一、AWR报告生成步骤
起因,因为一个网站的查询效率十分的低下,客户已经很不满意,提了好几次。所以公司就让我去现场看看具体是什么情况。分别可以从这几项入手:1、数据库内存组件大小对比:show parameter sga; (查看内存占用情况)
2、对比数据库之间的索引,判断是否正常引用索引;3、调整数据库的优化方式和优化级别;4、度量磁盘 I/O吞吐量是否一致;5、查看操作系统参数。
对于SQL调优,局部的SQL,我们可以看执行计划。但是对于整个系统而言,看AWR报告,是比较能直观的感受到的。这边博客主要介绍下AWR。有不足的地方,还希望读者帮我指出来,感谢。
AWR全称Automatic Workload Repository,自动负载信息库,是Oracle 10g版本后推出的一种性能收集和分析工具,提供了一个时间段内整个系统的报表数据。通过AWR报告,可以分析指定的时间段内数据库系统的性能。
1.1 工具的选择
对于Oracle的数据,我们可以选择PL/SQL或者直接就sqlplus,干就完了。
sqlplus使用
冲冲冲~~~
进入数据库
sqlplus / as sysdba
PL/SQL使用
PL/SQL也可以使用,登录之后,选择文件(File)->新建(New)->命令窗口(Command Window)
1.2 自动创建快照
可跳过
开始压测后执行:
exec DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();
可以通过dba_hist_wr_control查看当前的配置情况,当前awr为每1小时做一次数据快照,保留时间为8天。
select * from dba_hist_wr_control;
修改配置,每隔30分钟收集一次,保存1天
execute dbms_workload_repository.modify_snapshot_settings(interval=>30,retention=>14000);
关闭AWR自动收集
SQL>exec dbms_workload_repository.modify_snapshot_settings (interval=>0,retention=>24*60);
注:10g默认是自动开启awr信息收集的,会对系统有一定的影响(很小);如果要关闭awr信息收集,只需设置interval参数为0即可。但interval设0后,AWR报告无法生成。
1.3 手工创建快照
除了有自动,当然还有手动
select dbms_workload_repository.create_snapshot() from dual;
1.4 生成AWR报告
在sqlplus或者PL/SQL使用命令,${ORACLE_HOME}是Oracle的安装路径
@/${ORACLE_HOME}/.../RDBMS/ADMIN/awrrpt.sql
例如我的命令如下:
@D:/app/Administrator/product/11.2.0/dbhome_1/RDBMS/ADMIN/awrrpt.sql
这个命令就是你awrrpt.sql 存在哪个文件夹下,然后执行这个sql
执行命令之后,会提示你输入一些参数
- (1) Enter value of report_type
意思是生成报告的格式有两种,html和txt,这里选择html - (2) Enter value of num_days
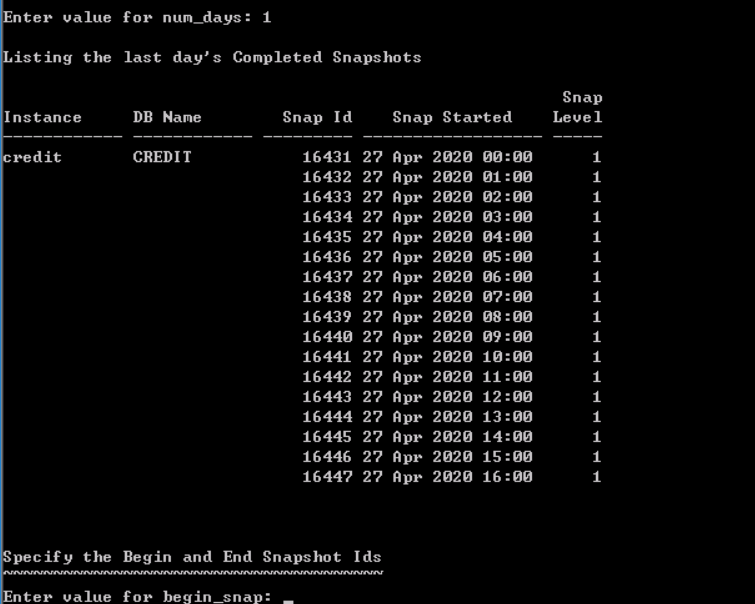
收集几天的报告信息,数字,可以输入1 - (3) Enter value of begin_snap
输入开始快照id,要根据日志打印的快照id范围来填

或者一天的报告。时间为0点到现在。日志打印的快照id范围为:16431~16447
我填写begin_snap为:16431 截止为16447
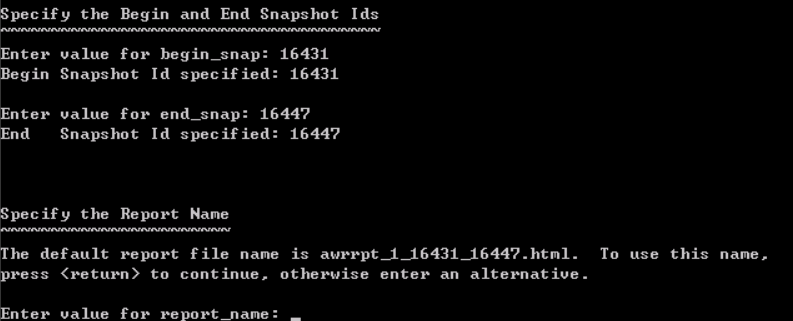
report_name则是你报告的命令,随意点:
要注意下:这个报告生成的位置,则位于你进cmd的时候,那个地址下:

我的则在C:\Users\Administrator文件夹下。
二、AWR报告分析
2.1 AWR之DB Time
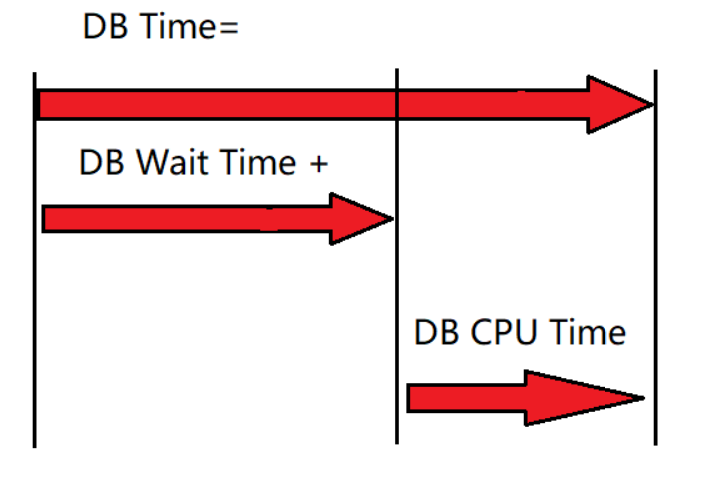
DB Time(请求时间)= DB Wait Time(DB等待时间)+ DB CPU Time(DB CPU服务时间)
上述等式中右边DB等待时间不包括后台进程上CPU开销的时间以及前台进程非空闲等待时间。
优化不仅仅是减少等待。它旨在改善最终用户的响应时间或最小化每个请求使用的平均资源。有时候这些需要一起进行调整,但在其他情况下,有权衡。例如,使用并行查询,并行查询或者并行DML则是更多的利用系统资源来达到快速完成事务或完成查询等相关业务。一般来说,可以调整的方式是减少或避免对系统资源的长时间占用或过度消耗。一旦当资源的占用减少,也就意味着资源可以服务更多的请求来达到提高吞吐量的目的。
由上图可知等待时间是所有等待各种数据库实例资源的总和。 CPU时间是实际工作在请求上花费的时间的总和。这些时间不一定由一个等待和一个CPU时间块组成。通常,进程将经历较短的DB资源等待,然后在CPU上短暂运行,并重复执行此操作。
因此优化包括减少或消除数据库资源等待时间并减少CPU时间。此定义适用于任何应用程序类型,在线事务处理(OLTP)或数据仓库(DW)。
注意:一个非常繁忙的系统显示更长的DB CPU时间,这可能会膨胀其他时间。
AWR报告头部
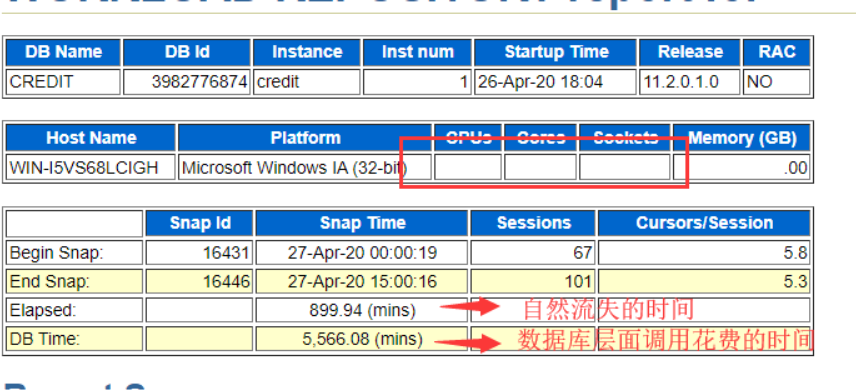
该数据库报告打印的时候,CPUS没有显示出来,本服务器为8CPUS
从上图可知,在自然流逝时间内,900分钟,DB层调用花费的时间为5566分钟。也即是说是自然时间的6倍左右,数据库处于正常状态。
当前数据库逻辑CPU为8个,因此每CPU平均服务时间为5566.08/8=695.76min
按前面DB Time的描述,DB Time = DB Wait Time + DB CPU Time 因此 695.76min需要进一步确认是否为真实的使用率。
2.2 Load Profile
load_profile指标主要用来显示当前系统的一些指示性能的总体参数,这里介绍一些Redo_size,用来显示平均每秒的日志尺寸和平均每个事务的日志尺寸,有时候可以结合Transactions这个每秒事务数,分析当前事务的繁忙程度
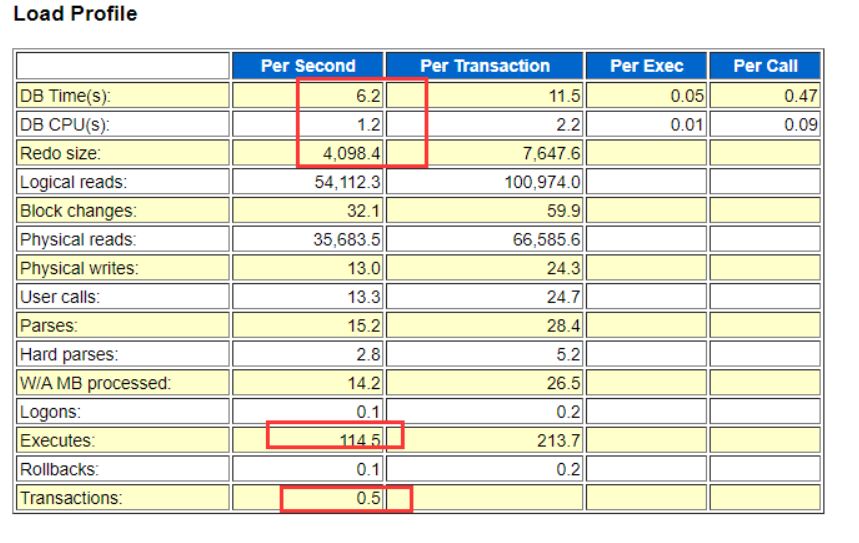
从上图可知,
DB Time(s) 行,每一个自然时间秒,DB Time对应为6.2s,据此推算6.2 * 899.94 * 60/60 约等于头部的DB Time 5566.08分钟。
DB CPU(s) 行,每一个自然时间秒,CPU的开销为1.2s,即899.94 * 60 * 1.2=64795s,也就是说花在CPU上的时间为1078分钟左右。
Redo size 行,每秒产生的redo较多,符合OLTP数据库业务场景。
Executes与Transactions也表明当前的业务场景为OLTP类型。
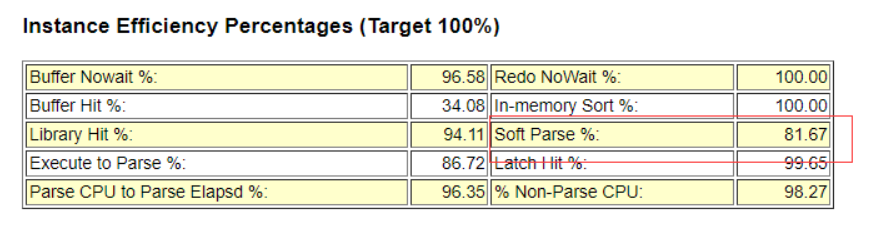
2.3 Efficiency percentages
efficiency percentages是一些命中率指标。Buffer Hint、Library Hint等表示SGA(System global area)的命中率;Soft Parse指标表示共享池的软解析率,如果小于90%,就说明存在未绑定变量的情况。
2.4 首要等待时间
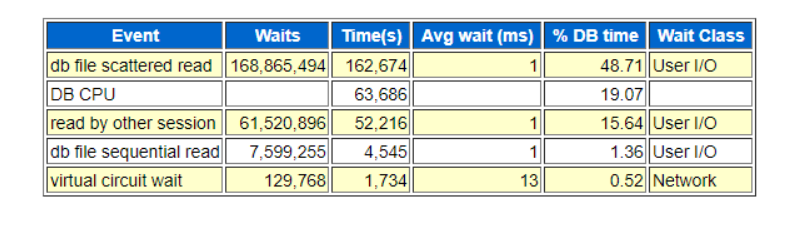
上图为首要等待事件,总体来说,数据库等待时间较长。
文件读取时间太长。通过上面的计算可知当前的数据库非空闲等待较为严重。
2.5时间统计模型
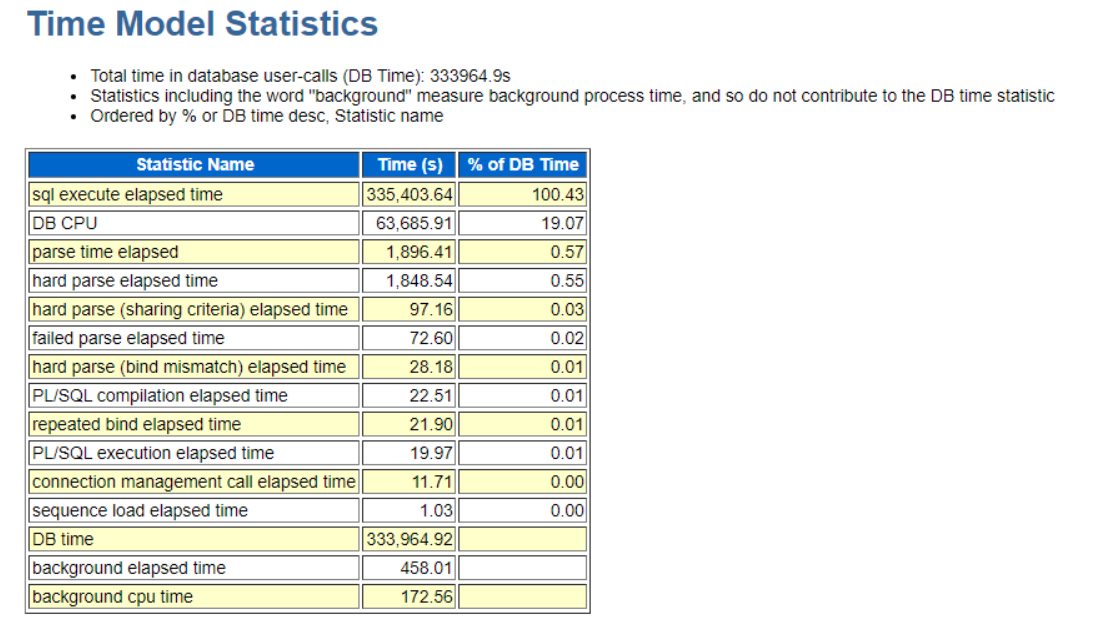
上图为时间统计模型。
sql execute elpased time时间占主导,即时间耗用主要是在SQL执行上面。
这些SQL的执行对应得等待事件见前面的Top Event,也就是说等待和争用比较突出。
注意该时间模型中的指标存在包含关系所以存在Time Model Statistics加起来超过100%情形。
2.6 SQL Statistics
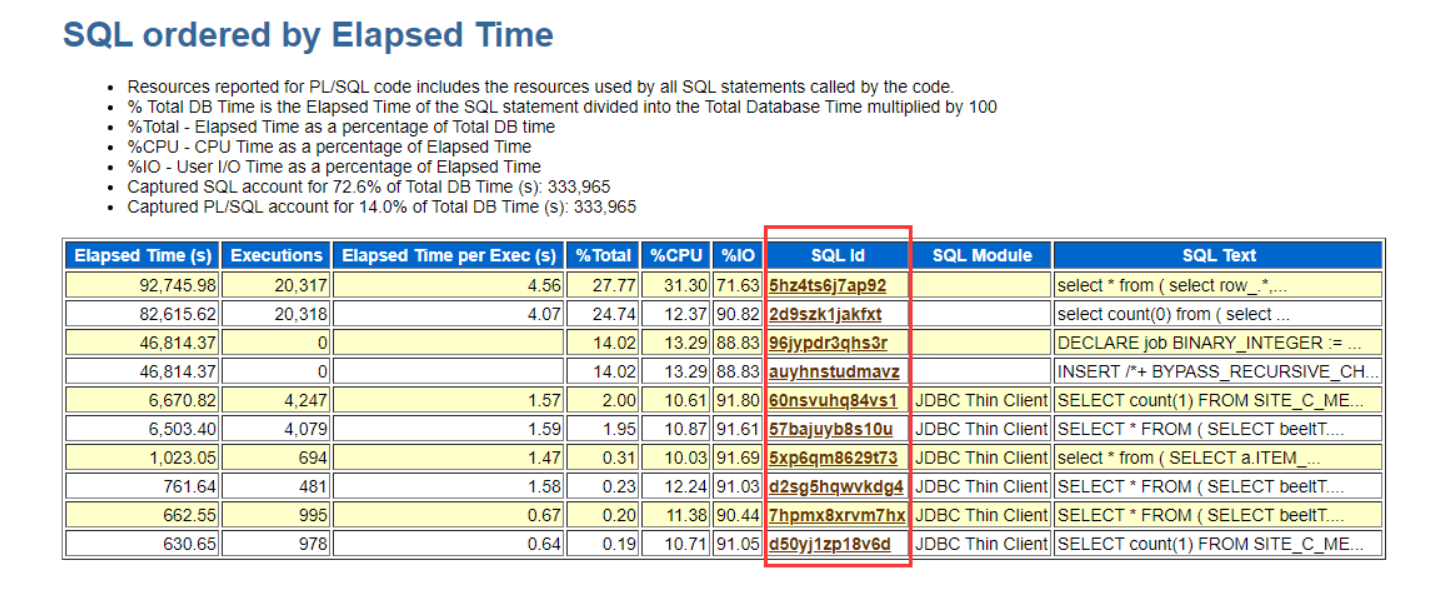
SQL Statistics从几个维度列举了系统执行比较慢的SQL,点击SQL id 可以具体看到SQL的内容,然后拿SQL去调优,调优SQL可以用执行计划看看。更方便我们进行判断。如上图,一个不常用的语句执行这么多次,我们可以进一步去判断是否哪里出现问题,是否有定时任务,或者是被爬虫了。等等。