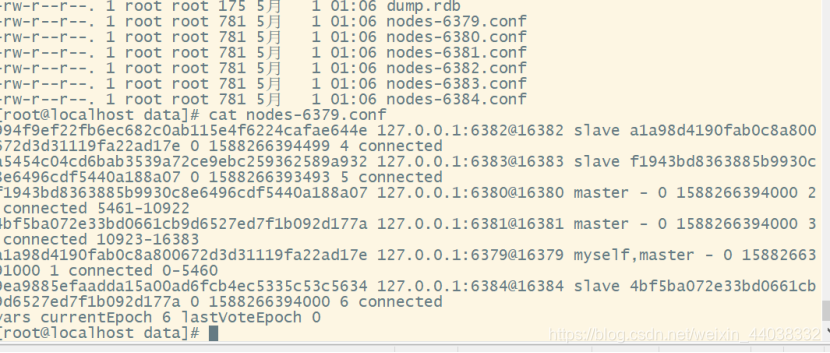
连接到6379客户端

槽位对应不正确
使用redis-cli -c 连接集群

再连接到6382客户端上,会自动重定向到6380端口的槽位

当一个slave下线的时候,对集群不会产生影响。
当一个master下线,10秒中失联,slave会变成master取代它。
停掉6380,6383会尝试重连10秒,就会slave变成master,当6380再次连上时。6383就是master,6380变成slave
客户端指令cluster-nodes 查看节点之间信息
缓存预热
事先预热缓存数据
缓存雪崩
数据库连接激增。应用服务器无法及时处理请求,数据库崩溃,应用服务器崩溃,redis服务器崩溃。
问题排查:短时间之内,缓存中较多的key集中过期,大量数据打到数据库。
解决方案:
1.更多的页面静态化处理
2 构建多级缓存Nginx缓存+redis缓存+ehcache缓存
3检测mysql严重耗时的业务进行优化
4 灾难性预警机制。
监控redis服务器性能指标
Cpu占用
内存容量
查询平均响应时间
线程数
5 限流,降级
解决方案:
1 删除错略调整LRU和LFU
2 数据有效策略调整
根据业务有限期进行分类错峰,
过期时间使用固定时间+随机值形似,稀释几种到期的key数量
3超热数据使用永久key
4 定期维护
对即将过期的数据做访问量分析,确认是否延迟,配合访问量统计,做热点数据的延迟,
5 加锁
缓存击穿
问题排查:redis正常,redis某个key过期了,该key访问量巨大,多个数据请求从服务器直接压到redis,都未命中,redis短时间内发起大量对数据库中同一数据的访问。
单个key高热数据,key过期
解决方案:
1 预先设定
2 现场调整,演唱过期时间
3 后台刷新数据
4 二级缓存
5 加锁,加分布式锁
缓存穿透
问题排查:redis大面积出现未命中,出现非正常的URL,数据库中不存在。
解决方案:
1 缓存null,设置端时限,
2 白名单策略,所有id对应bitmaps,使用布隆过滤器
3 实施监控
4 key 加密
监控指标
性能指标(Performnamce)
latency Redis响应一个请求的时间
instantaneous_ops_per_sec 平均每秒处理请求总数
hit rate(calculated) 缓存命中率
内存指标
used_memory 已使用内存
mem_fragmentaion_ratio 内存碎片素
evicted_keys 由于最大内存限制被移除的key数量
blocked_clients 由于BLPOP,BRPOP 阻塞的客户端
监控指标
connected_clients 客户端连接数
connected_slaves Slave数量
master_last_io_seconeds_ago 最近一次主从交互之后的秒数
keyspace 数据库中key值总数
持久化指标
rdb_last_save_time 最后一次持久化保存到磁盘的时间戳
rdb_changes_since_last_save 自最后一次持久化依赖数据库更改数
错误指标
rejected_connections 由于达到maxcliennt限制而被拒绝的连接数
keyspace_misses key值查找失败次数
master_link_down_since_seconds 主从断开的持续时间
监控方式
工具:
Cloud Insight Redis
Prometheus
Redis-stat
Redis-faina
RedisLive
zabbix
命令:
benchmark 压力测试
redis-benchmark 50个连接,10000次请求
redis-benchmark -c 100 -n 5000
redis-cli
monitor
打印服务器信息,进入redis服务器指令
showlog
慢日志
