最近机器学习课有个作业是实现softmax多分类鸢尾花数据集,之前从来没推过softmax的公式,直接拿来用了,好好研究了一下,发现这个原理的推导还是有不少复杂的东西,分享一下结果,公式比较复杂,直接上手写了。
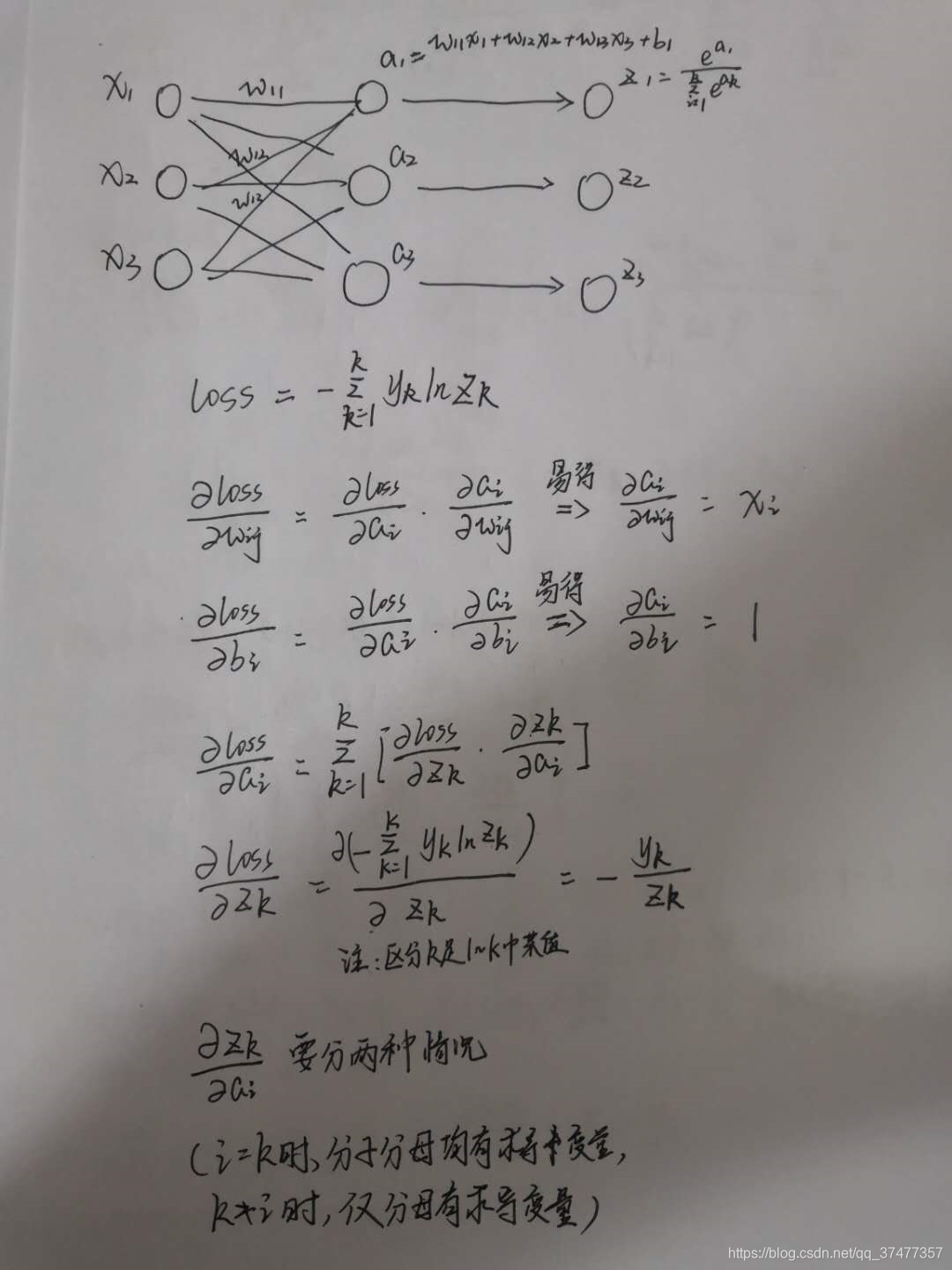

根据推导的结果,利用numpy手动实现了基于Iris数据集的softmax多分类,准确率有97.77%
import numpy as np
from sklearn import datasets
from matplotlib import pyplot as plt
class softmax_classify:
def __init__(self,lr=0.1,epoch = 500,x_train=[],y_train=[],x_test=[],y_test=[]):
self.learing_rate = lr #学习率
self.epoch = epoch #迭代次数
self.train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据
# 初始化参数
self.w = np.random.normal(0,0.005,(4,3))
self.b = np.random.normal(0,0.005,(1,3))
# 读入训练集与测试集
self.x_train = x_train
self.y_train = y_train
self.x_test = x_test
self.y_test = y_test
# 计算线性函数
def cal_a(self,features):
return (np.dot(features,self.w) + self.b)
# 计算softmax处理后的值
def cal_softmax(self,a):
z = np.exp(a)
sum_z = np.sum(z,axis=1).reshape(-1,1)
return z/sum_z
# 计算交叉熵损失函数
def loss(self,z,y):
# print(z)
# print(y)
return -(np.log(z[0][y]))
# 梯度下降优化参数
def gradient(self,feature,z,y):
temp = np.zeros((1,3))
temp[0][y] = 1
feature = feature.reshape(4,1)
self.w -= self.learing_rate*np.dot(feature,(z-temp))
self.b -= self.learing_rate*(z-temp)
# 训练过程
def train(self):
for epoch in range(self.epoch):
loss_all = 0
for i in range(len(self.x_train)):
x = self.x_train[i]
y = self.y_train[i]
# print(x,'\n',y)
z = self.cal_softmax(self.cal_a(x))
loss = self.loss(z,y)
loss_all += loss
self.gradient(x,z,y)
print("Epoch {}, loss: {}".format(epoch, loss_all))
self.train_loss_results.append(loss_all)
# 绘制 loss 曲线
plt.title('Loss Function Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Loss') # y轴变量名称
plt.plot(self.train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss
plt.legend() # 画出曲线图标
plt.show() # 画出图像
# 预测测试集并输出准确率
def test(self):
right_num = 0
for i in range(len(self.x_test)):
x = self.x_test[i]
y = self.y_test[i]
z = self.cal_softmax(self.cal_a(x))
pred = np.argmax(z)
# print(i,":",pred)
# print("y:",y)
if(pred == y):
right_num += 1
print("acc:",float(right_num/len(self.x_test)))
def main():
# 利用sklearn的datasets下载iris数据集
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
# 打乱数据的顺序,使用同一个乱序种子保证特征--标签对应
np.random.seed(100)
np.random.shuffle(x_data)
np.random.seed(100)
np.random.shuffle(y_data)
# 随机抽取70%的数据为训练集,30%为测试集
# 由于已经打乱了顺序,直接选取前70%为训练集,其余为测试集即可
dataset_size = len(x_data)
trainData_size = int(dataset_size*0.7)
testData_size = dataset_size - trainData_size
x_train = x_data[:trainData_size]
y_train = y_data[:trainData_size]
x_test = x_data[trainData_size:]
y_test = y_data[trainData_size:]
print(x_train,'\n',y_train)
print(x_test,'\n',y_test)
lr = 0.01 #学习率0.01
epoch = 1000 #迭代1000次
iris_classify = softmax_classify(lr,epoch,x_train,y_train,x_test,y_test)
iris_classify.train()
iris_classify.test()
if __name__ == "__main__":
main()
损失函数曲线:
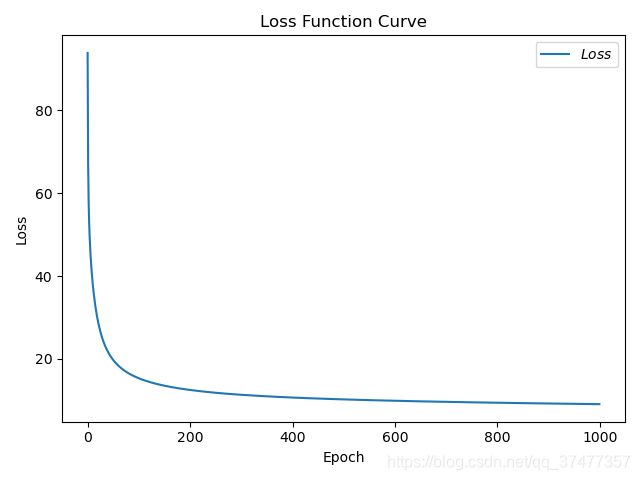
准确率:


