使用shell尝试爬取
$ scrapy shell https://www.zhipin.com/c101280100/
2020-02-07 10:42:20 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: scrapybot)
2020-02-07 10:42:20 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.8.0 (v3.8.0:fa919fdf25, Oct 14 2019, 10:23:27) - [Clang 6.0 (clang-600.0.57)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform macOS-10.15.2-x86_64-i386-64bit
2020-02-07 10:42:20 [scrapy.crawler] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0}
2020-02-07 10:42:20 [scrapy.extensions.telnet] INFO: Telnet Password: e782852fc4dca748
2020-02-07 10:42:20 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-02-07 10:42:20 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-02-07 10:42:20 [scrapy.core.engine] INFO: Spider opened
2020-02-07 10:42:21 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://www.zhipin.com/c101280100/> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x1048ed820>
[s] item {}
[s] request <GET https://www.zhipin.com/c101280100/>
[s] response <403 https://www.zhipin.com/c101280100/>
[s] settings <scrapy.settings.Settings object at 0x1048ed3d0>
[s] spider <DefaultSpider 'default' at 0x104db0490>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
- vailable Scrapy objects:在Scrapy中可以使用的对象
- scrapy:当前scrapy的模块,包含scrapy.Request, scrapy.Selector等等
- item:抓取的item
- request:向网站发起的请求
- response:从服务器拿到的响应(403:没有成功拿到服务器响应,如果目标页面返回403,那就表明对方网站做了一些反爬处理;真正的响应应该是200)
- settings:当前项目的设置
- spider:默认的spider
解决方案:
通常的处理是:
- 浏览器伪装
- 模拟登录
这里因为使用的shell调试,所以选择浏览器伪装:
- 为了让Scrapy伪装成浏览器,需要在发送请求时设置User-Agent头,将User-Agent头的值设为真实浏览器发送请求的User-Agent头即可。
- 通过真实的浏览器查看User-Agent头的值
Control + z终止当前进程
再输入:
$ scrapy shell -s USER_AGENT='Mozilla/5.0' https://www.zhipin.com/c101280100/
2020-02-07 10:52:48 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: scrapybot)
2020-02-07 10:52:48 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.8.0 (v3.8.0:fa919fdf25, Oct 14 2019, 10:23:27) - [Clang 6.0 (clang-600.0.57)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform macOS-10.15.2-x86_64-i386-64bit
2020-02-07 10:52:48 [scrapy.crawler] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'USER_AGENT': 'Mozilla/5.0'}
2020-02-07 10:52:48 [scrapy.extensions.telnet] INFO: Telnet Password: 0a8453c96491ca13
2020-02-07 10:52:48 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-02-07 10:52:48 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6024
2020-02-07 10:52:48 [scrapy.core.engine] INFO: Spider opened
2020-02-07 10:52:54 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.zhipin.com/web/common/security-check.html?seed=5SNeLJwqAobUjABFPCWdhH%2FqcVhQYmT7DvOmFXMjb%2B8%3D&name=a38cd86c&ts=1581043939571&callbackUrl=%2Fc101280100%2F&srcReferer=> from <GET https://www.zhipin.com/c101280100/>
2020-02-07 10:52:54 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.zhipin.com/web/common/security-check.html?seed=5SNeLJwqAobUjABFPCWdhH%2FqcVhQYmT7DvOmFXMjb%2B8%3D&name=a38cd86c&ts=1581043939571&callbackUrl=%2Fc101280100%2F&srcReferer=> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x105c93640>
[s] item {}
[s] request <GET https://www.zhipin.com/c101280100/>
[s] response <200 https://www.zhipin.com/web/common/security-check.html?seed=5SNeLJwqAobUjABFPCWdhH%2FqcVhQYmT7DvOmFXMjb%2B8%3D&name=a38cd86c&ts=1581043939571&callbackUrl=%2Fc101280100%2F&srcReferer=>
[s] settings <scrapy.settings.Settings object at 0x105c93400>
[s] spider <DefaultSpider 'default' at 0x1061578b0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
request <GET https://www.zhipin.com/c101280100/>
response <200 https://www.zhipin.com/web/common/security-check.html?seed=5SNeLJwqAobUjABFPCWdhH%2FqcVhQYmT7DvOmFXMjb%2B8%3D&name=a38cd86c&ts=1581043939571&callbackUrl=%2Fc101280100%2F&srcReferer=>
返回200说明抓取成功,
但是response和request网址不一致,应该是做了反爬处理
这里暂时不处理,换个网址:
$ scrapy shell -s USER_AGENT='Mozilla/5.0' https://www.zhipin.com/
[s] request <GET https://www.zhipin.com/>
[s] response <200 https://www.zhipin.com/>
提取数据
XPath提取法
response.xpath('//div[@class="text"]/a/text()').extract()
['后端开发', 'Java', 'C++', 'PHP', '数据挖掘', 'C', 'C#', '.NET', 'Hadoop', 'Python', 'Delphi', 'VB', 'Perl', 'Ruby', 'Node.js', '搜索算法', 'Golang', '推荐算法', 'Erlang', '算法工程师', '语音/视频/图形开发', '数据采集'...省略]
内容太多了就不一一写出来了
XPath最实用的简化写法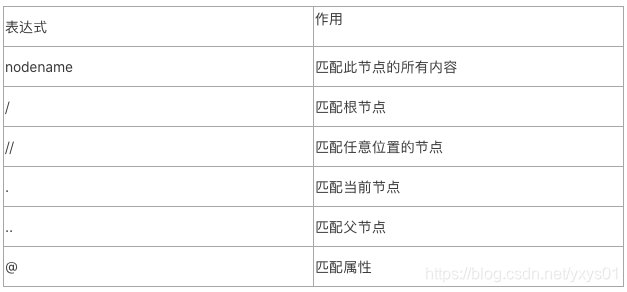
CSS选择器提取法
response.css('div.menu-sub div.text').extract()
['<div class="text">\n <a ka="search_100199" href="/c101010100-p100199/">后端开发</a>\n
<a ka="search_100101" href="/c101010100-p100101/">Java</a>\n<a ka="search_100102" href="/c101010100-p100102/">C++</a>\n <a ka="search_100103" href="/c101010100-p100103/">PHP</a>\n
<a ka="search_100104" href="/c101010100-p100104/">数据挖掘</a>\n
<a ka="search_100105" href="/c101010100-p100105/">C</a>\n
...省略
