昨日,组长给了一个临时的任务,因为DBA反应,这个批量查询的sql有问题:(Addition:因为公司隐私问题,我将表名做了简化,关键字段做了“*”处理)
SELECT ptc.d id, pi.* *Id, pi.prod_no prodNo, pi.prod_name prodName, pi.f!@e f#@e, pi.prod_attr isRenewal, pi.*bill *Bill, ps.id *Id, ps.s$e s$e, ps.*_period *Period, ps.c@d c@d, ps.c!m c&&e, ptm.id *Id, ptm.term term, ptc.m&*_at m*&t, ptc.z8_amt z8t, ptc.*_amt *Amt, prs.renewal_bill_period renewalBillPeriod, ptc.irr irr, pi.prod_type prodType, pi.*attr *Attr, pi.prod_type_id prodTypeId, ptc.*_id *Id, ptc.c#_id #Id, ptc.*%¥ %¥, ptc.balance_payment_rate balancePaymentRate, prs.id *Id, ptc.$ $e, ptc.min_rate_real minRateReal, ptc.* *, prs.renewal_way renewalWay, ptc.o$rate o#ate, ptc.*_term *Term, ptc.penalty_rate penaltyRate, ptc.a@it a!it, ptc.zero_repay_irr zeroRepayIrr, ptc.*_rate *Rate, ptc.b^^te b^^e, ps.start_time schemeStartTime, ps.end_time schemeEndTime FROM t_p_scheme ps LEFT JOIN t__info pi ON pi.id = ps.prod_id LEFT JOIN t_*_term_conf_free ptc ON ptc.scheme_id = ps.id LEFT JOIN t_*_renewal_scheme prs ON prs.id = ptc.renewal_scheme_id LEFT JOIN t_*_term ptm ON ptm.id = ptc.term_id WHERE pi.prod_type_id = 3 AND pi. STATUS = 2 AND #currentTime# BETWEEN ps.start_time AND ps.end_time ORDER BY pi.id DESC, ps.id DESC, ptc.id DESC乍一看,没有问题,我以为是查询的逻辑写的不对,或者关联表有问题,经过确认,组长说“ #currentTime# BETWEEN ps.start_timeAND ps.end_time ” 这句有问题,没有见过这样写的。。。。。。
确实,一般的写法会是这样: tb.currentTime BETWEEN #start_time# AND #end_time#”,这倒过来,就有点点蒙了。上网查了一下,对于如下这种:
<isNotEmpty prepend="AND" property="currentTime" > #currentTime# BETWEEN ps.start_time AND ps.end_time </isNotEmpty>
最好优化为:
<isNotEmpty prepend="AND" property="currentTime"> <![CDATA[ #currentTime# >= ps.start_time and #currentTime# <= ps.end_time ]]> </isNotEmpty>
对于ibatis中针对时间、日期的动态查询,使用between A and B写法,一旦A和B有一个不存在,结果就不对了,另外,一般变量放到左侧,虽然此处#currentTime#是传进来的变量,但是他不是字段的属性啊!!!so,改成下面这样,让表的字段,在运算符的左侧,查询性能会更高!!!
<isNotEmpty prepend="AND" property="currentTime"> <![CDATA[ ps.start_time <= #currentTime# and ps.end_time >= #currentTime# ]]> </isNotEmpty>
做完上述的修改之后,发现在测试3环境下的sql查询速度如下:
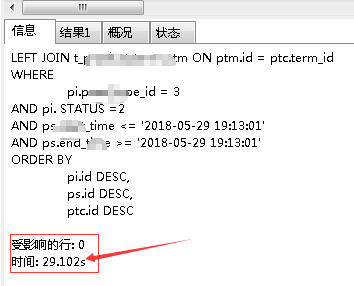
我的哥啊!你怎么这么慢!!!
分析:简单看了下,这次30s的查询,一共查了49571条数据,才不到5w啊,就这么慢!!!看了下,发现其left join的两张表“prs”以及“ptc”的数据量还是比较大的,几十万,而ON关联条件的字段,竟然没有索引,这就一定要加上啦:
ALTER TABLE t_*_conf_free ADD INDEX idx_*_id (*_id);再去分析,如图,已经快了很多了,但是在线上还是不快。。。
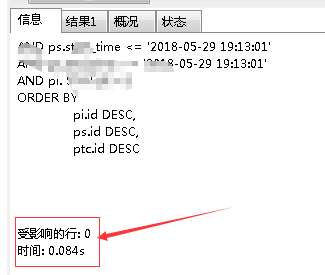
因为业务需要,这个接口要查到这些字段不能精简,所以最后只能从业务的角度来思考了:

如图所示,这个查询sql的入参只传入了2个值,status以及currentTime,导致其筛选的时候,需要到茫茫的Data海中进行筛选,组长观察了调用接口的入参,从数据的角度发现了规律:
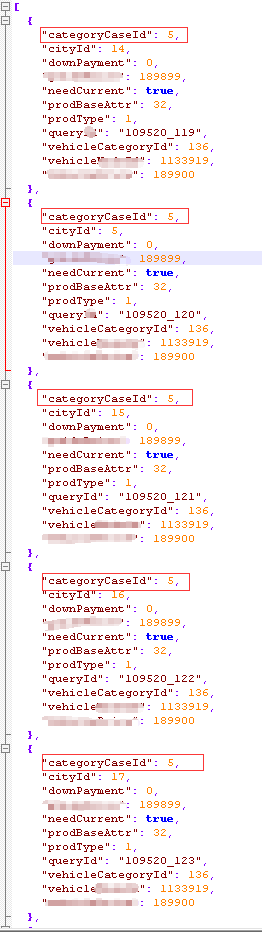
如上,这里一个大的json数组,嵌套了上百个小的json对象,观察数据,发现:
1.categoryCaseId,每次传入上百个jsonduixiang ,它都是一样的,而且入参的“categoryCaseId”含义本身是一个查询条件,纵使其中categoryCaseId不完全一致,只要虑重一下,就可以当中一个新的查询条件,加入进去,能大大缩小查询的范围啊。
2.prodBaseAttr,这个字段,和categoryCaseId道理上一样,这么多json对象,都是基本一致的,于是将其作为入参去查询,即使不一样,做虑重。
Params**Form queryForm = new Params**Form();
queryForm.setStatus(Product**Enum.**.getIndex());
queryForm.setCurrentTime(DateUtils.formatDate(new Date()));
HashSet<Integer> categoryCaseIdScope = new HashSet<Integer>();
HashSet<Integer> prodBaseAttrScope = new HashSet<Integer>();
for(Product^^DTO product^^Params : product^^DTOs){ //product^^DTOS就是上图中的JSon数组
//利用Set去重特性
categoryCaseIdScope.add(product^^Params.getCategoryCaseId());
prodBaseAttrScope.add(product^^Params.getProdBaseAttr());
}
queryForm.setCategoryCaseIdScope(StringUtils.join(categoryCaseIdScope.toArray(), ",")); //String类型
queryForm.setProdBaseAttrScope(StringUtils.join(prodBaseAttrScope.toArray(), ",")); //String类型 这里利用了set集合元素不能相同的原理,做了虑重,queryForm从之前的2个变为4个,缩小查询范围:(多添加的这2个条件,并不会造成查询结果数据不准确的影响,而是之前没有用上)
在ibais中,in()的写法,切记用“$”,不用“#”,否则只会匹配分隔符前第一个数,比如(3,4,5)只会匹配到3.
就这样之后,再看查询:
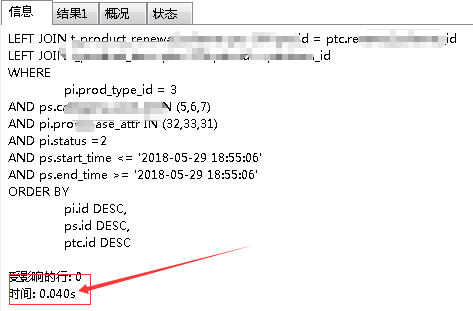
从30s变为了0.04s,这就是优化神奇的地方啊。