SpringBoot整合redis-cluster集群以及redis-cluster集群详细安装 环境要求需要六台虚拟机
一.安装redis
去官网下载tar包,上传到/home/software下面
[root@huaxinfeng25 software]# tar -zxvf redis-5.0.5.tar.gz #解压缩
[root@huaxinfeng25 software]# yum install gcc-c++ #安装c++环境
#进入到 redis-5.0.5 目录,进行安装:
[root@huaxinfeng25 redis-5.0.5]# make && make -j 4 install #编译
设置开机自启动:
在/home/software/redis-5.0.5/utils目录下
[root@huaxinfeng25 utils]# cp redis_init_script /etc/init.d/
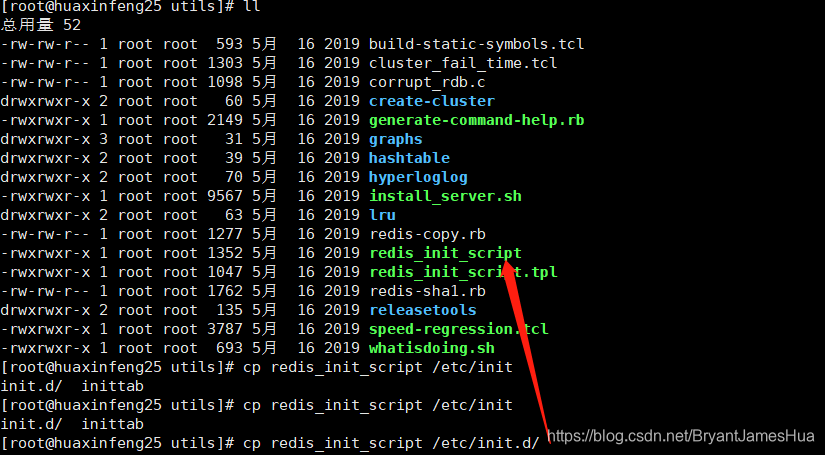
创建/usr/local/redis用于存放配置文件
[root@huaxinfeng25 utils]# cd /usr/local/
[root@huaxinfeng25 local]# mkdir redis
[root@huaxinfeng25 redis]# cd /home/software/redis-5.0.5/
[root@huaxinfeng25 redis-5.0.5]# cp redis.conf /usr/local/redis/ #拷贝配置文件
修改redis.conf核心配置文件
136 改 daemonize no
136 为 daemonize yes
263 改 dir ./
263 为 dir /usr/local/redis/working
69 改 bind 127.0.0.1
69 为 bind 0.0.0.0
修改密码(你也可以不改,不改不利于后续操作还是改了把)
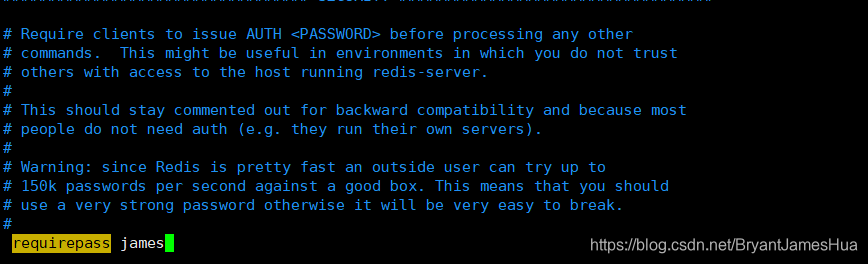
进入
[root@huaxinfeng25 redis]# cd /etc/init.d/
[root@huaxinfeng25 init.d]# vim redis_init_script
CONF="/usr/local/redis/redis.conf"
[root@huaxinfeng25 init.d]# chmod +766 redis_init_script #给权限
[root@huaxinfeng25 init.d]# mkdir /usr/local/redis/working #创建文件夹
[root@huaxinfeng25 init.d]# ./redis_init_script start #启动redis
[root@huaxinfeng25 init.d]# ps -aux | grep redis #检查redis进程是不是存在
[root@huaxinfeng25 init.d]# chkconfig redis_init_script on #设置开机自启动
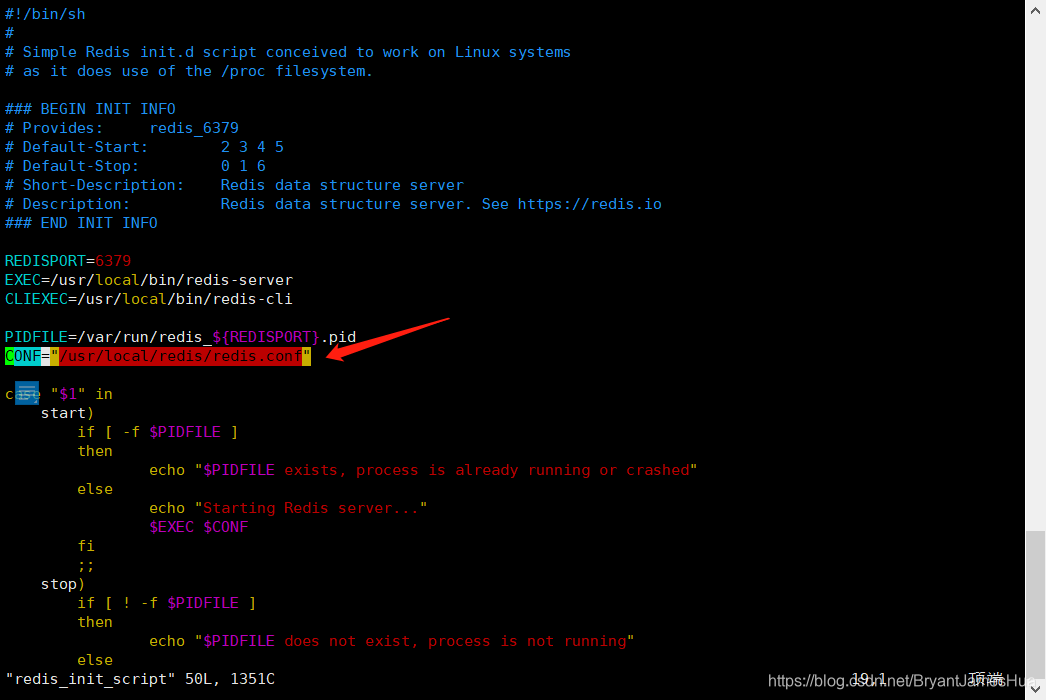
启动成功的模样

[root@huaxinfeng25 redis]# redis-cli
127.0.0.1:6379> auth james
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> get age
"18"
redis的主从复制和哨兵这里我就不说了,网上文章有很多的。我们主要说的是cluster集群
二.安装cluster集群
需要六台虚拟机或者六台真实的机器
为什么使用cluster集群呢?
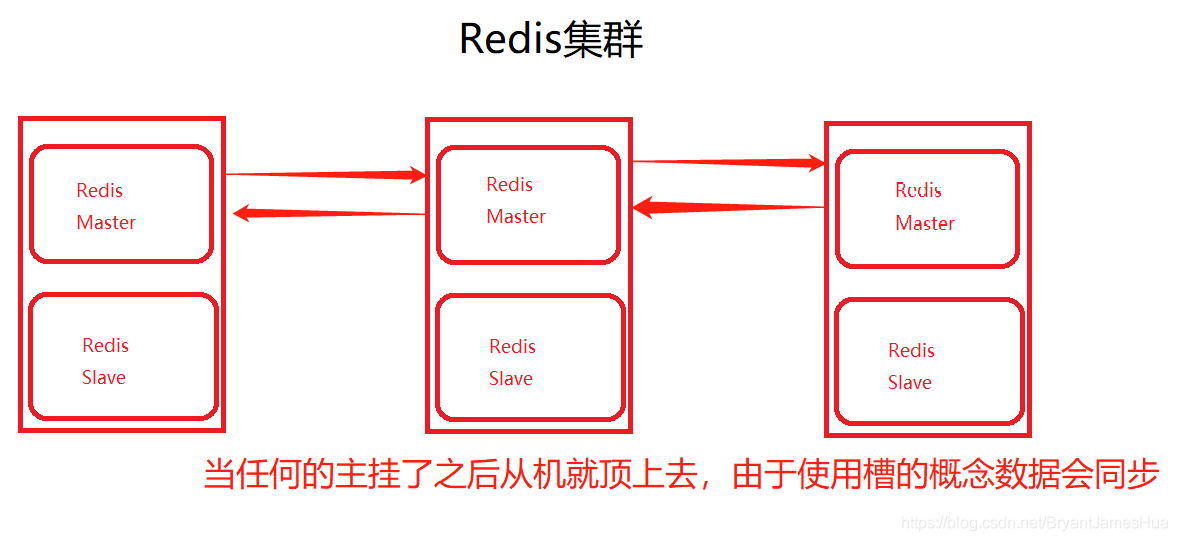
因为即使在主从复制和哨兵模式下,当主机出现问题从机变换为主机的也是需要时间的,可能是1秒,2秒,这个时间段会造成数据的丢失和不同步。再者同步也是有时间间隔的,如果时间间隔中主节点mster突然宕机也会影响数据的正确性,所以我们要使用cluster集群,他能通过槽点这个工具保证数据的同步
单个master容量有限,数据达到一定程度会有瓶颈,这个时候可以通过水平扩展为多master-slave成为集群。
我们学习redis-cluster:他不但可以支撑多个master-slave,支持海量数据,而且能实现高可用与高并发。
特点:
每个节点知道彼此之间的关系,也会知道自己的角色,当然他们也会知道自己存在与一个集群环境中,他们彼此之间可以交互和通信,比如ping pong。那么这些关系都会保存到某个配置文件中,每个节点都有,这个我们在搭建的时候会做配置的。
客户端要和集群建立连接的话,只需要和其中一个建立关系就行。
某个节点挂了,也是通过超过半数的节点来进行的检测,客观下线后主从切换,和我们之前在哨兵模式中提到的是一个道理。
Redis中存在很多的插槽,又可以称之为槽节点,用于存储数据,这个先不管,后面再说。
注意
构建Redis集群,需要至少3个节点作为master,以此组成一个高可用的集群,此外每个master都需要配备一个slave,所以整个集群需要6个节点,这也是最经典的Redis集群,也可以称之为三主三从,容错性更佳。所以在搭建的时候需要有6台虚拟机。使用单实例的Redis 去克隆即可 。
克隆
并修改mac地址(除了第一台剩下的每一台多需要修改呢)
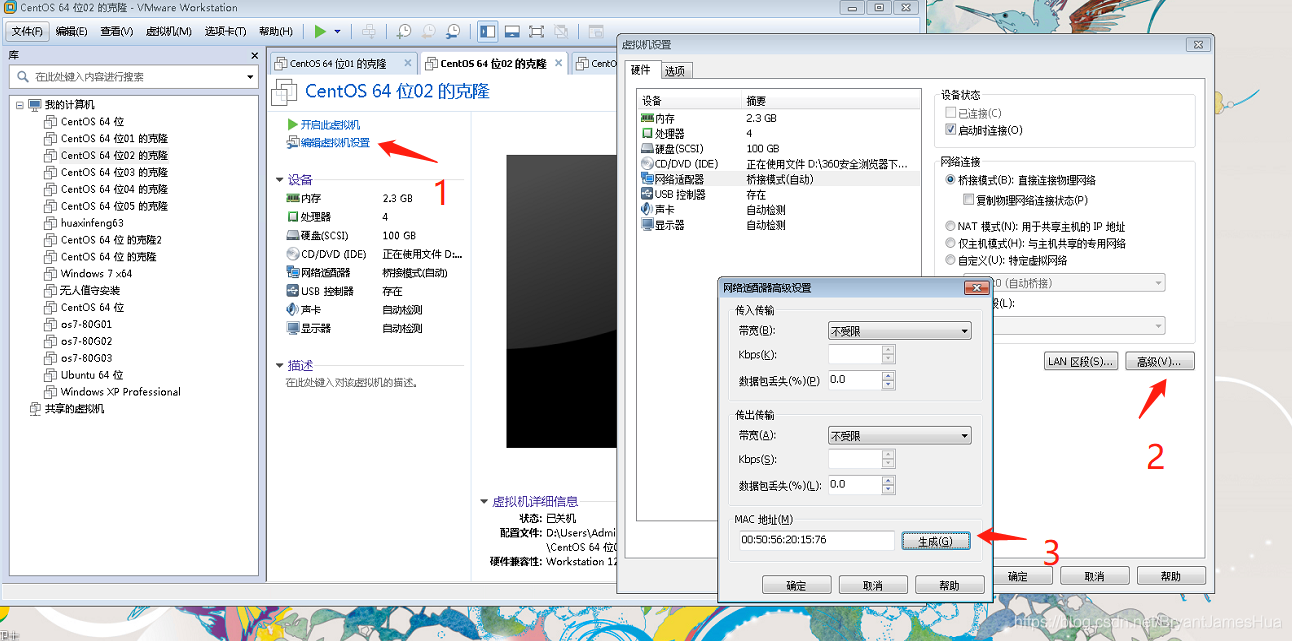
全部打开
在redis.conf中这样配置(六台配置要一样哦)
#开启集群模式
cluster-enabled yes
# 每一个节点需要有一个配置文件,需要6份。每个节点处于集群的角色都需要告知其他所有节点,彼此知道,这个文件用于存储集群模式下的集群状态等信息,这个文件是由redis自己维护,我们不用管。如果你要重新创建集群,那么把这个文件删了就行
cluster-config-file nodes-6379.conf
# 超时时间,超时则认为master宕机,随后主备切换
cluster-node-timeout 5000
# 开启AOF
appendonly yes
#搭建集群
[root@huaxinfeng25 working]# redis-cli -a james --cluster create 192.168.1.25:6379 192.168.1.11:6379 192.168.1.12:6379 192.168.1.13:6379 192.168.1.14:6379 192.168.1.15:6379 --cluster-replicas 1
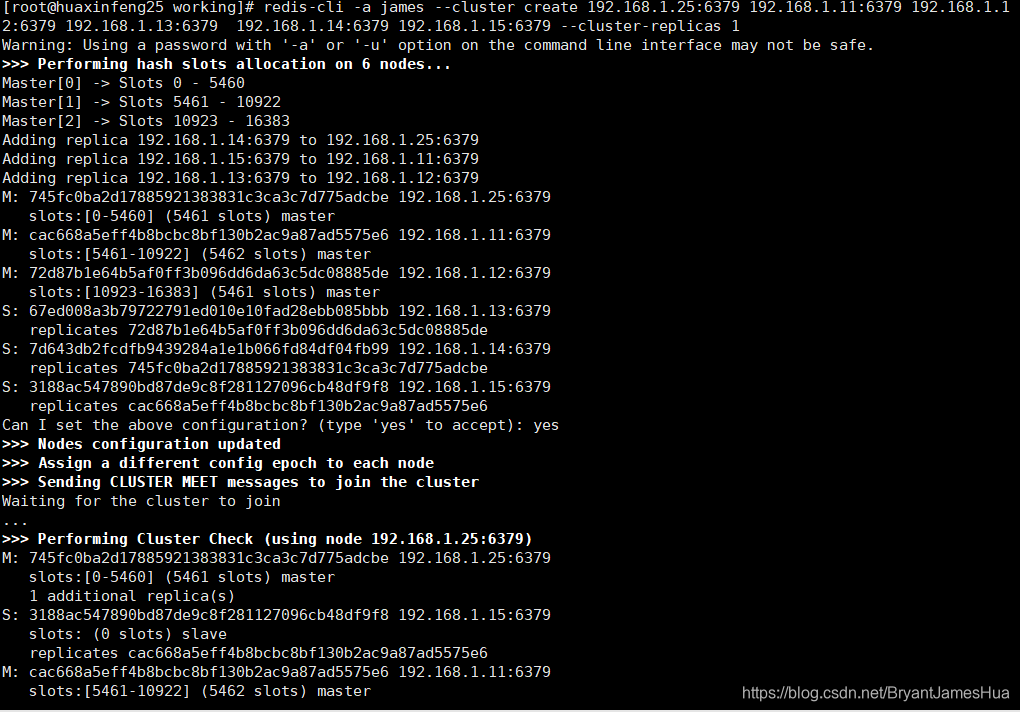
检查节点
[root@huaxinfeng25 working]# redis-cli -a james --cluster check 192.168.1.25:6379

集群构建成功了
那么我们来看这个slots 槽节点,平均分配的(主节点分配)
M: 745fc0ba2d17885921383831c3ca3c7d775adcbe 192.168.1.25:6379
slots:[0-5460] (5461 slots) master
M: cac668a5eff4b8bcbc8bf130b2ac9a87ad5575e6 192.168.1.11:6379
slots:[5461-10922] (5462 slots) master
M: 72d87b1e64b5af0ff3b096dd6da63c5dc08885de 192.168.1.12:6379
slots:[10923-16383] (5461 slots) master
S: 67ed008a3b79722791ed010e10fad28ebb085bbb 192.168.1.13:6379
replicates 72d87b1e64b5af0ff3b096dd6da63c5dc08885de
S: 7d643db2fcdfb9439284a1e1b066fd84df04fb99 192.168.1.14:6379
replicates 745fc0ba2d17885921383831c3ca3c7d775adcbe
S: 3188ac547890bd87de9c8f281127096cb48df9f8 192.168.1.15:6379
replicates cac668a5eff4b8bcbc8bf130b2ac9a87ad5575e6
槽slot怎么存储数据呢,比如我们set一个key,他会我们set的这个key进行一个hash算法,然后进行hash取模,来计算存到哪个槽节点上面
整合redis
首先你在pom.xml引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
这样写代码
/*@Controller*/
@ApiIgnore
@RestController
@RequestMapping("redis")
public class RedisController {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private RedisOperator redisOperator;
@GetMapping("/set")
public Object set(String key,String value){
System.out.println(key);
System.out.println(value);
redisOperator.set(key,value);
return "hello world~";
}
@GetMapping("/get")
public Object get(String key){
return redisOperator.get(key);
}
@GetMapping("/delete")
public Object delete(String key){
redisOperator.del(key);
return "ok";
}
}
在配置文件中这样写
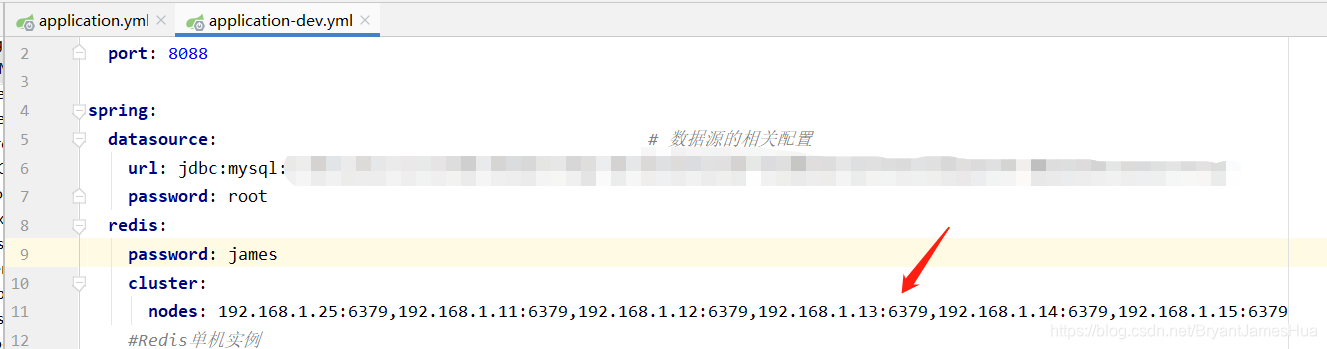

好啦可以拉
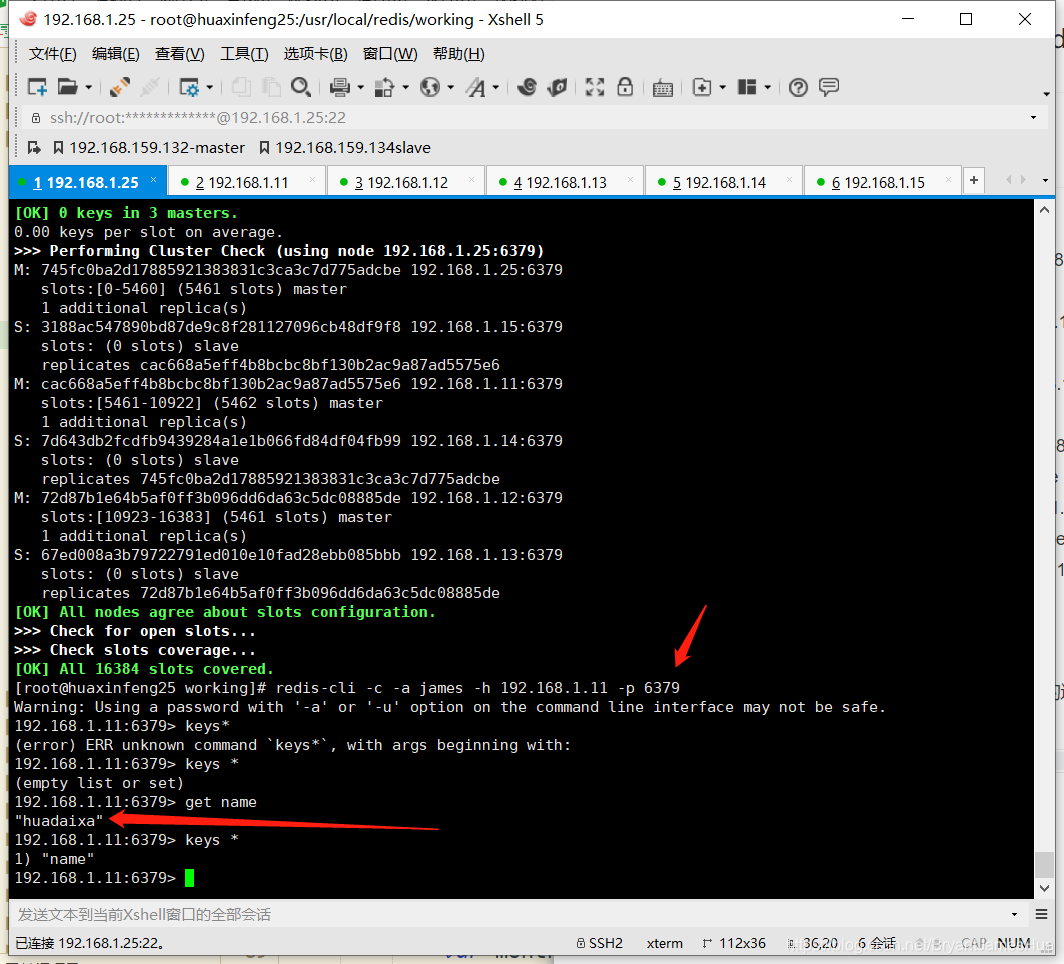
主意:key是存在不同机器上面的,你set到某一台机器的话只是某一台机器私有的当你要get的时候会自动跳动到这个机器上面的,会很方便
你可能会报错
[ERR] Node 192.168.1.12:6379 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
看ip哪个错了就去删除working下面的aof rdb等后缀文件然后重启redis,还要是不行把working下面所有的全部给删除了
