percona-toolkit 它是一组高级命令行工具的集合,主要用来查看当前服务的摘要信息,磁盘检测,分析慢查询日志,查找重复索引,实现表同步等等。
提示:本次实验主要是多数据库操作,试验系统为centos7 先做主从同步,我的分类mysql 里边有详细操作
1 )主从上下载安装percona-toolkit RPM 包
wget https://www.percona.com/downloads/percona-toolkit/3.1.0/binary/redhat/7/x86_64/percona-toolkit-3.1.0-2.el7.x86_64.rpm
安装

使用pt 加两下tab命令出现percona-toolkit 工具
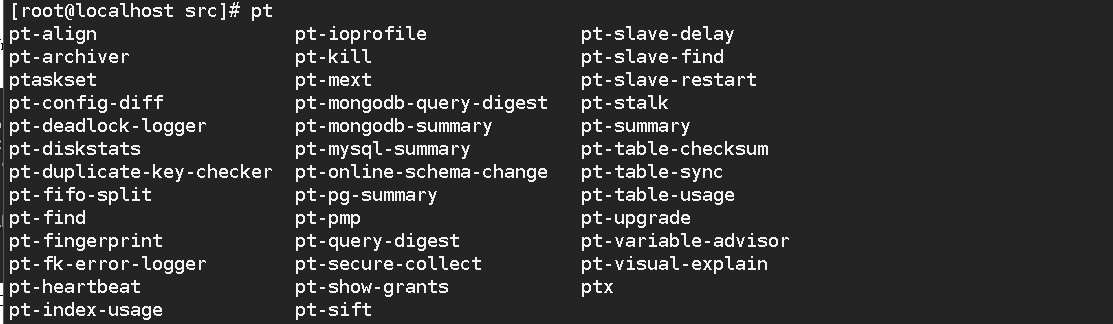
安装压测工具

2)***********************************************************下面介绍比较常用的3种工具*********************************************************
1.
pt-heartbeat:主要是用来用于监控主从延迟的工具
它的原理:
主库创建一张heartbeat表,表中有个时间戳字段。主库上pt-heartbeat的update线程会在指定时间间隔更新时间戳。
从库上的pt-heartbeat的monitor线程会检查复制的心跳记录,这个记录就是主库修改的时间戳。然后和当前系统时间进行对比,得出时间上的差异,差异值就是延迟的时间大小。由于heartbeat表中有server_id字段,在监控某个从库的延迟时指定参考主库的server_id即可。
使用参数介绍:
注意:需要指定的参数至少有 --stop,--update,--monitor,--check。
其中--update,--monitor和--check是互斥的,--daemonize和--check也是互斥。
`--ask-pass`:隐式输入MySQL密码
`--charset`:字符集设置
`--check`:检查从的延迟,检查一次就退出,除非指定了--recurse会递归的检查所有的从服务器。
`--check-
read
-only`:如果从服务器开启了只读模式,该工具会跳过任何插入。
`--create-table`:在主上创建心跳监控的表,如果该表不存在。可以自己建立,建议存储引擎改成memory。通过更新该表知道主从延迟的差距。
CREATE TABLE heartbeat (
ts varchar(26) NOT NULL,
server_id int unsigned NOT NULL PRIMARY KEY,
file
varchar(255) DEFAULT NULL, -- SHOW MASTER STATUS
position bigint unsigned DEFAULT NULL, -- SHOW MASTER STATUS
relay_master_log_file varchar(255) DEFAULT NULL, -- SHOW SLAVE STATUS
exec_master_log_pos bigint unsigned DEFAULT NULL -- SHOW SLAVE STATUS
);
heratbeat表一直在更改ts和position,而ts是我们检查复制延迟的关键。
`--daemonize`:执行时,放入到后台执行
`--user | -u`:连接数据库的帐号
`--database | -D`:连接数据库的名称
`--host|-h`:连接的数据库地址
`--password | -p`:连接数据库的密码
`--port | -P`:连接数据库的端口
`--socket | -S`:连接数据库的套接字文件
`--
file
【--
file
=output.txt】`:打印--monitor最新的记录到指定的文件,很好的防止满屏幕都是数据的烦恼。
`--frames 【--frames=1m,2m,3m】`:在--monitor里输出的[]里的记录段,默认是1m,5m,15m。可以指定1个,如:--frames=1s,多个用逗号隔开。可用单位有秒(s)、分钟(m)、小时(h)、天(d)。
`--interval`:检查、更新的间隔时间。默认是见是1s。最小的单位是0.01s,最大精度为小数点后两位,因此0.015将调整至0.02。
`--log`:开启daemonized模式的所有日志将会被打印到制定的文件中。
`--monitor`:持续监控从的延迟情况。通过--interval指定的间隔时间,打印出从的延迟信息,通过--
file
则可以把这些信息打印到指定的文件。
`--master-server-
id
`:指定主的server_id,若没有指定则该工具会连到主上查找其server_id。
`--print-master-server-
id
`:在--monitor和--check 模式下,指定该参数则打印出主的server_id。
`--recurse`:多级复制的检查深度。模式M-S-S...不是最后的一个从都需要开启log_slave_updates,这样才能检查到。
`--recursion-method`:指定复制检查的方式,默认为processlist,hosts。
`--update`:更新主上的心跳表。
`--replace`:使用--replace代替--update模式更新心跳表里的时间字段,这样的好处是不用管表里是否有行。
`--stop`:停止运行该工具(--daemonize),在
/tmp/
目录下创建一个“pt-heartbeat-sentinel” 文件。后面想重新开启则需要把该临时文件删除,才能开启(--daemonize)。
`--table`:指定心跳表名,默认heartbeat。



主上操作延迟工具后台运行
下面这条命令是在主库上面建表

主库都查看下pt-heartbeat 是否有这张表 ,如果主从没问题从库也会有。
在主库上一次执行准备开始最后清除压测工具的数据

准备执行完查看表是否建立

在从上执行这条命令
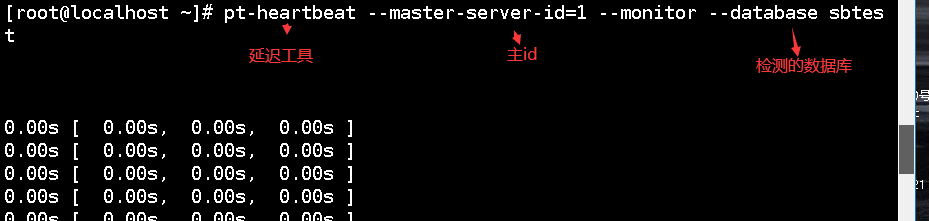
主库上出现这个说明结束了
******************************************pt-slave-restart是一个可以跳过特定错误并自动重启slave的工具。******************************************
pt-slave-restart监控一个或者多个MySQL复制slave,试图跳过引起错误的语句。它以指数变化的睡眠时间职能地检查slave。你可以指定要跳过的错误然后运行slave一直到一个确定的binlog位置。
pt-slave-restart一旦检测到slave有错误就会打印一行。默认情况下该打印行为:时间戳、连接信息、relay_log_file,relay_log_pos,以及last_errno。你可以使用--verbose选项添加更多信息,也可以使用--quiet选项阻止所有输出
- ` --always ` :永不停止slave线程,手工停止也不行
- ` --ask-pass` :替换`-p`命令,不显示密码输入
- ` --error-numbers` :指定跳过哪些错误,可用`,`进行分隔
- ` --error-text` :根据错误信息进行匹配跳过
- ` --log` :输出到文件
- ` --recurse` :在主端执行,监控从端
- ` --runtime ` :工具执行多长时间后退出:默认秒, m=minute,h=hours,d=days
- ` --slave-user --slave-password` :从库的账号密码,从主端运行时使用
- ` --skip-count ` :一次跳过错误的个数,胆大的可以设置大些,不指定默认1个
- `--master-uuid` :级联复制的时候,指定跳过上级或者上上级事务的错误
- ` --
until
-master` :到达指定的master_log_pos,
file
位置后停止,格式:”
file
:pos“
- `--
until
-relay` :和上面一样,但根据relay_log的位置来停止
- `--
sleep
`:默认值为1,检查slave间隔的初始
sleep
秒数。
实例:
#1. 在master上创建表

#2. 在slave上插入数据

#3. 在master上插入数据
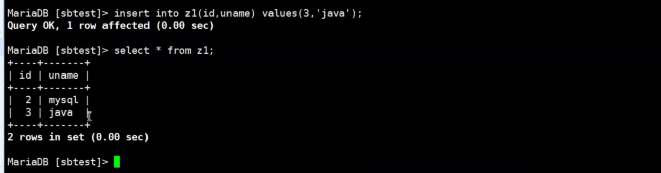
#4. 在slave上查看复制状态
show slave status \G;
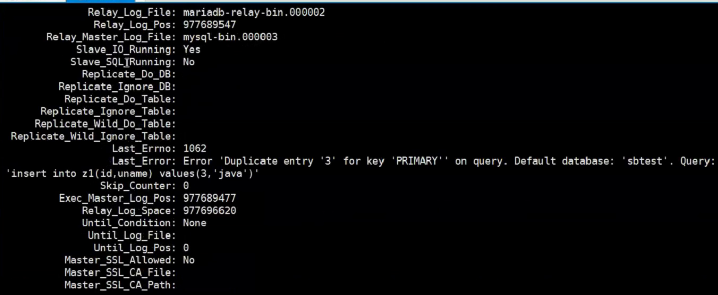
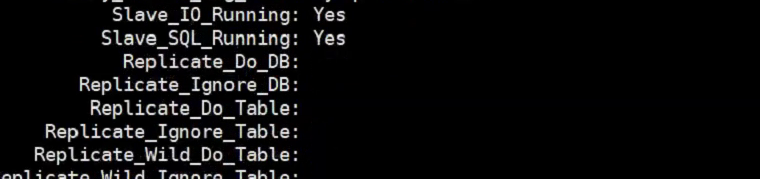
5)在从上可以通过以下命令解决,这个并不能真正解决问题。只是跳过这个报错

****************************************************************************************************************
3 pt-table-checksum
pt-table-checksum工具用来检查主从数据一致性
3.1 pt-table-checksum 原理
pt-table-checksum用于校验主从数据的一致性,该命令在主库上执行校验,然后对复制的一致性进行检查,来对比主从之间的校验值,并输出对比结果
3.2 pt-table-checksum 主要参数介绍
|
1
2
3
4
5
6
7
8
9
|
- `--[no]check-replication-filters`:是否检查复制的过滤器,默认是
yes
,建议启用不检查模式。
- `--databases | -d`:指定需要被检查的数据库,多个库之间可以用逗号分隔。
- `--[no]check-binlog-
format
`:是否检查binlog文件的格式,默认值
yes
。建议开启不检查。因为在默认的row格式下会出错。
- `--replicate`:把checksum的信息写入到指定表中。
- `--replicate-check-only`:只显示不同步信息
|
主库上操作:

|
1
2
3
4
5
6
7
8
9
|
#解释:
`TS` :完成检查的时间。
`ERRORS` :检查时候发生错误和警告的数量。
`DIFFS`:0表示一致,1表示不一致。当指定--no-replicate-check时,会一直为0,当指定--replicate-check-only会显示不同的信息。
`ROWS` :表的行数。
`CHUNKS` :被划分到表中的块的数目。
`SKIPPED` :由于错误或警告或过大,则跳过块的数目。
`TIME` :执行的时间。
`TABLE` :被检查的表名。
|
|
1
2
3
4
5
|
【注意】:
1)根据测试,需要一个即能登录主库,也能登录从库的账号;huazai007 123456
2)只能指定一个host,必须为主库的IP;
3)在检查时会向表加S锁;
4)运行之前需要从库的同步IO和SQL进程是YES状态。
|
4 pt-table-sync
用来修复主从数据不一致
4.1 pt-table-sync 原理
pt-table-sync高效的同步MySQL表之间的数据,他可以做单向和双向同步的表数据。他可以同步单个表,也可以同步整个库。它不同步表结构、索引、或任何其他模式对象。所以在修复一致性之前需要保证他们表存在。
4.2 pt-table-sync 主要参数介绍
|
1
2
3
4
5
6
7
8
9
|
`--replicate` :指定通过pt-table-checksum得到的表,这2个工具差不多都会一直用。
`--databases` : 指定执行同步的数据库。
`--tables` :指定执行同步的表,多个用逗号隔开。
`--
sync
-to-master` :指定一个DSN,即从的IP,他会通过show processlist或show slave status 去自动的找主。
`h=` :服务器地址,命令里有2个ip,第一次出现的是Master的地址,第2次是Slave的地址。
`u=` :帐号。
`p=` :密码。
`--print` :打印,但不执行命令。
`--execute :执行命令。
|
4.3 pt-table-sync 实战
主库上执行以下命令
#print 修复命令
会把修复的sql语句打印出来
print 修复命令,会把修复的sql语句打印出来
#execute 修复命令
##再使用pt-table-checksum 验证下
最后在查看下状态
在数据库中查看数据是否一致

最后总结下: