Hadoop序列化与反序列化
1.什么是序列化?
“将一个对象编码成一个字节流”,序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输。 反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的对象。
2.序列化作用?
(1)作为一种持久化格式:对象被序列化后,其编码会被存储在磁盘上,供后续反序列化
(2)作为一种通信数据格式:序列化的结果,可在网络间进行传输(如不同网络中运行的Java虚拟机等
(3)作为一种拷贝、克隆机制:将对象序列化到内存缓存区中,通过反序列化可以得到一个对当前对象进行深度拷贝的新对象
3.Hadoop序列化机制?

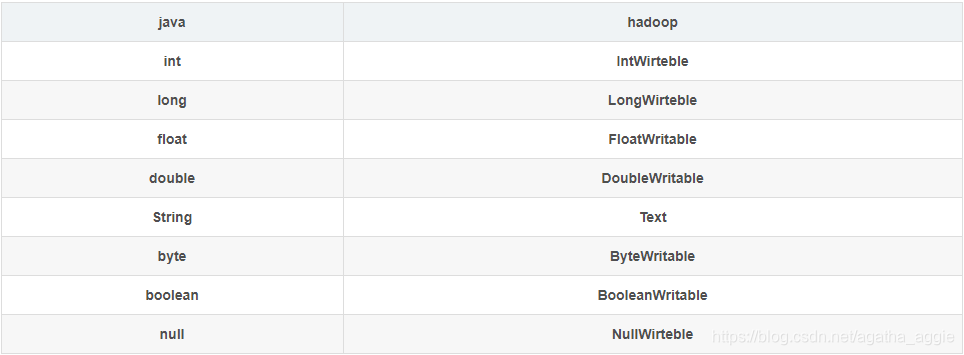
一.成员变量的类型都是Java的数据类型
思路:
1、创建实现类,实现Writable接口
2、在实现类中定义成员变量(成员变量的类型都是Java的数据类型)
3、设置get/set方法、无参构造方法、有参构造方法
4、重写toString方法
5、编写测试类
1.HadoopPerson.java
package com.hadoop.ser2;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class HadoopPerson implements Writable {
//注意这里属性的类型
private int id;
private String name;
private int age;
private String phone;
/**
* 必须初始化默认的属性
*/
public HadoopPerson() {
this.id = 0;
this.name = "";
this.age = 0;
this.phone = "";
}
public HadoopPerson(int id, String name, int age, String phone) {
this.id = id;
this.name = name;
this.age = age;
this.phone = phone;
}
//序列化
public void write(DataOutput out) throws IOException {
out.writeInt(this.id);
out.writeUTF(this.name);
out.writeInt(this.age);
out.writeUTF(this.phone);
}
//反序列化
public void readFields(DataInput in) throws IOException {
this.id = in.readInt();
this.name = in.readUTF();
this.age = in.readInt();
this.phone = in.readUTF();
}
@Override
public String toString() {
return "HadoopPerson{" +
"id=" + id +
", name=" + name +
", age=" + age +
", phone=" + phone +
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
}
2.TestMain.java
package com.hadoop.ser2;
import java.io.*;
public class TestMain {
public static void main(String[] args) throws Exception {
// ser();
deSer();
}
//序列化:将HadoopPerson对象写入到本地文件中
public static void ser() throws Exception{
//1、创建本地File对象,用于存储HadoopPerson对象
File file = new File("D:\\person.txt");
//2、创建文件输出流对象,用于接收DataOutputStream的字节流,并将其写入到文件中
FileOutputStream outputStream = new FileOutputStream(file);
//3、创建DataOutputStream对象,用于接收HadoopPerson序列化后的字节流,并传递给FileOutputStream对象
DataOutputStream dataOutputStream = new DataOutputStream(outputStream);
//4、利用有参构造函数创建HadoopPerson对象
HadoopPerson person = new HadoopPerson(1001,"方艺璇",20,"18984002995");
//4、调用person对象的write方法实现将其序列化后的字节流写入到dataOutputStream对象中
person.write(dataOutputStream);
//5、关闭数据流
dataOutputStream.close();
outputStream.close();
//6、打印提示信息
System.out.println("序列化成功~");
}
//反序列化:读取本地文件person.txt中的字节流序列将其转成HadoopPerson对象
public static void deSer() throws Exception{
//1、指定本地File对象
File file = new File("D:\\person.txt");
//2、创建文件输入流对象,用于读取文件中内容
FileInputStream inputStream = new FileInputStream(file);
//3、创建DataInputStream对象,用于接收本地文件的字节流,并传递给HadoopPerson对象进行赋值
DataInputStream dataInputStream = new DataInputStream(inputStream);
//4、利用有无参构造函数创建HadoopPerson对象,调用readFields方法将文件内容赋值给自己
HadoopPerson person = new HadoopPerson();
person.readFields(dataInputStream);
//5、关闭数据流
dataInputStream.close();
inputStream.close();
//6、打印提示信息
System.out.println("反序列化成功~" + person);
}
}



二.完全使用Hadoop序列化数据类型来实现Hadoop序列化测试
思路:
1、创建实现类,实现Writable接口
2、在实现类中定义成员变量(和前一个区别1:成员变量的类型都是Hadoop的数据类型)
3、设置get/set方法、无参构造方法、有参构造方法、
重写write和readFields方法(和前一个实验区别2)
4、重写toString方法
5、编写测试类
1.HadoopPerson.java
package com.hadoop.ser3;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class HadoopPerson implements Writable {
//注意这里,完全是Hadoop的基本序列化支持的数据类型
private IntWritable id;
private Text name;
private IntWritable age;
private Text phone;
/**
* 无参构造函数:
* 必须对属性进行初始化,否则在反序列化时会报出属性为null的错误
*/
public HadoopPerson() {
}
//有参的构造函数
public HadoopPerson(int id, String name, int age, String phone) {
this.id = new IntWritable(id);
this.name = new Text(name);
this.age = new IntWritable(age);
this.phone = new Text(phone);
}
//序列化:将当前对象的属性写入到输出流中
public void write(DataOutput out) throws IOException {
this.id.write(out);
this.name.write(out);
this.age.write(out);
this.phone.write(out);
}
//反序列化:读取输入流中的数据给当前的对象赋值
public void readFields(DataInput in) throws IOException {
this.id.readFields(in);
this.name.readFields(in);
this.age.readFields(in);
this.phone.readFields(in);
}
//当需要写入本地文件中时,重写toString方法,便于查看
@Override
public String toString() {
return "HadoopPerson{" +
"id=" + id +
", name=" + name +
", age=" + age +
", phone=" + phone +
'}';
}
public IntWritable getId() {
return id;
}
public void setId(IntWritable id) {
this.id = id;
}
public Text getName() {
return name;
}
public void setName(Text name) {
this.name = name;
}
public IntWritable getAge() {
return age;
}
public void setAge(IntWritable age) {
this.age = age;
}
public Text getPhone() {
return phone;
}
public void setPhone(Text phone) {
this.phone = phone;
}
}
2.HadoopPersonMain.java
package com.hadoop.ser3;
import java.io.*;
public class HadoopPersonMain {
public static void main(String[] args) throws Exception {
//ser();
deSer();
}
/**序列化
* 将实现了Writable的对象存在本地文件中
* @throws Exception
*/
public static void ser() throws Exception {
//1、创建对象
HadoopPerson person = new HadoopPerson(1001,"agatha",20,"11111111111");
FileOutputStream out = new FileOutputStream(new File("D:\\hadoop_ser.txt"));
DataOutputStream dataOutputStream = new DataOutputStream(out);
person.write(dataOutputStream);
dataOutputStream.close();
out.close();
System.out.println("序列化成功~");
}
//反序列化
public static void deSer() throws Exception {
FileInputStream inputStream = new FileInputStream(new File("D:\\hadoop_ser.txt"));
DataInputStream dataInputStream = new DataInputStream(inputStream);
//1、创建HadoopPerson对象,用于接收从输入流中的数据
HadoopPerson person = new HadoopPerson();
//2、反序列化
person.readFields(dataInputStream);
//3、关闭流
dataInputStream.close();
inputStream.close();
System.out.println("反序列成功~" + person);
}
}
三.通过编写MapReduce中的Mapper来实现Hadoop序列化测试
思路:
1、创建实现类,实现Writable接口
2、在实现类中定义成员变量(成员变量的类型都是Hadoop的数据类型)
3、设置get/set方法、无参构造方法、有参构造方法、重写write和readFields方法
4、重写toString方法
5、编写HadoopPersonMapper类,继承Mapper类(区别在这里)
6、编写Driver类,设置Mapper及其输入输出(区别在这里)
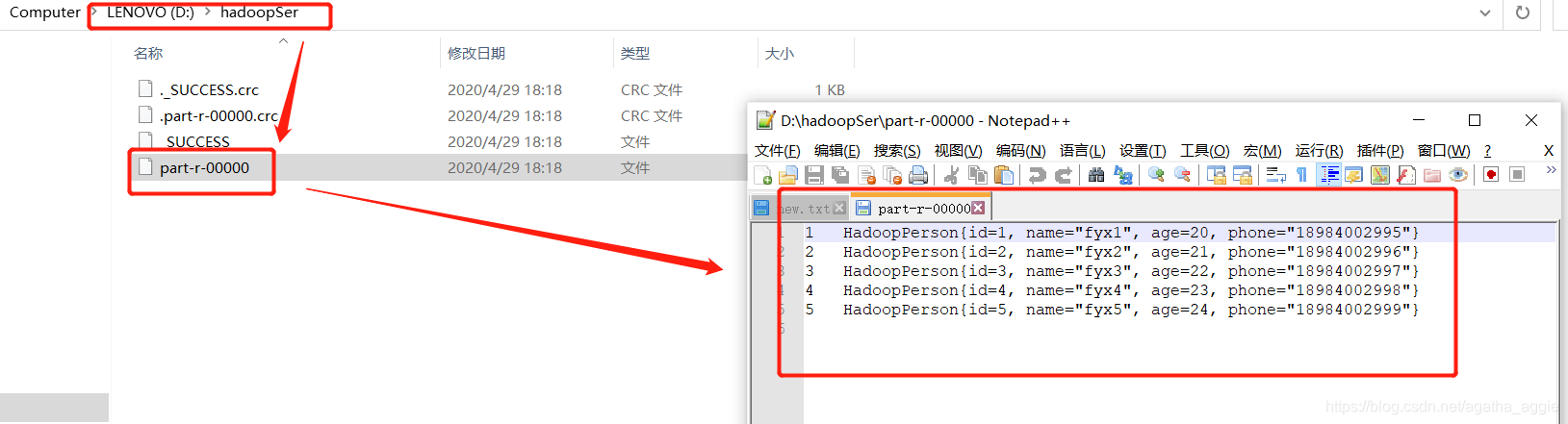
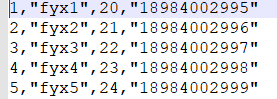
测试数据new.txt内容及格式如下:id,name,age,phone(自己使用自己测试数据)
1.HadoopPerson.java
package com.hadoop.ser;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class HadoopPerson implements Writable {
private IntWritable id;
private Text name;
private IntWritable age;
private Text phone;
/**
* 无参构造函数:
* 必须对属性进行初始化,否则在反序列化时会报出属性为null的错误
*/
public HadoopPerson() {
this.id = new IntWritable(0);
this.name = new Text("");
this.age = new IntWritable(0);
this.phone = new Text("");
}
//有参的构造函数
public HadoopPerson(int id, String name, int age, String phone) {
this.id = new IntWritable(id);
this.name = new Text(name);
this.age = new IntWritable(age);
this.phone = new Text(phone);
}
//序列化:将当前对象的属性写入到输出流中
public void write(DataOutput out) throws IOException {
this.id.write(out);
this.name.write(out);
this.age.write(out);
this.phone.write(out);
}
//反序列化:读取输入流中的数据给当前的对象赋值
public void readFields(DataInput in) throws IOException {
this.id.readFields(in);
this.name.readFields(in);
this.age.readFields(in);
this.phone.readFields(in);
}
//当需要写入本地文件中时,重写toString方法,便于查看
@Override
public String toString() {
return "HadoopPerson{" +
"id=" + id +
", name=" + name +
", age=" + age +
", phone=" + phone +
'}';
}
public IntWritable getId() {
return id;
}
public void setId(IntWritable id) {
this.id = id;
}
public Text getName() {
return name;
}
public void setName(Text name) {
this.name = name;
}
public IntWritable getAge() {
return age;
}
public void setAge(IntWritable age) {
this.age = age;
}
public Text getPhone() {
return phone;
}
public void setPhone(Text phone) {
this.phone = phone;
}
}
2.HadoopPersonMapper.java
package com.hadoop.ser;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class HadoopPersonMapper extends Mapper<LongWritable, Text, IntWritable,HadoopPerson> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String string = value.toString();
String[] split = string.split(",");
HadoopPerson person = new HadoopPerson(Integer.parseInt(split[0]),split[1],Integer.parseInt(split[2]),split[3]);
context.write(person.getId(),person);
}
}
3.HadoopPersonJob.java
package com.hadoop.ser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.*;
public class HadoopPersonJob {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setMapperClass(HadoopPersonMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(HadoopPerson.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(HadoopPerson.class);
FileInputFormat.setInputPaths(job,new Path("D:\\new.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\hadoopSer\\"));
boolean completion = job.waitForCompletion(true);
if (completion)
System.out.println("运行成功");
else
System.out.println("运行失败");
}
}