1. REDIS 哨兵模式搭建
sentinel (哨兵模式):选择一个redis实例作为sentinel ,实时监控主服务器和从服务器运行状态,并且实现自动故障转移,当一个主服务器不能正常工作时,Redis Sentinel 可以将一个从服务器升级为主服务器, 并对其他从服务器进行配置,让它们使用新的主服务器,同时会通知系统管理员或其他计算机程序,要实现高可用,起码设置3个哨兵
什么时候执行故障迁移?
当quorum个sentinel认为当前master 已经不可用时执行故障迁移

M代表master
S代表哨兵
R代表slave(replica)
## step1
## 按照复制的方式搭建一主二从
https://www.cnblogs.com/start-from-zero/p/12818555.html
## step2
## 简单配置以下 sentinel.conf (在redis安装目录)
## sentinel monitor mymaster 127.0.0.1 6379 1 (master的ip和端口,分别为 别名,IP地址,端口号 表示有几个sentinel同意才会执行故障转移)
## sentinel auth-pass mymaster 12345 (如果master 设置了密码要设置,而且每个slave 都要相同的密码,不然无法切换,否则不用设置)
## daemonize yes
## logfile "/usr/logs/redis/redis6382.log"
## cp /usr/redis-4.0.14/sentinel.conf /usr/conf/redis/sentinel6382.conf
## step 3
## redis-sentinel /usr/conf/redis/sentinel6382.conf
## 启动成功
## step 4
## tail -f /usr/conf/redis/redis6382.log

## 已经开始监听3个实例
## 第一行表示正在监听master服务器,只要一个哨兵认为master故障就可以执行故障迁移
## step5
## 宕机测试
## netstat -lnp | grep redis

## kill -9 943 (kill 掉master实例)
1048:X 21 Apr 15:18:15.944 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. 1048:X 21 Apr 15:18:15.944 # Sentinel ID is 0b147680222c65e1292cc13c73638f6aed6cdcb1 1048:X 21 Apr 15:18:15.944 # +monitor master mymaster 127.0.0.1 6379 quorum 1 ## sentinel 正在监控master 1048:X 21 Apr 15:18:15.944 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 1048:X 21 Apr 15:18:15.945 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 ## sentinel开始监控所有的slave 1048:X 21 Apr 15:20:00.234 # +sdown master mymaster 127.0.0.1 6379 ## master 主观宕机,当一个sentinel ping节点的时候发现没有收到有效的回复则认为该节点下线,当只有一个sentinel的时候,一个sentinel认为下线也就是客观下线 1048:X 21 Apr 15:20:00.234 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1 ## 当认为监控的某节点为客观下线的sentinel数量达到quorum则为客观下线,开始故障迁移 1048:X 21 Apr 15:20:00.234 # +new-epoch 1 ## 当前的的版本号为1,当遇到变更时会加 1 1048:X 21 Apr 15:20:00.234 # +try-failover master mymaster 127.0.0.1 6379 ## 开始故障恢复,master 已经达到下线的条件,就是主观认为某节点主观下线的sentinel 数量 > quorum 1048:X 21 Apr 15:20:00.235 # +vote-for-leader 0b147680222c65e1292cc13c73638f6aed6cdcb1 1 ##投票开始 sentinel-0b147680222c65e1292cc13c73638f6aed6cdcb1 已投 1048:X 21 Apr 15:20:00.235 # +elected-leader master mymaster 127.0.0.1 6379 ## 选择一个哨兵执行 failover故障迁移 , 1048:X 21 Apr 15:20:00.235 # +failover-state-select-slave master mymaster 127.0.0.1 6379 ## 从slave 中选择一个做master 1048:X 21 Apr 15:20:00.311 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 ## 选中127.0.0.1:6381 作为新master 1048:X 21 Apr 15:20:00.311 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 ## 127.0.0.1:6381 实例上执行slaveof no one 更换新主的角色 1048:X 21 Apr 15:20:00.382 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 ## 等待其他sentinel 确认新slave 1048:X 21 Apr 15:20:01.279 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 ## 确认成功,新主成为master 1048:X 21 Apr 15:20:01.279 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379 ## failover 故障迁移开始更改 slave 配置 1048:X 21 Apr 15:20:01.332 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 ## 发送新的slaveof命令给127.0.0.1 6380 1048:X 21 Apr 15:20:02.299 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 ## 127.0.0.1:6380 执行slaveof命令和sync命令 1048:X 21 Apr 15:20:02.299 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 ## 执行完成,此时查看配置文件可以看到6381的已经移除了slaveof参数,6380的配置slaveof指向了6381,而不是原来的6379 1048:X 21 Apr 15:20:02.357 # +failover-end master mymaster 127.0.0.1 6379 ## 故障迁移成功 1048:X 21 Apr 15:20:02.357 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381 ## 各个sentinel开始监控新的master 1048:X 21 Apr 15:20:02.358 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 ## sentinel 监听到新主的slave 1048:X 21 Apr 15:20:02.358 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 1048:X 21 Apr 15:20:32.417 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 ## 监控中仍然有一台slave 下线中
## step 6
## redis-server /usr/conf/redis/redis6379.conf
## 重新启动旧主
1048:X 21 Apr 16:07:02.505 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 ## 127.0.0.1:6379上线 1048:X 21 Apr 16:07:12.475 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 ## 此时查看配置文件可以看到6379的配置slaveof指向了6381,
2.sentinel参数说明
port 26379
## Sentinel使用Redis instances Pub/Sub功能(基于端口实现)来发现监视相同主服务器和slave的其他Sentinel
## 哨兵与其他哨兵通过保持联系,以便相互检查对方的可用性,并交换消息,通过端口来实现
## 所以要保证port 26379可用 ,当然也可以更改
sentinel client-reconfig-script <master-name> <script-path>
## 当主服务器因故障转移而变更时,可以调用脚本执行特定于应用程序的任务,以通知客户端,配置已更改且主服务器地址已经变更
sentinel deny-scripts-reconfig
## 默认情况下,SENTINEL SET将无法在运行时更改notification-script和client-reconfig-script
## 设置为no,cli中sentinel set 可以设置任何参数
sentinel down-after-milliseconds <master-name> <milliseconds>
## 主节点或slave在指定时间内没有回复PING,则认为节点下线,默认30秒
sentinel monitor mymaster 127.0.0.1 6381 1
## sentinel监控的主节点
sentinel auth-pass mymaster 12345
## 如果监控的master节点有密码,则需要配置,否则不用设置
sentinel failover-timeout <master-name> <milliseconds>
## 执行failover的最长时间,默认3分钟,
取消已经超时的故障转移,但是前提是没有产生任何配置更改(SLAVEOF NO ONE 还没执行)
sentinel notification-script <master-name> <script-path>
## 当报警时执行的通知脚本 如SDOWN ODOWN
%poch%
## 变更次数
R raplica /slave
M master
S sentinel

测试quarum只对master 是否已经下线有作用,但是不对挑选一个sentinel 去执行故障迁移有用
10.199.203.210一个master 一个sentinel
10.199.234.92 一个slave 一个sentinel
test1
## step 1
## 10.199.203.210 执行:
## netstat -lnp | grep redis

## kill 1734
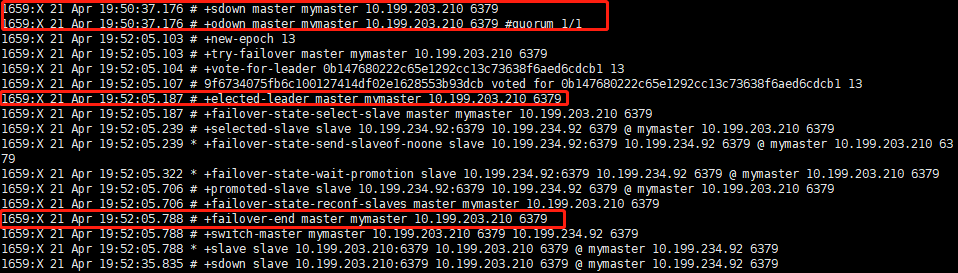
## quorum 足够判断 10.199.234.92已经下线,当sentinel没被下线的时能执行failover,也就是说当sentinel间能通信的时候,就能选举一个sentinel去执行failover故障迁移
test2
## step 1
## 10.199.234.92 执行:
## netstat -lnp | grep redis

## kill 30746 30711
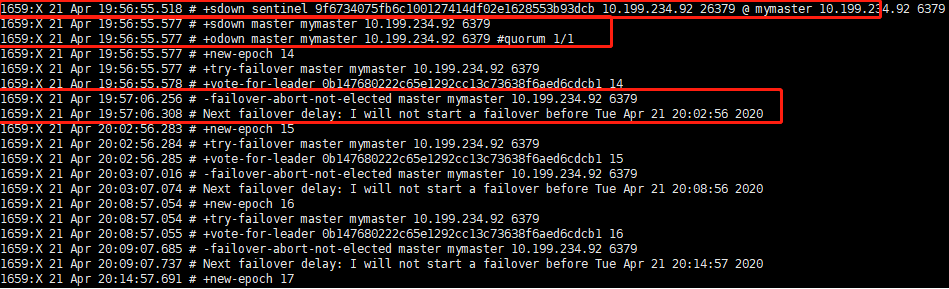
## quorum 足够判断 10.199.234.92已经下线,但不能执行failover,也就是说当sentinel间不能通信的时候,就不能选举一个sentinel去执行failover故障迁移
3.搭建redis cluster
## step 1
## 修改配置文件
## vim /usr/redis4.0.14/redis.conf
## 设置 6份配置文件,3主3从
port 7000
pid /tmp/redis7000.pid
logfile "/usr/logs/redis/redis7000.log"
daemonize yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
## cp /usr/redis4.0.14/redis.conf /usr/conf/cluster/7000.conf (6份7001,7002....7005)
## step2 (redis3~4需要执行)
## redis-server /usr/redis/conf/cluster/7000.conf
## redis-server /usr/redis/conf/cluster/7001.conf
...............
## redis-server /usr/redis/conf/cluster/7005.conf
## netstat -lnp | grep redis

## 高位端口用于cluster 集群中节点的通信,不用于客户端进行连接
## 低位端口用于客户端进行连接
## step 4 (redis3~4需要执行)
## 安装ruby
## yum install ruby
## 这种方式安装的ruby版本太低,redis不能用,需要ruby2.3,所以需要rvm 来升级,太麻烦,直接安装ruby2.5
## wget https://cache.ruby-lang.org/pub/ruby/2.5/ruby-2.5.3.tar.gz
## tar zxvf ruby-2.5.3.tar.gz
## configure
## make && make install
## gem install redis
## step5 (redis3~4需要执行)
## gem install redis
## 因为redis3~4 需要执行 redis-trib来创建集群,而执行redis-trib需要redis gem
## step 6
## redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 \ 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
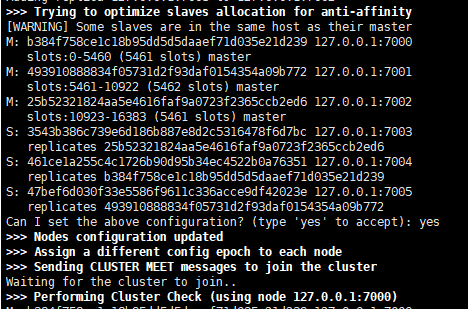
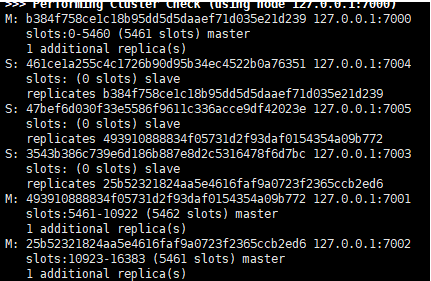
## 集群开启成功 ,把16384+ 个哈希槽分配给3个master 节点
## step 7 每次搭建完集群都要查看每个节点的状态信息
## redis-cli -p 7000 -c cluster info
## redis-cli -p 7001 -c cluster info
## redis-cli -p 7002 -c cluster info
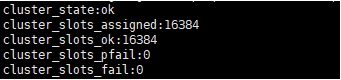
## 确认每个节点的集群状态,因为加入A节点的槽部分不可用,A的cluster_state的状态会为fail,其他节点的clutser_state会显示ok
## 搭建完集群起码要查看3个节点的集群状态,因为没有中心节点,所以通信靠ping和ping的数据包,容易会发生不一致状态
## step 8 查看其中一个master节点的日志
4062:M 22 Apr 14:32:03.151 # configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH 4062:M 22 Apr 14:32:03.175 # IP address for this node updated to 127.0.0.1 4062:M 22 Apr 14:32:06.381 * Slave 127.0.0.1:7004 asks for synchronization ## 7004 作为该master 的从节点,申请同步数据 4062:M 22 Apr 14:32:06.382 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for '5565534942a1f5a86dbbf4c7ff89ec0b21a6d733', my replication IDs are '6ddffd1a2fd0b1fdd09c45244429bd9277e0fa5b' and '0000000000000000000000000000000000000000') ## 部分复制失败,不存在该replid 4062:M 22 Apr 14:32:06.383 * Starting BGSAVE for SYNC with target: disk ## 开始执行全部复制 4062:M 22 Apr 14:32:06.383 * Background saving started by pid 18305 ## fork了一个子进程来执行全部复制 18305:C 22 Apr 14:32:06.392 * DB saved on disk 18305:C 22 Apr 14:32:06.393 * RDB: 0 MB of memory used by copy-on-write 4062:M 22 Apr 14:32:06.481 * Background saving terminated with success 4062:M 22 Apr 14:32:06.481 * Synchronization with slave 127.0.0.1:7004 succeeded ## 同步成功 4062:M 22 Apr 14:32:08.083 # Cluster state changed: ok ## 集群状态
## step9
## 此时哈希槽已经分配给了3个主节点
## redis-cli -p 7000
## set nviosdnv aiosd

## 对键nviosdnv执行crc16后对应槽位不在该节点上,保存失败
## 开启集群后,客户端访问一定要加 -c 告诉server是集群模式
## redis-cli -p 7000 -c

4.参数说明及测试
|
参数
|
说明
|
|---|---|
| cluster-enabled | 集群开关 |
| cluster-config-file | 集群配置文件的名称,每个节点都有一个集群相关的配置文件,持久化保存集群的信息 这个文件并不需要手动配置,这个配置文件有Redis生成并更新 每个Redis集群节点需要一个单独的配置文件,请确保与实例运行的系统中配置文件名称不冲突 |
| cluster-node-timeout | 节点互连超时的阀值。集群节点超时毫秒数 |
| cluster-slave-validity-factor | 在进行故障转移的时候,全部slave都会请求申请为master 但是有些slave可能与master断开连接一段时间了,导致数据过于陈旧,这样的slave不应该被提升为master 该参数就是用来判断slave节点与master断线的时间是否过长,设置为0表示不开启 (node-timeout * slave-validity-factor) + repl-ping-slave-period计算slave的数据是否过于陈旧 |
| cluster-migration-barrier | 那些分配后仍然剩余migration barrier个从节点的主节点才会触发节点分配,避免有主节点没有从节点的情况 |
| cluster-require-full-coverage | 默认情况下,集群全部的slot有节点负责,集群状态才为ok,才能提供服务。设置为no,可以在slot没有全部分配的时候提供服务 |
| cluster-slave-no-failover | 当设置为“是”时,此选项将阻止从属服务器尝试故障转移其主机故障期间的主机 |
cluster-config-file 同时也是redis-cli -c -p 7000 cluster nodes 的输出信息
replid ip:客户端连接端口号@节点通信端口号 角色 slave的master 时间戳 时间戳 多少个节点已经连接 节点拥有哈希槽 461ce1a255c4c1726b90d95b34ec4522b0a76351 127.0.0.1:7004@17004 slave b384f758ce1c18b95dd5d5daaef71d035e21d239 0 1587537129000 5 connected b384f758ce1c18b95dd5d5daaef71d035e21d239 127.0.0.1:7000@17000 myself,master - 0 1587537127000 1 connected 0-5460 47bef6d030f33e5586f9611c336acce9df42023e 127.0.0.1:7005@17005 slave 493910888834f05731d2f93daf0154354a09b772 0 1587537128084 6 connected 3543b386c739e6d186b887e8d2c5316478f6d7bc 127.0.0.1:7003@17003 slave 25b52321824aa5e4616faf9a0723f2365ccb2ed6 0 1587537126081 4 connected 493910888834f05731d2f93daf0154354a09b772 127.0.0.1:7001@17001 master - 0 1587537129084 2 connected 5461-10922 25b52321824aa5e4616faf9a0723f2365ccb2ed6 127.0.0.1:7002@17002 master - 1587537130085 1587537128000 3 connected 10923-16383 vars currentEpoch 6 lastVoteEpoch 0
cluster-node-timeout
## step 1
## netstat -lnp | grep redis
## kill -9 4100 ---kill掉7001的节点

## cluster-node-timeout 秒联系不到后被认为该节点fail
cluster-require-full-coverage
## step 1
## kill掉一个节点(主从都kill) 使其中一个节点的所有哈希槽不可用
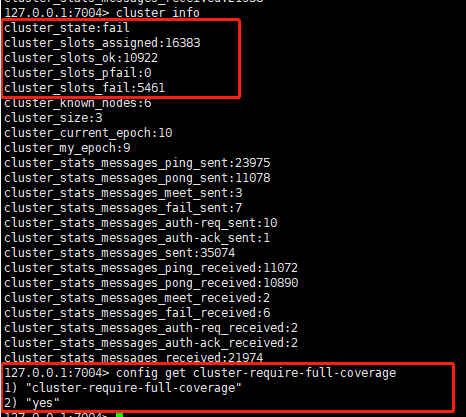
## cluster-require-full-coverage yes 的时候,当有哈希槽不可用(fail)的时候,集群不可用
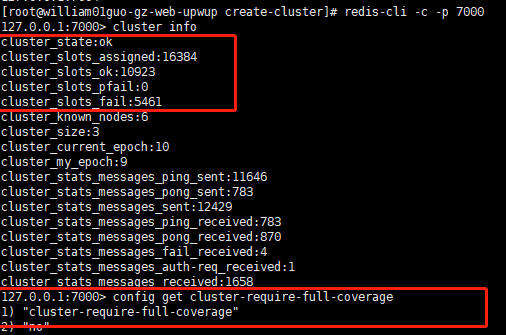
## cluster-require-full-coverage no的时候,当有哈希槽不可用(fail)的时候,集群仍然可用
## 该参数是实例配置的,所以,如果某个实例上该值为yes的时候,该节点仍然不可用
cluster-slave-no-failover
## step 1
## cluster nodes

## 在 7000 上设置 cluster-slave-no-failover yes
## kill掉7004的实例,观察是否发生failover

## 当在slave 上设置 cluster-slave-no-failover yes 时,当该slave 的master fail时不会发生failover
cluster-migration-barrier 1
## redis-server /apps/conf/cluster/7006.conf
## 开起多一个实例
## cluster meet 127.0.0.1 7006
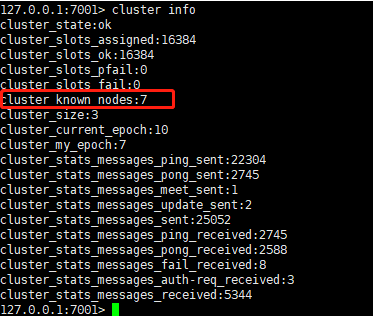
## 把127.0.0.1 7006实例加入集群
## cluster replicate 47bef6d030f33e5586f9611c336acce9df42023e
## 把该节点作为47bef6d030f33e5586f9611c336acce9df42023e的从节点
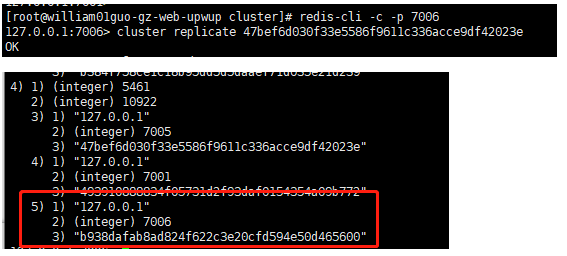
## kill 掉另外master 的的一个slave,让该master 没有slave,观察日志

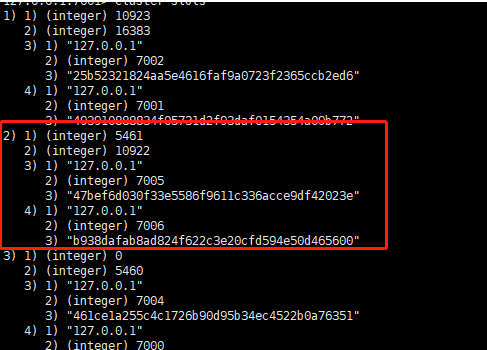
## 那些分配后仍然剩余migration barrier个从节点的主节点才会触发节点分配,避免有主节点没有从节点的情况
## 可见原来的7001 已经移动到没有slave 的master 上面
5.查看Redis Cluster 状态
cluster_state:ok ## ok状态表示集群可以正常接受查询请求。fail 状态表示,至少有一个哈希槽没有被绑定 cluster_slots_assigned:16384 ## 16384个哈希槽全部被分配到集群节点是集群正常运行的必要条件 cluster_slots_ok:16384 ## 哈希槽正常的数量 cluster_slots_pfail:0 ## 哈希槽状态是 PFAIL的数量 ## PFAIL状态表示我们当前不能和节点进行交互,但这种状态只是临时的错误状态 ## 只要哈希槽状态没有被升级到FAIL状态,这些哈希槽仍然可以被正常处理 cluster_slots_fail:0 ## 哈希槽状态是FAIL的数量。如果值不是0,那么集群节点将无法提供查询服务 ## 除非cluster-require-full-coverage被设置为no cluster_known_nodes:6 ## 集群中节点的数量 cluster_size:3 ## 至少包含一个哈希槽且能够提供服务的master节点数量 cluster_current_epoch:6 ## 每次故障迁移会递增,加 1 cluster_my_epoch:1 ## 配置文件中Config Epoch的值 cluster_stats_messages_ping_sent:7298 ## 该节点发送ping命令的次数 cluster_stats_messages_pong_sent:7047 ## 当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信 ## pong消息内部封装了自身状态数据 ## 节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新 cluster_stats_messages_sent:14345 ## 通过node-to-node二进制总线发送的消息数量. cluster_stats_messages_ping_received:7042 ## 该节点收到的ping消息数量 cluster_stats_messages_pong_received:7298 ## ## 该节点收到的pong消息数量 cluster_stats_messages_meet_received:5 ## 用于通知新节点加入。消息发送者通知接收者加入到当前集群 ## meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换 cluster_stats_messages_received:14345 ## 通过node-to-node二进制总线接收的消息数量.
6.REDIS 内部机制
数据分片机制
一共有16384个哈希槽,用于存放数据,数据存放时,先执行CRC16 来计算放在哪个槽上,可以移动哈希槽来把热点数据分散在不同节点上的来实现高效查询的目的
节点间的内部通信机制
redis cluster节点间采取gossip协议进行通信,互相之间不断通信,保持整个集群所有节点可用,好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力。
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如7001,那么用于节点间通信的就是17001端口
gossip协议包含多种消息,包括ping,pong,meet,fail,等等
meet: 某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信
ping: 每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据,所以可能会加重网络负担
pong: 返回ping和meet,包含自己的状态和其他信息,也可以用于信息广播和更新
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了
主观下线(pfail)
当cluster-node-timeout时间内没有响应其他节点的ping消息,则被发送ping消息的节点认为已经下线
客观下线(fail)
当某个节点判断另一个节点主观下线后,该节点的下线报告会通过Gossip消息传播,ping给其他节点,如果超过半数的节点都认为pfail了,那么就会变成fail
准备选举时间
有一定延迟,一定的延迟确保我们等待FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票
延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)
资格检查
如果cluster-slave-validity-factor开启,则对客观下线的slave进行资格检查,(node-timeout * slave-validity-factor) + repl-ping-slave-period计算slave的数据是否过于陈旧
如果过于陈旧,则不允许升级为master
选举投票
只有持有槽的主节点才会处理故障选举消息,每个持有槽的节点在一个配置纪元内都有唯一的一张选票,当接到第一个请求投票的从节点消息
替换主节点
当前从节点取消复制变为主节点,撤销故障主节点负责的槽,把这些槽委派给自己,并向集群广播告知所有节点当前从节点变为主节点
当有一个master 宕机后,slave 可以检测到master 宕机,同时另外带槽的节点也能发现某master宕机,由宕机master 的slave 来发起选举,但这个发起选举有一定的延迟,如果slave立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票。同时这段时间其他带槽的master 节点也会判断该节点是否下线。故障迁移由选举成功的slave来执行