Python基础知识回顾
简介
其实在学习面向对象之前,Python的基础知识就已经学完了。由于当时一心想早点学完,就没有回来写这个基础知识的总结,一直到网络编程部分开始要做一个项目时,发现自己的基础并不牢靠,故在此重新学习总结Python基础知识,也希望大家可以温故而知新。这里说明一下:本篇不会回顾Python历史、环境安装等知识,且篇幅较长,请从目录跳转至所需章节。
基础
变量和常量
什么是变量?
官方解释翻译过来就是:
变量用于存储要在计算机程序中引用和操作的信息。它们还提供了一种用描述性名称标记数据的方法,以便读者和我们自己能够更清楚地理解我们的程序。将变量看作包含信息的容器是有帮助的。它们的唯一目的是在内存中标记和存储数据。然后可以在整个程序中使用这些数据。
可以总结出两点:
- 用于存储数据
- 用于标记数据
变量名的定义规则
如何定义一个变量名?
- 变量名只能是字母、数字、下划线的任意组合
- 变量名不能以数字开头
- 以下关键字不能声明为变量名:
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
在Python中,如果一个变量名由两个或两个以上的单词组成(每个单词都用小写),我们一般在单词中间加入下划线,如:first_number。
注意:Python中变量名是区分大小写的,如First_name与first_name就是两个不同的变量。
当然还有其他的规则,如 驼峰命名法,这里就不再详细介绍。
常量
常量,也就是不变的量,比如重力加速度。
在Python中,并没有专门定义常量的方式,一般使用全大写的变量名表示。
NAME = 'Kris',其实本质上还是变量。
数据类型
Python中有几种常用的数据类型:int、string、bool、float、dict、list、tuple、set。
数字int
int又常被称为整型,根据机器类型不同,取值范围不同:
- 在32位机器上,整数的位数为32位,取值范围为-231~231-1
- 在64位机器上,整数的位数为64位,取值范围为-263~263-1
数字主要用于计算,使用方法并不是很多,记住一种即可:
#bit_length(),当十进制用二进制表示时,最少使用的位数
num = 11
data = num.bit_length()
print(data)
注意:在Python 3中不再有long(长整型)类型,全都是int。
布尔值bool
布尔值就两种,真True,假False。主要用于逻辑判断。例如:
a = 3
b = 5
print(a > b) #False
print(a < b) #True
True,False可以转换成数字:
#bool值转换成int类型
num1 = int(True) # 1
num2 = int(False) # 0
print(num1,num2)
当然int也可转换成bool:
# int转换成bool类型(所有非零的int转换成bool都为True):
res1 = bool(0) # False
res2 = bool(1) # True
res3 = bool(2) #True
print(res1,res2,res3)
字符串str
在Python中,加了引号的字符都被认为是字符串。
name = "Alex" #双引号
age = '22' #单引号
msg = ''' My name is Alex.''' #三引号
print(type(name),type(age),type(msg)) #type()可用来查看括号里的数据类型
单双引号没有任何区别,且都需成对使用,不能前面单引号,后面双引号。
多引号用于多行字符串
msg = '''
今天我想写首小诗,
歌颂我的同桌,
你看他那乌黑的短发,
好像一只炸毛鸡。
'''
print(msg)
字符串拼接
字符串可以进行“相加”和“相乘”运算
>>> name
'Alex Li'
>>> age
'22'
>>>
>>> name + age #相加其实就是简单拼接
'Alex Li22'
>>>
>>> name * 10 #相乘其实就是复制自己多少次,再拼接在一起
'Alex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex Li'
注意,字符串的拼接只能是双方都是字符串,不能跟数字或其它类型拼接
格式化输出
一个字符串中,如果有些信息经常变化,或者是需要用户自己输入的,可以先在该位置上放一个占位符,再把字符串里的占位符与外部的变量做一个映射关系即可。
name = input("Name:")
age = input("Age:")
job = input("Job:")
hobbie = input("Hobbie:")
info = '''
------------ info of %s ----------- #这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name
Name : %s #代表 name
Age : %s #代表 age
job : %s #代表 job
Hobbie: %s #代表 hobbie
------------- end -----------------
''' %(name,name,age,job,hobbie) # 这行的 % 号就是 把前面的字符串 与拓号 后面的 变量 关联起来
print(info)
%s就是代表字符串占位符,除此之外,还有%d,是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字。
字符串的索引与切片
索引即下标,就是字符串组成元素的从第一个开始,初始索引为0,以此类推
a = 'ABCDEFGHIJK'
print(a[0])
print(a[3])
print(a[5])
print(a[7])
切片就是通过索引截取字符串的一段,形成新的字符串,格式为 [索引:索引:步长],原则是顾头不顾尾。
a = 'ABCDEFGHIJK'
print(a[0:3])
print(a[2:5])
print(a[0:]) #默认到最后
print(a[0:-1]) # -1 是列表中最后一个元素的索引,但是要满足顾头不顾尾的原则,所以取不到K元素
print(a[0:5:2]) #加步长
print(a[5:0:-2]) #反向加步长
字符串的常用方法
name = 'alex kkk'
# captalize() 首字母大写
print(name.captalize())
# swapcase() 大小写翻转
print(name.swapcase())
# title() 每个单词的首字母大写
print(name.title())
# center(length,填充字符) 创建一个总长度为length的字符串,将引用该方法的字符串居中,空白处用 填充字符 填充。
name = 'alex'
res1= name.center(40,'*')
print(res1)
msg = 'absdshjahsdkhfkasjhdkjghaksdjlgkha'
# count() 计算字符串中的元素出现的个数
res2 = msg.count('a',0,5) # 可切片
print(res2)
# startwith() 判断是否以...开头
#endwith() 判断是否以...结尾
res3 = msg.startwith('b',0,5) # 可切片,返回bool值
res4 = msg.endwith('c',3,7) # 可切片,,返回bool值
print(res3,res4)
# find() 查找字符串中元素是否存在
res4 = msg.find('bcd',1,7)
print(res4) # 返回的找到的元素的索引,如果找不到返回-1
# index()
res5 = msg.index('bcd',1,7)
print(res5) # 返回的找到的元素的索引,找不到报错
# split() 以...分割,最终返回一个列表,且列表中不含有分割的元素
res6 = msg.split('a')
print(res6)
res7 = msg.rsplit('a')
print(res7) # 从右往左分
# format() 格式化输出
res8='{} {} {}'.format('egon',18,'male')
res9='{1} {0} {1}'.format('egon',18,'male')
res10='{name} {age} {sex}'.format(sex='male',name='egon',age=18)
print(res8,res9,res10)
# strip() 用于移除字符串首尾指定的字符串(默认为空格或换行符)
name='*barry**'
print(name.strip('*')) # 删除首尾的*
print(name.lstrip('*')) #删除左边的*
print(name.rstrip('*')) #删除右边的*
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
# replace() 替换字符串
name='alex say :i have one tesla,my name is alex'
print(name.replace('alex','SB',1)) # 'alex'原字符串,'SB'新字符串,1替换的次数
# is系列
name='kris123'
print(name.isalnum()) #字符串由字母或数字组成
print(name.isalpha()) #字符串只由字母组成
print(name.isdigit()) #字符串只由数字组成
列表list
列表是python中的基础数据类型之一,是以[]括起来,每个元素以逗号隔开,而且他里面可以存放各种数据类型比如:
li = [‘alex’,123,Ture,(1,2,3,’wusir’),[1,2,3,’小明’,],{‘name’:’alex’}]
列表相比于字符串,不仅可以储存不同的数据类型,而且可以储存大量数据,32位python的限制是 536870912 个元素,64位python的限制是 1152921504606846975 个元素。而且列表是有序的,有索引值,可切片,方便取值。
列表的增
li = [1,'a','b','c',2,3,'a']
# insert() 在指定位置插入新元素
li.insert(0,'d') # 0:索引,'d':插入的新元素
print(li)
# append() 在列表末尾加入
li.append('edg')
li.append([1,2,3,4])
print(li)
# extend() 在列表末尾一次性追加另一个序列中的多个值
li2 = ['c','d','e']
li = li.extend(li2)
print(li)
列表的删
li = [1,2,3,4,5,6,7,8,9,0,'a','b','c']
# pop() 根据索引删除,并返回该元素的值
li.pop() # 不指定默认删除最后一个
print(li)
# remove() 根据元素删除,无返回值
li.remove('a')
print(li)
#del 可按照位置删除,也可切片删除,无返回值,也可直接删除整个列表
del li[3]
print(li)
del li[1:3]
print(li)
del li
#clear() 清空列表
li = li.clear()
print(li)
列表的改
li = [1,'a',2,'b',3,'c']
li[1] = 99
print(li)
li[1:3] = ['a','b']
print(li)
li[1:3]
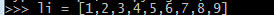
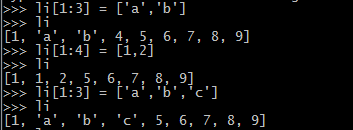
列表的查
li = [1,2,3,4,'a','b','c','d']
# 通过索引(注意:第一个元素的索引为0)
print(li[0])
print(li[1])
print(li[2])
# 切片查
print(li[1:4])
# 循环
for i in li:
print(i)
列表的其他方法
li = [1,2,3,4,5,6,234,12,34,12,341,23,41,234,12,4,34,1,234]
# count() 统计元素在列表中出现的次数
print(li.count(1))
# index() 列表从左往右找出第一个匹配项的索引
print(li.index(34))
# sort() 在原位置对列表进行正向排序(注意:不生成新的列表)
print(li.sort())
# reverse() 反向排序
print(li.reverse())
注意:排序规则是按照首个字符在ASCII码表中对应的顺序
元组tuple
元组又称 只读列表,即数据可被查询,但不能被修改,可做切片操作。
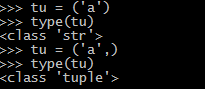
tu = (1,2,3,4) # 元组是用小括号()
同样元组中的元素也可为列表、字典等。
注意:如果定义一个只有一个元素的元组,需加逗号
tu = ('a',)
否则,tu的类型就是第一个元素的类型
字典dict
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
字典(dictionary)是除列表意外python之中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典的增
dic['li'] = [1,2,3] # 字典名称[key] = value
print(dic)
#setdefault(key,value) 在字典中添加键值对,如果只有key那对应的值为None,如果原字典中有添加的key,则若value相同就不会更改,不同就覆盖
dic.setdefault('k','v')
print(dic) # {'k': 'v'}
dic.setdefault('k','v1') # {'k': 'v1'}
print(dic)
字典的删
dic = {'a':1,'b':2,'c':3}
# pop() 删除字典中指定key的键值对,返回对应的value
dic.pop('a')
print(dic)
# del 删除字典中指定key的键值对,无返回值,也可删除整个字典
del dic['b']
print(dic)
#clear() 清空
dic = dic.clear()
print(dic)
字典的改
dic = {'a':1,'b':2,'c':3}
# 利用已有的key,覆盖原来的value
dic['a'] = 99
print(dic)
# update() dic1.update(dic2)把dic2里的键值对更新到dic1
dic2 = {'a':23,'d':4}
dic.update(dic2)
print(dic)
注意:更新时,如果dic1中存在dic2的某个key,则dic2中该key对应的value将覆盖dic1中该key对应的value;不存在则新增。
字典的查
dic = {'a':1,'b':2,'c':3}
# 根据key查找value
value1 = dic['a'] # 没有会报错
print(value1)
# get() dict.get(key, default=None)返回指定键的值,如果值不在字典中返回默认值
value2 = dic['a']
字典的其他操作
dic = {"name":"jin","age":18,"sex":"male"}
# items() 以列表返回可遍历的(键, 值) 元组数组
item = dic.items()
print(item,type(item)) # dict_items([('name', 'jin'), ('sex', 'male'), ('age', 18)]) <class 'dict_items'>
# 这个类型就是dict_items类型,可迭代的
# keys() 以列表返回一个字典所有的键
keys = dic.keys()
print(keys,type(keys)) # dict_keys(['sex', 'age', 'name']) <class 'dict_keys'>
# values() 以列表返回字典中的所有值
values = dic.values()
print(values) # dict_values(['male', 18, 'jin']) <class 'dict_values'>
# 字典的循环
for key in dic:
print(key)
for item in dic.items():
print(item)
for key,value in dic.items():
print(key,value)
集合set
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变),但是集合本身是不可哈希的(可变的)。
下面是集合比较重要的两点:
- 去重:若将列表转为集合,即可实现自动去重
- 关系测试:测试两组数据之间的交集、差集、并集等关系
创建集合
set1 = set({1,2,'barry'})
set2 = {1,2,'barry'}
print(set1,set2) # {1, 2, 'barry'} {1, 2, 'barry'}
集合的增
set1 = set({1,2,'barry'})
# add() 一次只能增加一个
set1.add('flash')
print(set1)
# update() 迭代增加
set1.update('hulk')
print(set1)
set1.update([1,2,3,4,5,6,7])
print(set1)
集合的删
set1 = set({1,2,'barry'})
# remove() 删除指定元素
set1.remove('barry')
print(set1)
# pop() 随机删除一个元素
set1.pop()
print(set1)
# clear() 清空集合
set1.clear()
print(set1)
# del 删除集合
del set1
集合的关系运算
交集(& 或者 intersection)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2) # {4, 5}
print(set1.intersection(set2)) # {4, 5}
并集(| 或者 union)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7,8}
print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7,8}
差集(- 或者 difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2) # {1, 2, 3}
print(set1.difference(set2)) # {1, 2, 3}
反交集(^ 或者 symmetric_difference)
# 可以理解为(set1、set2的并集)与(set1、set2的交集)的差集
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8}
子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是判断set1是否为set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是判断set2是否为set1超集。
不可变集合frozenset
# 让集合变为不可变类型,可以作为字典的key,也可以作为其它集合的元素
s = frozenset('barry')
print(s,type(s)) # frozenset({'a', 'y', 'b', 'r'}) <class 'frozenset'>
数据运算
基本运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,暂只介绍算数运算、比较运算、逻辑运算、赋值运算、成员运算
算术运算
以下假设变量:a=10,b=20

比较运算
以下假设变量:a=10,b=20

逻辑运算

逻辑运算进阶
1.优先级关系:()>not>and>or,有括号先算括号里的,同一优先级从左往右计算
2. x or y , x为真,值就是x,x为假,值是y; x and y, x为真,值是y,x为假,值是x。

Tips:这里记住一种情况即可,另一种情况与之相反。
成员运算

判断子元素是否在原字符串(字典,列表,集合)中:
print('喜欢' in 'dkfljadklf喜欢hfjdkas') # True
print('a' in 'bcvd') # False
print('y' not in 'ofkjdslaf') # True
Python运算符优先级

流程控制
if语句
# 单分支
if 条件:
满足条件后要执行的代码
# 双分支
if 条件:
满足条件执行代码
else:
if条件不满足就走这段
# 多分支
if 条件:
满足条件执行代码
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
else:
上面所有的条件不满足就走这段
while语句
# 基本循环
while 条件:
# 循环体
# 如果条件为真,那么循环体则执行
# 如果条件为假,那么循环体不执行
# 循环中止语句
continue # 跳过本次循环,开始下次循环
break #结束循环,执行循环体外的代码(如果有的话)
# while...else...
# while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句
for循环、enumerate、range
for循环
用户按照顺序循环可迭代对象的内容
# for循环举例:
msg = '从前有座山山里有座庙庙里有个老和尚'
for item in msg:
print(item)
li = ['alex','银角','女神','egon','太白']
for i in li:
print(i)
dic = {'name':'太白','age':18,'sex':'man'}
for k,v in dic.items():
print(k,v)
enumerate
枚举:对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。
#enmuerate举例
li = ['alex','银角','女神','egon','太白']
for i in enumerate(li):
print(i)
for index,name in enumerate(li,1):
print(index,name)
for index, name in enumerate(li, 100): # 起始位置默认是0,可更改
print(index, name)
结果:
range
指定范围,生成指定数字( 同样适用顾头不顾尾原则)
for i in range(1,10): # 生成的数字为1-9
print(i)
for i in range(1,10,2): # 步长
print(i)
for i in range(10,1,-2): # 反向步长
print(i)
字符编码和转码
# ASCII:由英文字母、数字、特殊字符组成,每个字母、数字、特殊字符占8位,即一个字节,表示一个字符;
# Unicode:万国码,一个字符占32位,4个字节;
# UTF-8:ascii码占一个字节,欧洲语言占两个字节,东亚语言占三个字节;
# GBK:中文占两个字节,英文占1个字节
转码方式:

文件操作
文件操作基本流程
# 1.打开文件,得到文件句柄并赋值给一个变量
f = open ('a.txt','r',encoding = 'utf-8') # 默认打开方式为r
# 2.通过句柄对文件进行操作
data = f.read()
# 3.关闭文件
f.close()
关闭文件的注意事项
打开一个文件包含两部分资源:操作系统打开文件+应用程序的变量。在操作完一个文件后,必须把与该文件的这两部分资源一个不落的回收。回收的方法为:
1、f.close() # 回收操作系统打开的文件
2、del f # 回收应用程序的变量
其中del f 一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源。
而Python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们在操作完文件之后,一定要f.close()
如果不想这么麻烦,也可以使用with来帮助我们:
with open ('a.txt','r',encoding = 'utf-8') as f:
pass
这里就不用调用f.close()来关闭文件。
当然也可以同时打开多个文件:
with open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data=read_f.read()
write_f.write(data)
文件编码
如果不指定编码方式,操作系统就会用自己的默认编码去打开文件,在windows下是GBK,Linux下是utf-8。如果要保证不乱码,则文件以什么方式保存的,就要以什么方式打开。
文件打开的模式
with open('文件路径','打开方式') as f
# 1.打开文件的模式有(默认为文本模式):
r 只读模式【默认模式,文件必须存在,否则抛出异常】
w 只写模式【不可读,文件不存在则新建,存在则清空内容】
a 只追加写模式【不可读,文件不存在则新建,存在则只追加内容】
# 2.对于非文本文件,只能用b模式,‘b’表示以字节的方式操作(而所有的文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jpg格式、视频文件的avi格式)
rb
wb
ab
注意:以b方式打开时,读取到的内容是字节类型;写入时也只能写入字节类型,不能指定编码。
# 3.'+'模式(就是增加了一个功能)
r+ 读写【可读,可写,若文件不存在,报错】
w+ 写读【可写,可读,若文件不存在,创建】
a+ 写读【可写,可读】
# 4.以bytes类型操作的读写,写读,写读模式
r+ 读写【可读,可写,若文件不存在,报错】
w+ 写读【可写,可读,若文件不存在,创建】
a+ 写读【可写,可读】
文件操作方法
# 这里只介绍几个常用的文件操作方法
# flush() 刷新缓冲区,即把缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入
# read(size) 从文件读取指定的字节数,如果未给定size或为负则读取所有
# readline(size) 从文件读取整行,包括 "\n" 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 "\n" 字符
# readlines() 读取所有行(直到结束符 EOF)并返回列表,该列表可以由for循环进行处理。如果碰到结束符 EOF 则返回空字符串
# next() 在文件使用迭代器时会使用到,在循环中,next()方法会在每次循环中调用,该方法返回文件的下一行,如果到达结尾(EOF),则触发 StopIteration
# write() 用于向文件中写入指定字符串。在文件关闭前或缓冲区刷新前,字符串内容存储在缓冲区中,这时你在文件中是看不到写入的内容的。如果文件打开模式带 b,那写入文件内容时,str (参数)要用 encode 方法转为 bytes 形式,否则报错:TypeError: a bytes-like object is required, not 'str'
# writelines() 用于向文件中写入一序列的字符串。这一序列字符串可以是由迭代对象产生的,如一个字符串列表。换行需要制定换行符 \n
# 下面三个是关于光标操作的
# seek(offset[, whence]) 移动文件读取指针到指定位置,
# offset:开始的偏移量,也就是代表需要移动偏移的字节数
# whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算
起,2代表从文件末尾算起。
# tell() 返回文件的当前位置,即文件指针当前位置
# truncate([size ]) 用于截断文件,如果指定了可选参数 size,则表示截断文件为 size 个字符。 如果没有指定 size,则从当前位置起截断;截断之后 size 后面的所有字符被删除
读取文件最好的还是用for循环。
修改文件
只能读取源文件内容,修改内容,写入新文件并替换旧文件
import os
with open('a.txt',encoding = 'utf-8') as f,open('a2.txt','w',encoding = 'utf-8') as f2:
for line in f:
代码块
# 写文件
f2.write(line)
# 重命名文件
os.remove('a.txt')
os.rename('a2.txt','a.txt')
代码块、小数据池、深浅copy
代码块
在总结代码块之前,先介绍一下id、is、==:
# id() id是内存地址,可用于查询一个数据的内存地址
name = 'Kris'
print(id(name))
# is 比较两边的内存地址是否相等
# == 比较两边的值是否相等
如果内存地址相等,那么这两边其实是指向的同一个内存地址。
内存地址相等,那么值一定相等。但如果值相等,内存地址不一定相同。
Python程序是由代码块构造的。块是一个python程序的文本,他是作为一个单元执行的。代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。而作为交互方式输入的每个命令都是一个代码块(也就是从cmd进入Python解释器里,输入的每一行代码都是一个代码块)。
代码块的缓存机制
Python在执行同一个代码块的初始化对象的命令时,会检查它的值是否存在,如果存在,就将其重用。换句话说,在一个代码块中,在初始化完i1=1后,初始化i2=1时,它就会先检查1这个值是否已经存在,如果存在了就重用这个值,这也就意味着i1、i2指向同一个对象,即:id相同。
代码块的缓存机制的适用范围:int(float)、str、bool 。
int(float):任何数字在同一代码块下都会复用。bool:True和False会以1,0方式存在,并且复用。str:几乎所有的字符串都会符合缓存机制。
小数据池
小数据池,又称为小整数缓存机制。同样,小数据池也只是针对int(float)、str、bool。但是,小数据池是针对不同代码块之前的缓存机制。
这里我们主要讲int类型的。Python自动将 -5~256 的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。也就是说,如果多个变量都是指向同一个(在这个范围内的)数字,他们在内存中指向的都是一个内存地址。
而这个存放-5~256的整数,和一定规则的字符串的容器,就成为小数据池。
无论是代码块的缓存机制,还是小数据池,都是为了能够提高一些字符串,整数处理任务在时间和空间上的性能;需要值相同的字符串,整数的时候,直接从‘池’中取出复用,避免频繁的创建和销毁,提升效率,节约内存。
list的深浅Copy
# 对于赋值运算来说,赋值符号两边的内存地址是一样的,所以它们是完全一样的。
# 对于浅copy来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与原列表中的元素是公用的。
# 对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的不可变的数据类型是公用的。
详情可见:列表的深浅Copy详解
函数
初识函数
函数的优点
可读性强,复用性强
函数的定义与调用
# 函数的定义
def 函数名():
函数体
return 返回值
# 函数的调用
函数名()
所有的函数,只定义不调用就一定不执行,且只能先定义后调用。
函数的返回值
返回值有几种情况:
- 没有返回值:返回
None
- 不写return
- 只写return:结束一个函数的继续
-return None(不常用) - 有一个返回值
- 可以返回任何数据类型
- 只要返回就可以接收到
- 如果一个程序中有多个return,只执行第一个 - 多个返回值
- 用多个变量接收:有多少返回值就用多少变量接收
- 用一个变量接收: 得到一个元组
函数的参数
函数的参数分为:形参和实参。
- 形参(定义参数的时候):
- 位置参数:一旦定义必须传值
*args:动态参数,可以接收任意多个位置参数- 默认参数:可以不传
**kwargs:动态参数,可以接收多个关键字参数
- 实参(调用函数的时候):
- 按照位置传参
- 按照关键字传参
- 可以混用,但是位置参数必须在关键字传参之前
- 不能对一个参数重复赋值
默认参数的陷阱
如果默认参数的只是一个可变数据类型,那么每一次调用函数的时候,如果不传值就公用这个数据类型的资源。
函数进阶
函数的命名空间
命名空间有三种:
- 内置命名空间(python解释器)
- python解释器一起动就可以使用的函数名,存储在内置命名空间
- 内置的名字在启动解释器的时候就被加载进内存里 - 全局命名空间(我们写的函数外的代码)
- 是在程序从上至下被执行的过程中依次加载进内存里的
- 放置了我们设置的所有变量名和函数名 - 局部命名空间(函数中)
- 函数内部定义的名字
- 当调用函数的时候才会产生这个名称空间,随着函数执行的结束这个名称空间也随之消失
注意:
1.在局部命名空间中,可以使用全局、内置命名空间中的名字;
2.在全局命名空间中,可以使用内置命名空间中的代码,但是不能使用局部命名空间中的代码;
3.当我们在本层命名空间中定义了与上一层命名空间中相同的名字,就会使用本层的名字;
4.如果调用本层命名空间中没有的,就会去最近的上一层找,上一层没有再到上一层找。
函数的调用
定义了函数之后,直接调用函数名,返回的是函数的内存地址,由此,函数的调用分为两种:
- 函数名()
- 函数的内存地址()
函数的作用域
作用域有两种:
- 全局作用域:作用于全局,内置和全局名字空间中的名字都属于全局作用域中,可用
globals()查看 - 局部作用域:作用于局部,函数(即局部名字空间中)的名字属于局部作用域,可用
locals()查看
对于不可变数据类型,在局部是可以查看全局作用域中的变量,但不能直接修改,如果想要修改,需要在程序的一开始添加global声明。如果在一个局部内声明了一个global变量,那么这个变量在局部内的所有操作将对全局的变量有效。
而如果只想调用上层中离当前函数最近一层的局部变量,可用nonloca声明。nonloca只能作用于局部变量。声明了nonloca的内部函数的变量的修改会影响到 离当前函数最近一层的局部变量。对全局无效。 对局部也只是最近一层有效。
闭包
函数内部定义的函数称为内部函数。
内部函数包含对外部作用域而非全剧作用域名字的引用,该内部函数称为闭包函数。
def func():
name = 'Kris'
def inner():
print(name)
return inner
f = func()
f()
装饰器
- 开发原则:开放封闭原则
- 装饰器的作用:在不改变原函数的调用方式的情况下,在函数的前后添加功能
- 本质:闭包函数
# 装饰器
def outer(func):
def inner(*args,**kwargs):
print('在被装饰的函数执行前做的事')
ret = func(*args,**kwargs)
print('在被装饰的函数执行前做的事')
return ret
return inner
# 装饰器的调用
@outer
def function(msg):
print(msg)
return 1
迭代器和生成器
迭代器
- 可迭代协议:含有
__iter__方法都是可迭代的 - 迭代器协议: 含有
next和__iter__的都是迭代器 - 特点:
- 节省内存空间
- 方便逐个取值,且所有数据只能取一次
生成器
本质上就是迭代器。
生成器函数
- 含有
yield关键字的函数都是生成器函数 - 特点:
- 调用之后函数内的代码不会执行,而是返回生成器
- 每次从生成器中去一个值就会执行一段代码,执行至yield停止
- 取值:
-for:若没有break会一直取直到取完
-next:每次只能取一个
-send:基本效果同next,但第一次使用生成器的时候 是用next获取下一个值,在获取下一个值的时候,给上一个yield的位置传递一个数据,且最后一个yield不能接受外部的值。
- 数据类型强制转换:会一次性把所有的数据读到内存里
生成器表达式
1.把列表解析的[]换成()得到的就是生成器表达式
(条件成立想放在生成器中的值 for i in 可迭代的 if 条件)
2.更节省内存
例如:sum(x ** 2 for x in range(4))效果同sum([x ** 2 for x in range(4)])
内置函数、匿名函数
内置函数
Python内置函数一共68个,这里只介绍部分的。
# reversed(seq)
保留原列表,返回一个反向的迭代器
# bytes([source[, encoding[, errors]]])
返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列
# zip([iterable, ...])
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存
l1 = [1,2,3]
l2 = ['a','b','c']
for i in zip(l1,l2):
print(i)
>>>(1,'a')
>>>(2,'b')
>>>(3,'c')
# filter(function, iterable)
用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象
只管筛选,不会改变原来的值,且执行了filter后的结果数据个数<=执行前的个数
# map(function, iterable, ...)
会根据提供的函数对指定序列做映射。第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表,返回的是迭代器
执行前后,元素的个数不变,只可能会发生改变
匿名函数
函数名 = lambda 参数 :返回值
# 参数可以有多个,用逗号隔开
# 匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值
# 返回值和正常函数一样可以是任意数据类型
递归函数
在一个函数里再调用这个函数本身,这个函数就称为递归函数。
名称空间占用太多内存的问题,于是python为了杜绝此类现象,强制的将递归层数控制在了997。
模块
常用模块
常用模块主要有re模块、collections模块、时间模块、random模块、os模块、sys模块、序列化模块。
re模块
正则
# 1.元字符
# \w \d \s 依次是 匹配字母或数字或下划线、匹配数字、匹配任意的空白符
# \W \D \S 依次是匹配非字母或数字或下划线、匹配非数字、匹配非空白符
# . 匹配除换行符以外的任意字符
# \n \t 依次是 匹配一个换行符、匹配一个制表符
# \b 匹配一个单词的结尾
# ^ $ 依次是 匹配字符串的开始、匹配字符串的结尾
# () 匹配括号内的表达式,也表示一个组
# a|b 匹配字符a或字符b
# [...] 匹配字符组中字符的所有字符
# [^...] 匹配除了字符组中字符的所有字符
# 2.量词
# * 重复零次或更多次
# + 重复一次或更多次
# ? 重复零次或一次
# {n} 重复n次
# {n,} 重复n次或更多次
# {n,m} 重复n到m次
# 3.贪婪匹配
在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
# 4.惰性匹配
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串
# *? 重复任意次,但尽可能少重复
# +? 重复1次或更多次,但尽可能少重复
# ?? 重复0次或1次,但尽可能少重复
# {n,m}? 重复n到m次,但尽可能少重复
# {n,}? 重复n次以上,但尽可能少重复
# 5..*?的用法
. 是任意字符
* 是取 0 至 无限长度
? 是非贪婪模式。
和在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在:
.*?x
就是取前面任意长度的字符,直到第一个x出现
re模块下的常用方法
import re
ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : ['a', 'a']
注意:
ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['www.oldboy.com']
ret = re.search('a', 'eva egon yuan').group()
print(ret) #结果 : 'a'
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配
print(ret)
#结果 : 'a'
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
注意:
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个
print(ret) #evaHegon4yuan4
ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret)
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
import re
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
collections模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
时间模块
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
(1)时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
(2)格式化的时间字符串(Format String): ‘1999-12-06’
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
(3)元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
#导入时间模块
>>>import time
#时间戳
>>>time.time()
1500875844.800804
#时间字符串
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 13:54:37'
>>>time.strftime("%Y-%m-%d %H-%M-%S")
'2017-07-24 13-55-04'
#时间元组:localtime将一个时间戳转换为当前时区的struct_time
time.localtime()
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24,
tm_hour=13, tm_min=59, tm_sec=37,
tm_wday=0, tm_yday=205, tm_isdst=0)

random模块
>>> import random
#随机小数
>>> random.random() # 大于0且小于1之间的小数
0.7664338663654585
>>> random.uniform(1,3) #大于1小于3的小数
1.6270147180533838
#恒富:发红包
#随机整数
>>> random.randint(1,5) # 大于等于1且小于等于5之间的整数
>>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数
#随机选择一个返回
>>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5]
#随机选择多个返回,返回的个数为函数的第二个参数
>>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合
[[4, 5], '23']
#打乱列表顺序
>>> item=[1,3,5,7,9]
>>> random.shuffle(item) # 打乱次序
>>> item
[5, 1, 3, 7, 9]
>>> random.shuffle(item)
>>> item
[5, 9, 7, 1, 3]
os模块
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.path
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version 获取Python解释程序的版本信息
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
异常处理
import sys
try:
sys.exit(1)
except SystemExit as e:
print(e)
序列化模块
将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
序列化的目的:
- 1、以某种存储形式使自定义对象持久化;
- 2、将对象从一个地方传递到另一个地方。
- 3、使程序更具维护性。

用于序列化的两个模块:
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
json
# loads 和 dumps
import json
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_dic),str_dic) #<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"}
#注意,json转换完的字符串类型的字典中的字符串是由""表示的
dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典
#注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(type(dic2),dic2) #<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic) #<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2) #<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
# load 和 dump
import json
f = open('json_file','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close()
f = open('json_file')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
pickle
import pickle
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = pickle.dumps(dic)
print(str_dic) #一串二进制内容
dic2 = pickle.loads(str_dic)
print(dic2) #字典
import time
struct_time = time.localtime(1000000000)
print(struct_time)
f = open('pickle_file','wb')
pickle.dump(struct_time,f)
f.close()
f = open('pickle_file','rb')
struct_time2 = pickle.load(f)
print(struct_time2.tm_year)
模块和包
模块的导入
模块的导入方式:
importfrom 模块名 import 方法as重命名- 支持多名字的导入
sys.modules记录了所有被导入的模块sys.path记录了导入模块的时候寻找的所有路径
把模块当做脚本执行
可以通过模块的全局变量__name__来查看模块名:
当做脚本运行:
__name__ 等于'__main__'
当做模块导入:
__name__= 模块名
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
模块搜索路径
模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
包
把解决一类问题的模块放在同一个文件夹里,这个文件夹就叫包。
注意:
1.凡是在导入时带点的,点的左边都必须是一个包
import glance.db.models
glance.db.models.register_models('mysql')
2.需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
from glance.db import models
models.register_models('mysql')
from glance.db.models import register_models
register_models('mysql')
