【第一回】---python基础
Ⅰ、数据类型
1.1 列表篇
1):添加元素
a. list.append(88) b. l1.insert(3,‘alex’) //在索引为3的元素前插入对象alex
2): 列表排序
l1.sort();
3):删除元素
l1.pop(5) # 移除索引5的元素 l1.pop() # 默认删除最后一个元素
1.2 字典篇
1):字典添加元素
a. Test[‘价格’] = 100
b. xx = {‘hhh’:‘gogogo’}
Test.update(xx)
2):字典删除元素
a. del[aa[‘adress’]] b. vv = aa.pop(‘key名称’)
3):字典的遍历
for item in dict.items(): print(item)
附加:bool类型 (Python中以下情况默认为False)
Ⅰ:为0的数字,包括0,0.0
Ⅱ:空字符串,包括’’, “”
Ⅲ:表示空值的None
Ⅳ:空集合,包括(),[],{} 其他的值都认为是True。
Ⅱ、迭代器、生成器、装饰器
1、迭代器:
a、可迭代对象:只要能iter(对象)的就是可迭代对象。如:list,truple,str,dict,set可以执行遍历都是可迭代对象。
备注:可迭代对象转换为迭代器,只需要执行iter(对象)即可
例1:输出一个列表list1,使用iter方法之后为一个迭代器
>>list1 = [1,2,3,4] >>print (iter(list1)) //生成的为迭代器 <list_iterator object at 0x0000027713494F28> >>print (next(list1)) //报错Error:TypeError: 'list' object is not an iterator
b、迭代器:可迭代对象并且能实现next(对象)叫迭代器
例1:输出一个列表list1,使用iter转换为迭代器,再执行next()方法
>>list1 = [1,2,3,4] >>iter1 = iter(list1) //转换为一个迭代器 >>print (next(iter1)) //输出第一个结果 1
2、生成器:生成器生成有两种方式,一种是列表生成式,一种为yield
a、yield,,在函数中可以先将yield想象成return
def foo():
print("starting........")
while True:
res = yield 4
print("res:",res)
g = foo()
print(next(g))
print("*"*20)
print(next(g))
输出:
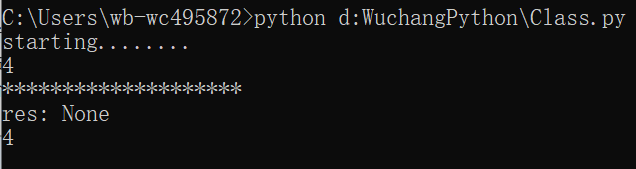
解析:(1)、如果没有yield,g = foo() 输出starting........,存在yield为生成器无结果输出,故g = foo()无结果输出
(2)、第一次遇到next(g)之后,函数开始执行,输出starting........。加上print,将函数结果yield 4返回,故print(next(g))输出前两行
(3)、输出20个*
(4)、第二次遇到next(g)之后,函数从yield之后开始执行,此时res的值已经返回,故输出的结果为none,print(next(g))将yield看作return,故再次打印输出4
例2:包子铺要做包子,如果一次性做1000个,可能存在卖不完浪费的情况,如果吃一个包子,你做一个包子,那么这就不会占用太多空间存储了。
def eat(): for i in range(1,10000): yield '包子'+str(i) e = eat() for i in range(200): next(e)
【第二回】---python函数
Ⅰ、递归函数
从某个目录里面查找日志文件,如果里面的内容是目录,继续执行函数
import os, sys, datetime,re
# nginx日志存放的路径
nginxLogPath="/opt/nginx-1.9.5/logs/"
# 获取昨天的日期
yesterday = (datetime.date.today() + datetime.timedelta(days = -1)).strftime("%Y-%m-%d")
# nginx启动的pid文件
PID = "/var/run/nginx.pid"
def cutNginxLog(path):
"""
切割nginx日志函数
:param path: 日志文件的第一级目录
:return:
"""
logList = os.listdir(path) # 判断传入的path是否是目录
for logName in logList: # 循环处理目录里面的文件
logAbsPath = os.path.join(path, logName)
if os.path.isdir(logAbsPath): # 如果是目录,递归调用自己,继续处理
cutNginxLog(logAbsPath)
else: # 如果是日志文件,就进行处理
# 分割日志
re_Num = re.compile(r'^[a-zA-Z]')
# 判断日志文件是否是字母开头,如果是日期开头就不切割
if re_Num.search(logName):
logNewName = yesterday + "_" + logName # 新日志文件名称列如:2018-11-8_access.log
oldLogPath = os.path.join(path, logName) # 旧日志文件绝对路径
newLogPath = os.path.join(path, logNewName) # 新日志文件绝对路径
os.rename(oldLogPath, newLogPath)
cmd = " kill -USR1 `cat %s` "% PID
res = os.system(cmd)
if res != 0:
return "重新加载nginx失败"
cutNginxLog(nginxLogPath)
【第三回】---python模块
Ⅰ、datetime模块
a、获取当前时间
import datetime
print(datetime.datetime.now().strftime("%Y-%m-%d")) #获取当前时间
b、获取当天时间
import datetime
print(datetime.date.today().strftime("%Y-%m-%d"))
c、转换为需要的格式
import datetime
print(datetime.datetime.now().strftime('%a, %b %d %H:%M'))
输出

Ⅱ、sys模块
Ⅲ、os模块
a、os.listdir(path) #判断传入的path是否是目录,返回值为列表
import os, sys, datetime,re
nginxLogPath="/var/log/nginx"
def cutNginxLog(path):
logList = os.listdir(path);
print(logList)
cutNginxLog(nginxLogPath)
列表形式输出当前所有目录和文件:

b、os.path.isdir()函数:判断传入的是否为目录,返回True/False
import os, sys, datetime,re nginxLogPath="/var/log/nginx" def cutNginxLog(path): logList = os.path.isdir(path); print(logList) cutNginxLog(nginxLogPath)
输出 True

c、open和open with
Ⅰ、open的read用法
import os, sys
f = open('/root/test.txt', 'r')
print(f.read())
输出:

Ⅱ:open with 由于每次打开文件都要try...finally命令,open with解决了这个问题
例1、with open as的read方法:
import os, sys
with open('/root/test.txt', 'r') as f:
print(f.read())
输出:

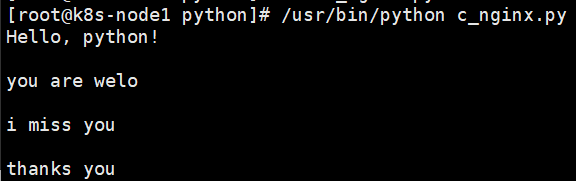
例2、with open as的write方法:
import os, sys
with open('/root/test.txt', 'wb') as f:
f.write('Hello, python!')
输出:

例3、readlines方法
import os, sys
with open("/root/test.txt","r") as file:
for line in file.readlines():
print line
输出:
d、os.system();将字符串转换成命令执行
如果执行成功返回0,否则执行失败
import os, sys,datetime
yes = os.system("cd /root")
if yes == 0:
print("hello world")
输出:

e、os.path.join()函数:连接两个或更多的路径名组件
import os
Path1 = 'home'
Path2 = 'develop'
Path3 = 'code'
Path20 = os.path.join(Path1,Path2,Path3)
print ('Path20 = ',Path20)
输出:Path20 = home\develop\code
Ⅳ、re模块
a、re.compile #设定规则
①: rr = re.compile(r'WAN\w',re.I) #匹配以WAN开头的单词,re.I代表忽略大小写 ②: re_Num = re.compile(r'^[a-zA-Z]') #设定规则,判断文件是否以字母开头
if re_Num.search(logName):
logNewName = yesterday + "_" + logName
b、re.findall #将匹配到的结果以列表形式输出
c、re.I #忽略大小写
import os, sys, datetime,re content = "Citizen wang,always fall in love with neighbour,WANG" rr = re.compile(r'WAN\w',re.I) #匹配以WAN开头的单词,re.I代表忽略大小写 a = rr.findall(content) print(a)
输出如下:

d、re.match()函数 从头匹配一个符合规则的字符串,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
pattern: 正则模型
string : 要匹配的字符串
falgs : 匹配模式
match() 方法一旦匹配成功,就是一个match object对象,而match object对象有以下方法:
group() :返回被 RE 匹配的字符串
start() :返回匹配开始的位置
end() :返回匹配结束的位置
import re
# re.match 返回一个Match Object 对象
# 对象提供了 group() 方法,来获取匹配的结果
result = re.match("hello","hello,world")
if result:
print(result.group())
else:
print("匹配失败!")
输出

e、re.search()函数 在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None
group() :返回被 RE 匹配的字符串
import re re_Num = re.compile(r"\d+") #指定正则匹配规则 ret = re_Num.search( "阅读次数为 9999") #从文中寻找符合规则的情况 print(ret.group())
输出:
