3年前开发移动端卷积神经网络SDK,使用GPU实现卷积神经网络的各种算子,Android/iOS双端都实现了,性能非常不错,实时风格画和实时抠图接近50FPS,今天无意中翻到当初的笔记才发现好久没碰AI了,于是汇总下当做回忆,也希望能对大家有所帮助。
卷积神经网络
下面这个是LeNet, 最早的卷积神经网络之一

卷积神经网络其实和传统神经网络是一脉相承的,只不过多了很多元素,比如激励层(非线性), 卷积层(提炼特征)等等. 卷积网络计算过程的动画如下
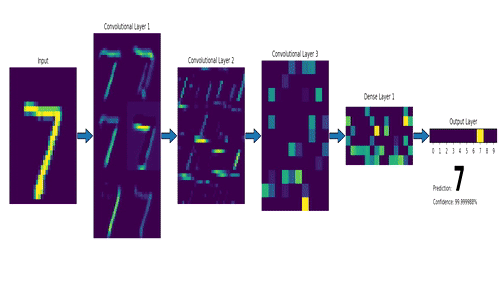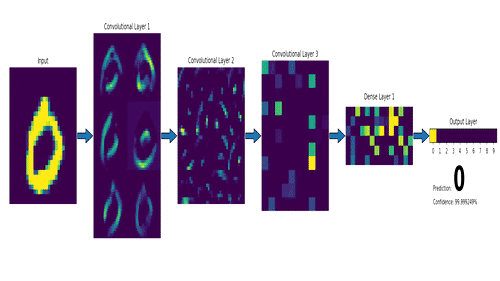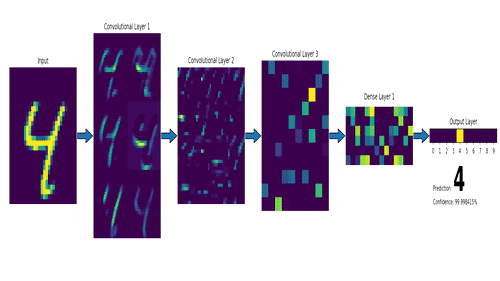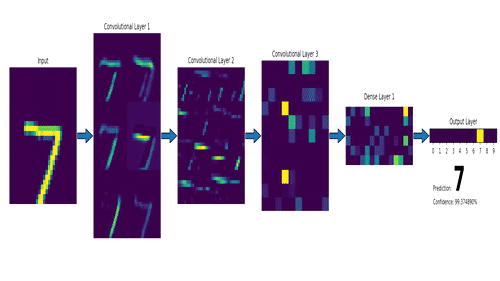
卷积
原理
卷积有两个部分,一个图像一个是卷积核,卷积核对图像做平移卷积计算输出新的图像的过程就是卷积,我们来看下一个卷积过程的动画。
其实图像的卷积和信号系统中的卷积有类似性。我们知道信号系统中,卷积的定义如下

卷积的过程就是把其中一个函数翻转后平移做乘法计算各个点的卷积值。那么在图像上卷积核就是g(x, y), 图像是f(x, y), 理论上就需要对卷积核g(x,y)进行上下左右翻转,但是我们在实际操作的时候为啥没有做翻转的动作呢?这是因为我们在training卷积神经网络时,初始卷积核是一个随机值/0值,卷积核的值是整个系统training的过程的产生的。既然初始值是随机的,是否翻转没有意义,最后整个系统损失函数值最小时得到的卷积核本质上就是翻转后的值的。从效果上说,卷积核可以看成是图像滤波器。
卷积过程动画
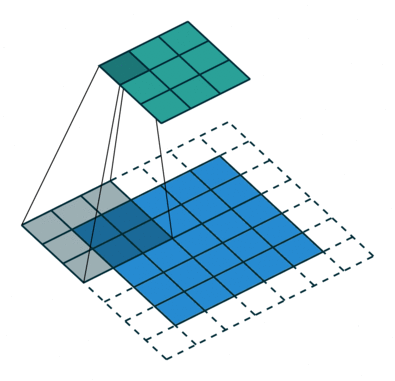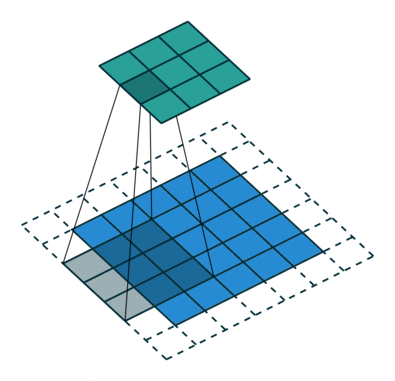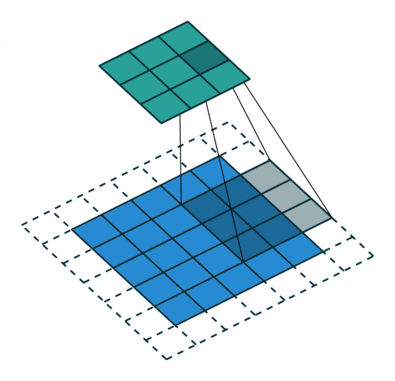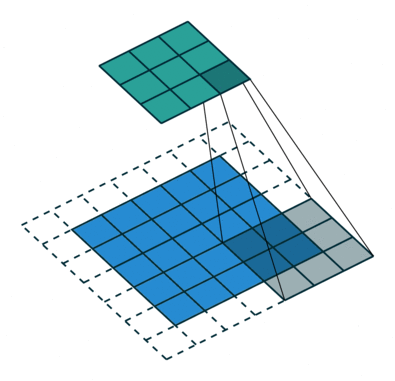
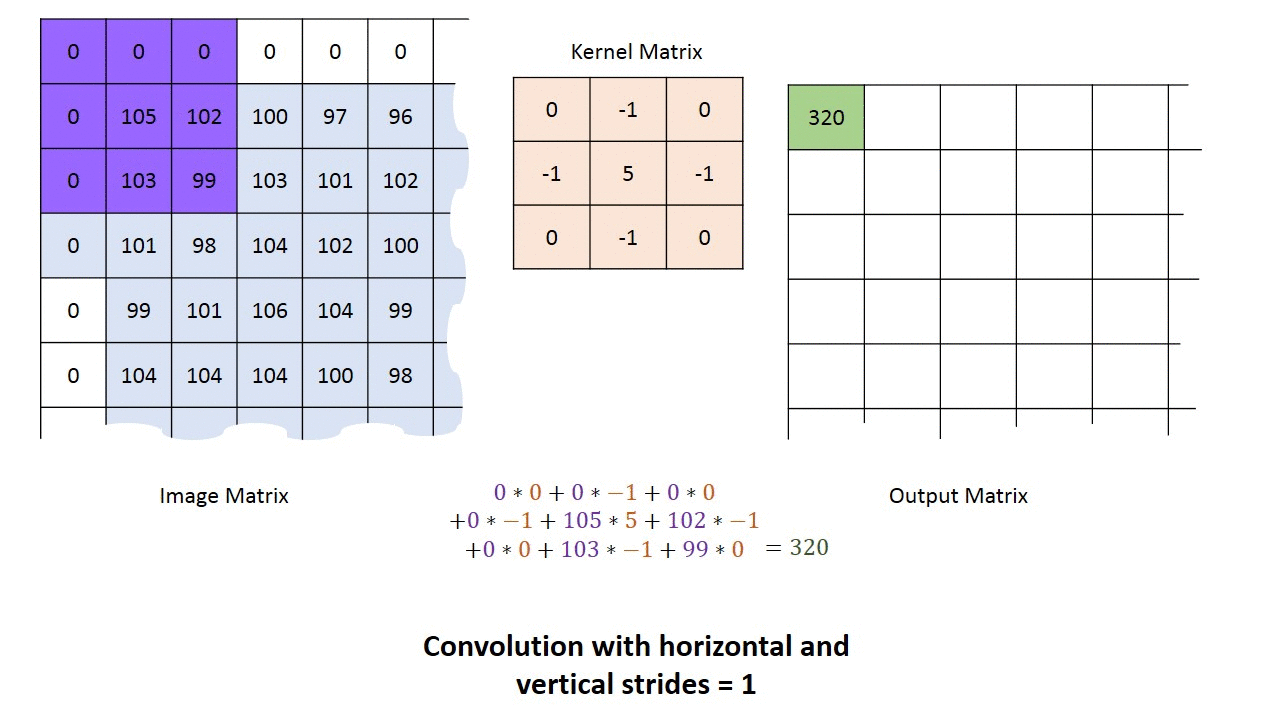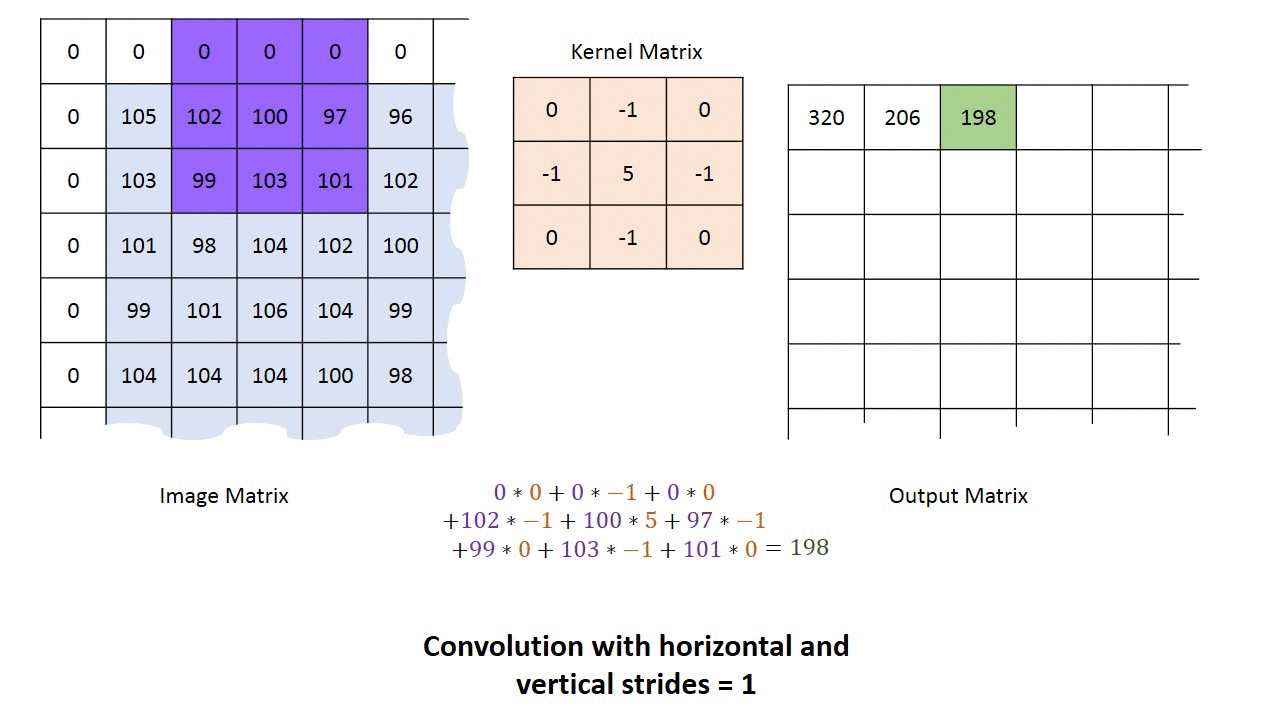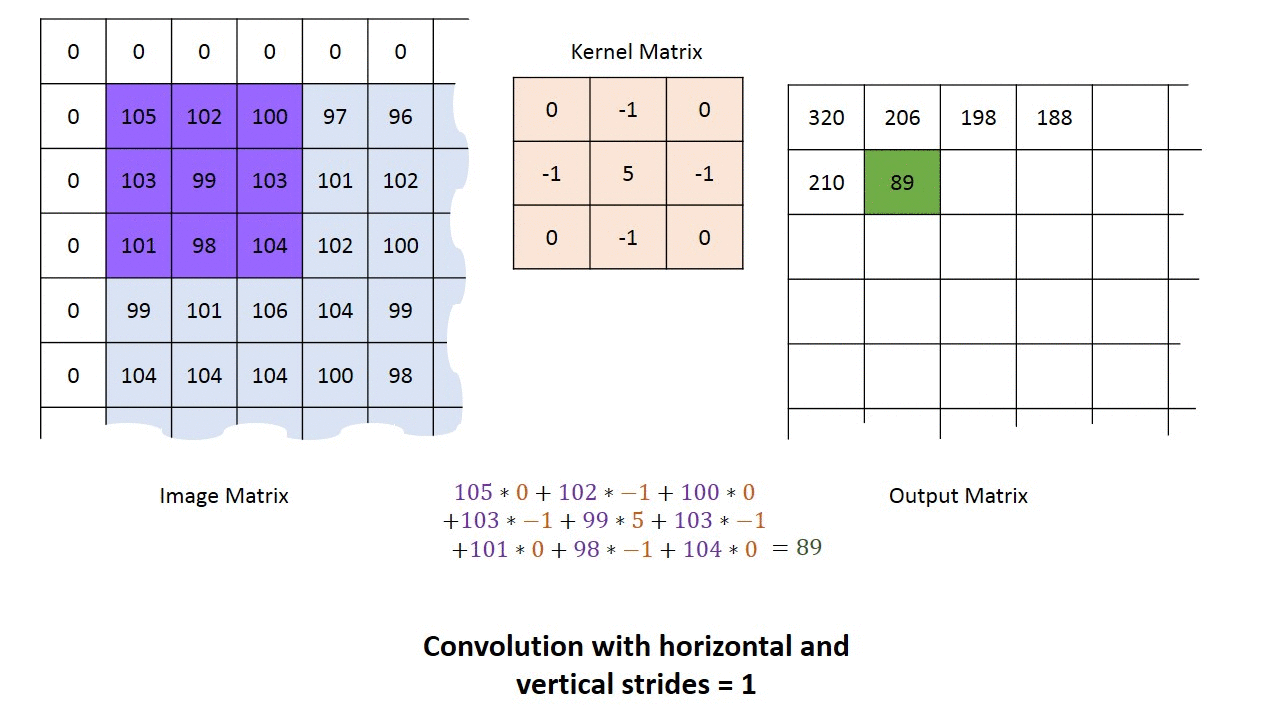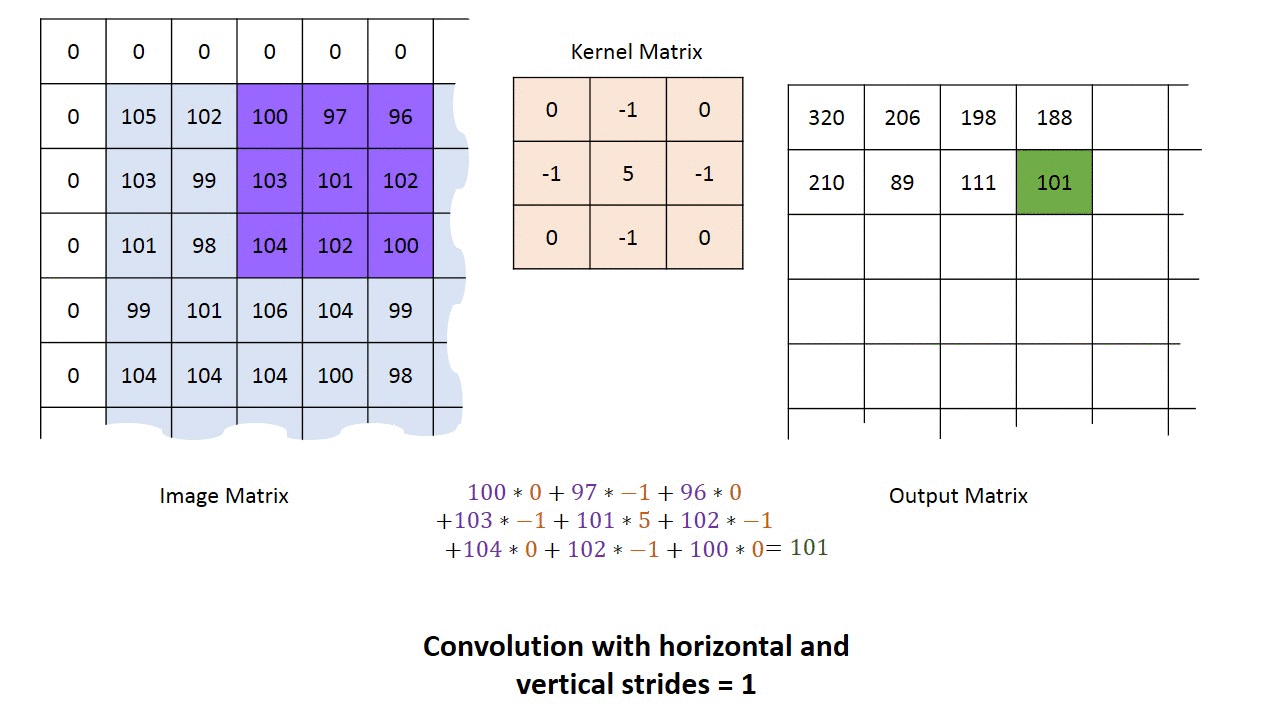
卷积神经网络的卷积具体计算就是卷积核和图像的值进行点积运算,得到相应的像素点的值。卷积相关的参数有padding, stride,卷积核大小,各种情况下的卷积过程如下动画所示。
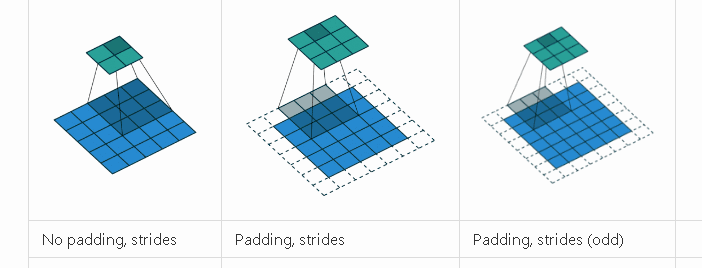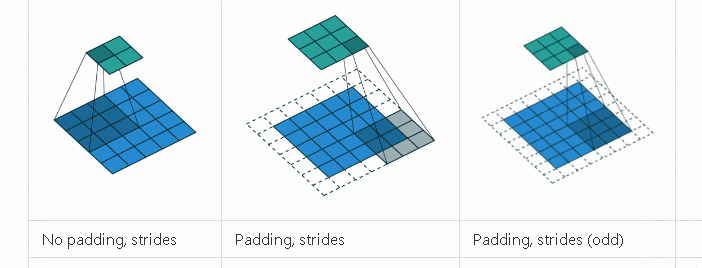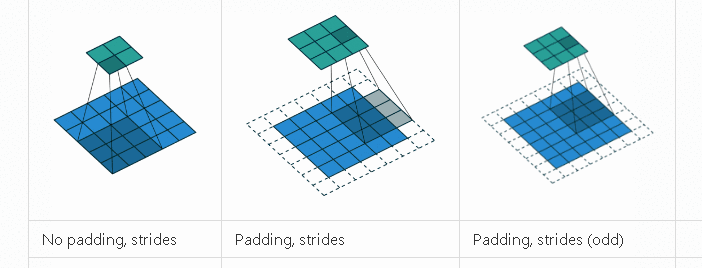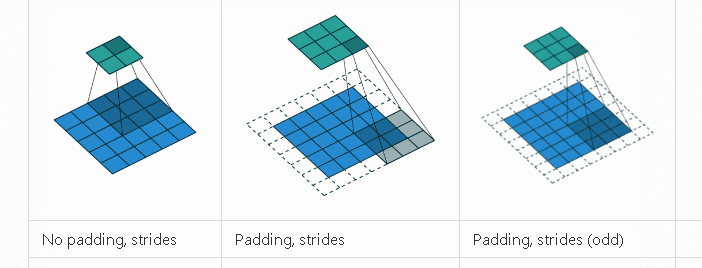

-
单输入单输出通道卷积过程的动画如下

-
带padding的单输入单输出通道卷积过程的动画如下
-
多输入通道单输出通道卷积
-
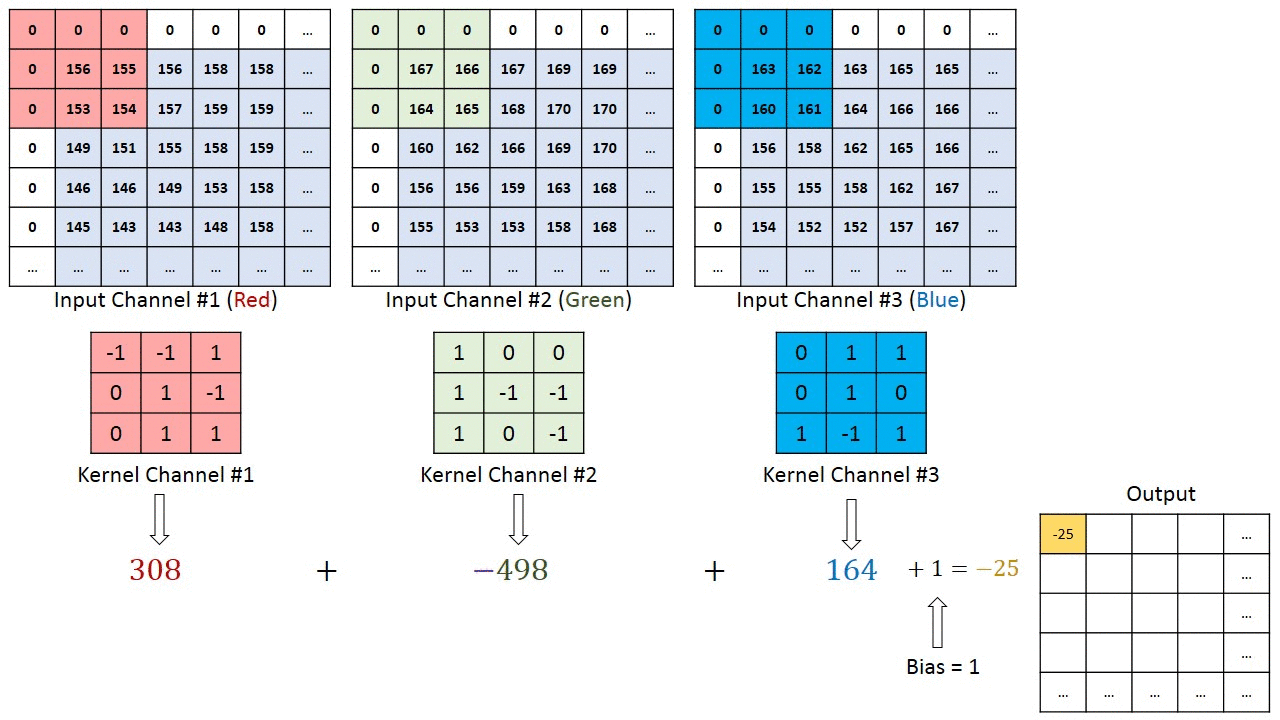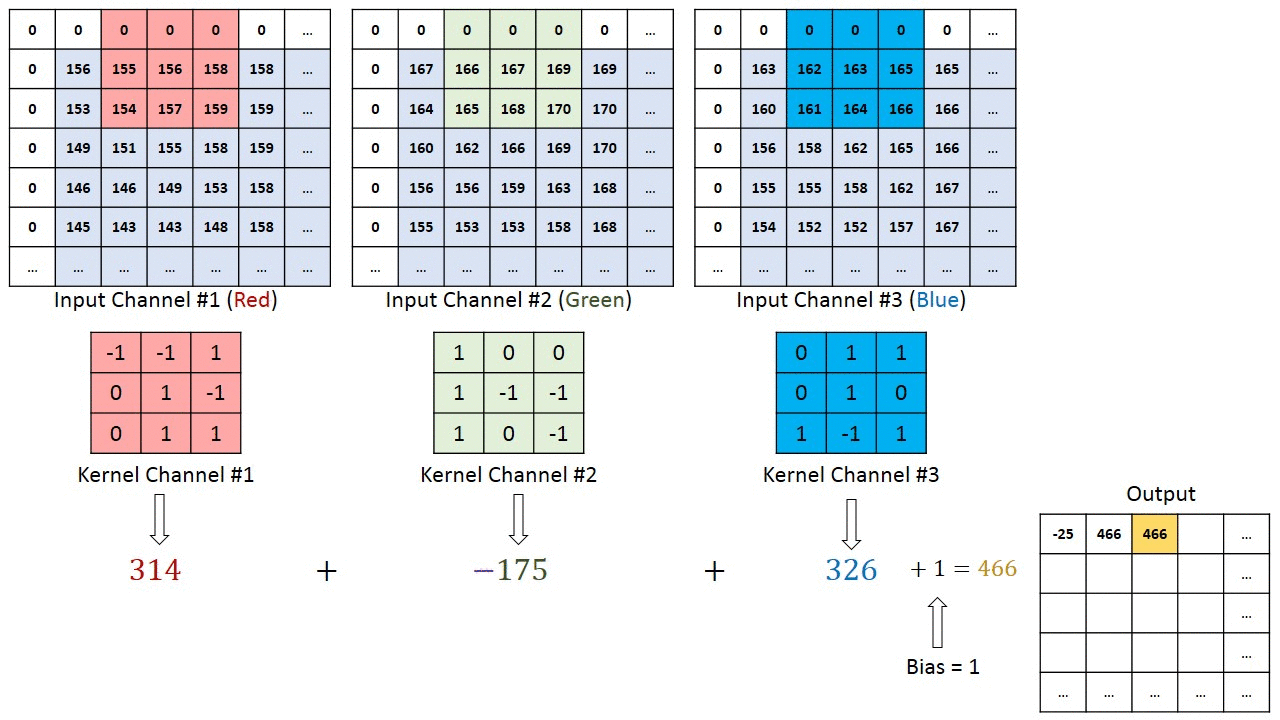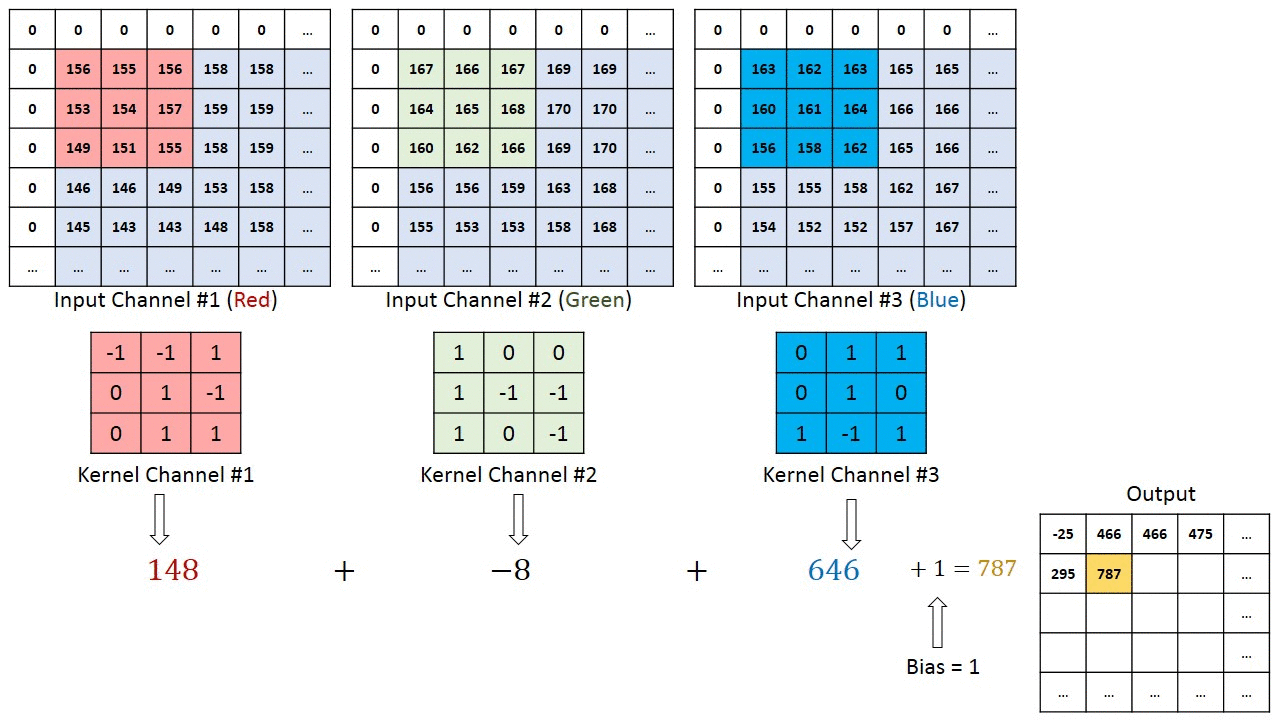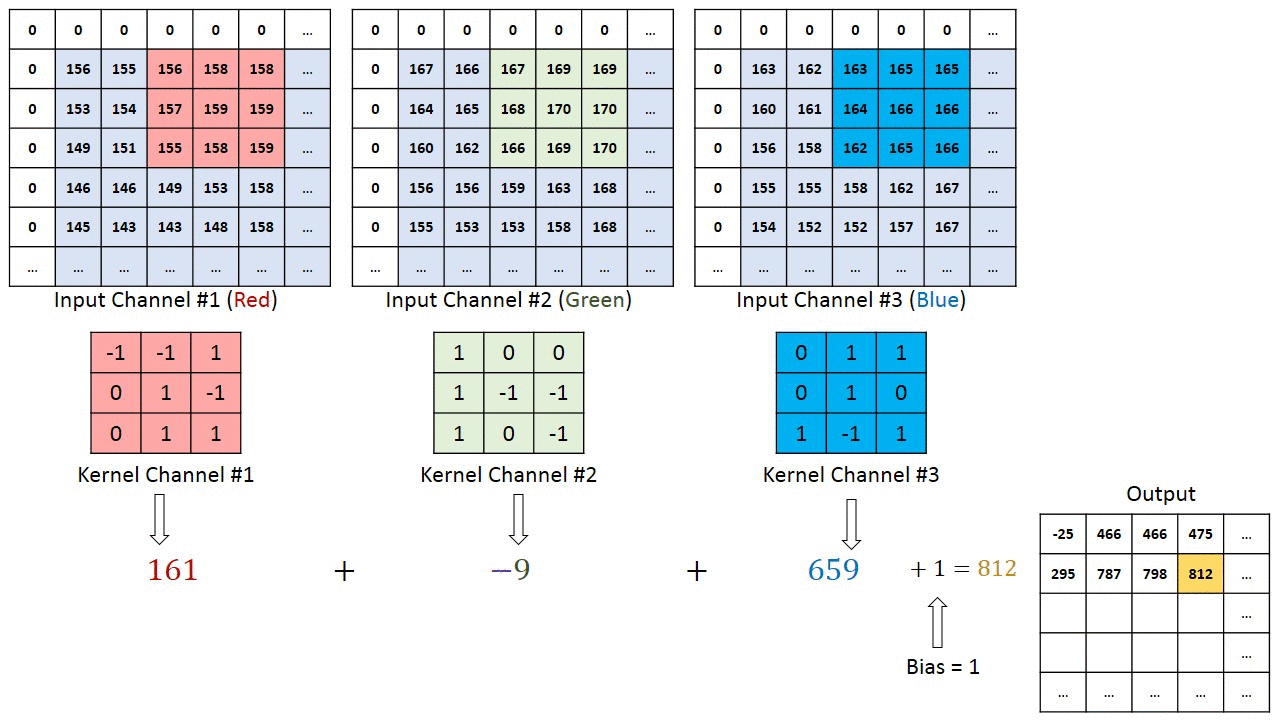
-
多输入通道多输出通道卷积
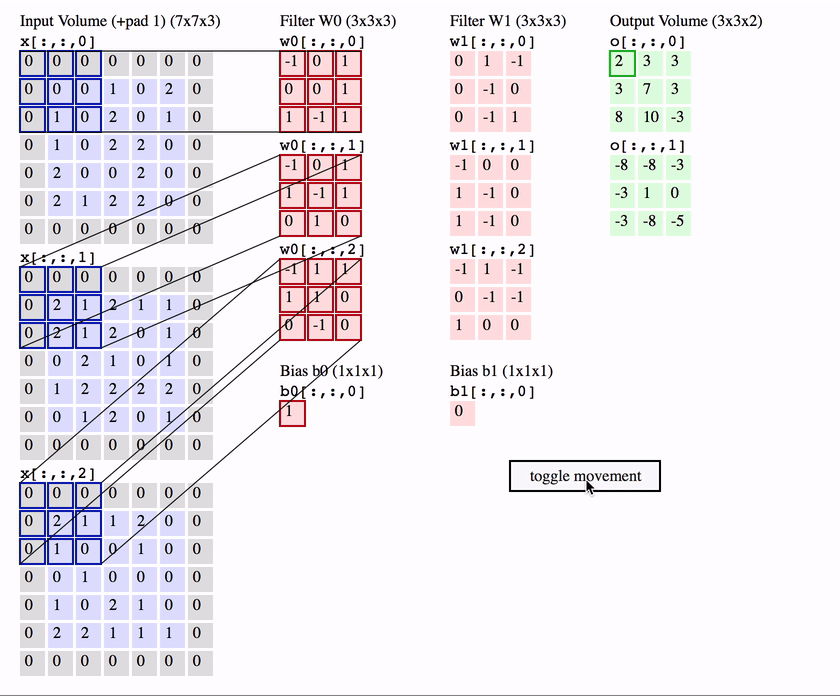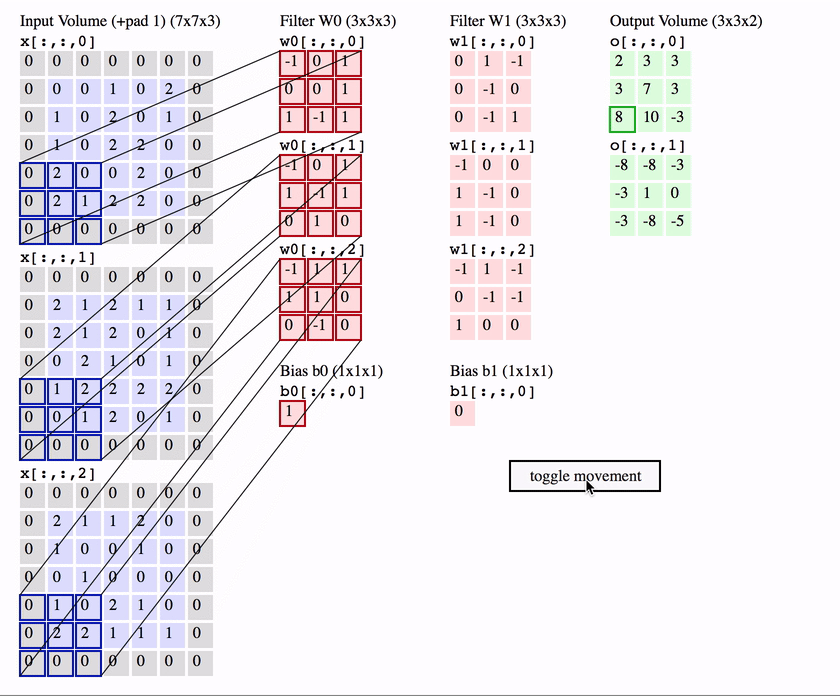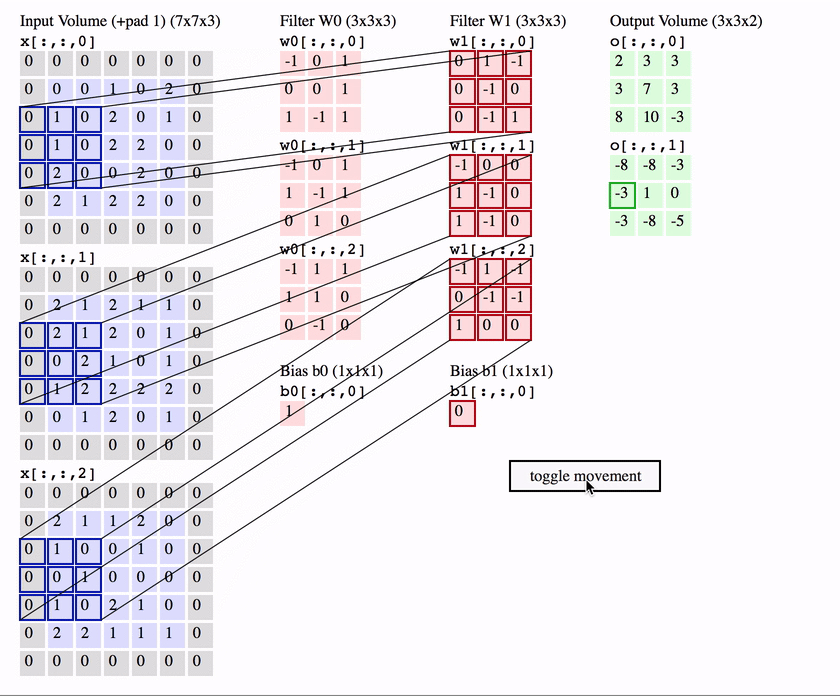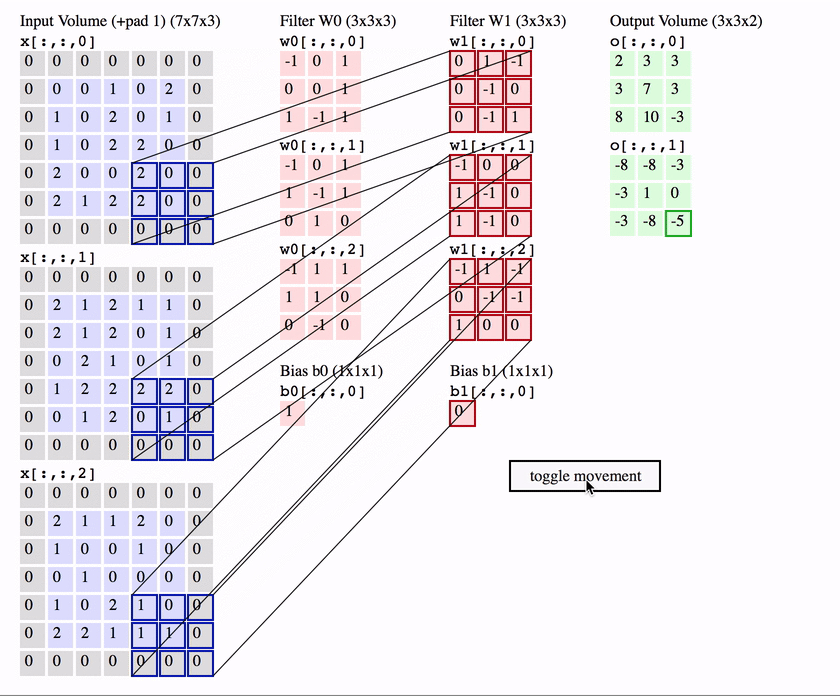
-
输出图片大小计算
卷积往往会降低图片的大小,降维采集特征,属于下采样的一种,输出图像大小和这些参数关系如下:
-
输入图片大小W
-
卷积核大小F
-
Padding大小P
-
Strides大小S
-
输出图像大小
N = (W − F + 2P )/S+1
实践中Padding往往是深度学习平台自动算出来,比如Tensorflow提供了两种Padding模式,valid和same模式。valid模式下padding=0, 可能会有部分像素不参与卷积,same模式下通过周围补0来让所有像素都能参与卷积,平台会自动算出Padding值,这两种模式下对应的输出图片大小如下:
-
Same模式
out_height = ceil(float(in_height) / float(strides[1]))
out_width = ceil(float(in_width) / float(strides[2]))
-
Valid模式
out_height = ceil(float(in_height - filter_height + 1) / float(strides[1]))
out_width = ceil(float(in_width - filter_width + 1) / float(strides[2]))
输出图片的通道数量
输出图片的通道数量等于卷积核的输出通道量
-
输入图片的shape: [inChannels, width, height]
-
卷积核的shape: [outChannels, inChannels, width, height]
-
输出图片的shape: [outChannels, outWidth, outHeight]
池化
池化也是一种下采样技术
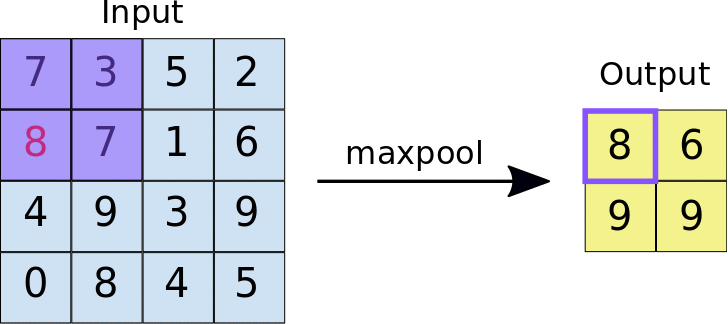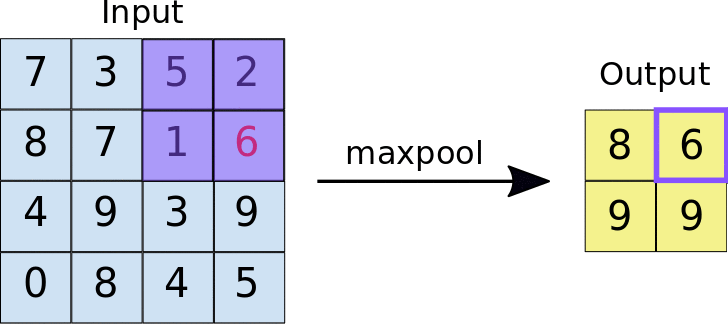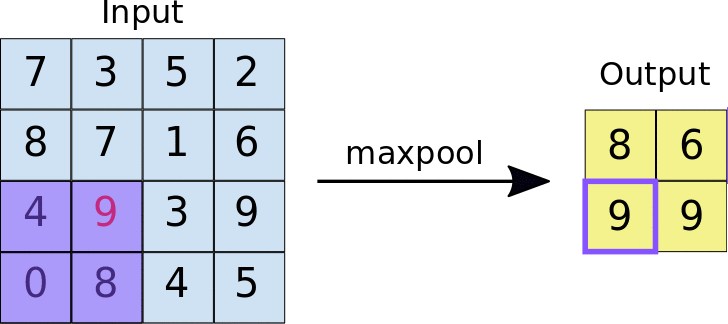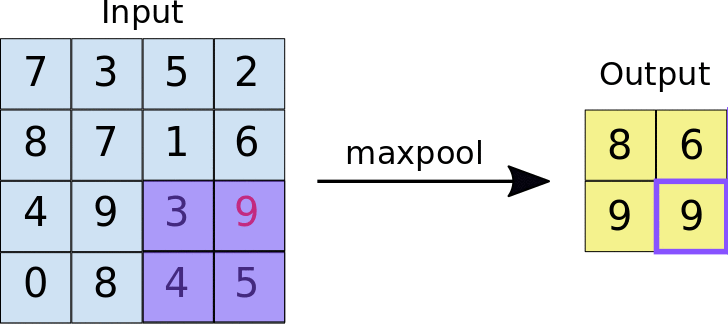
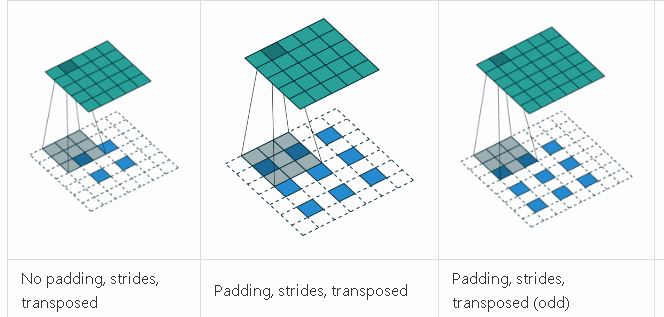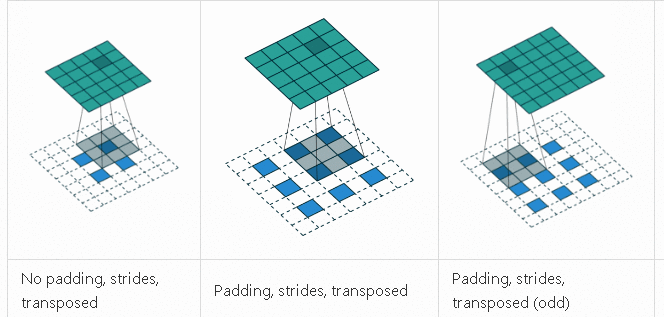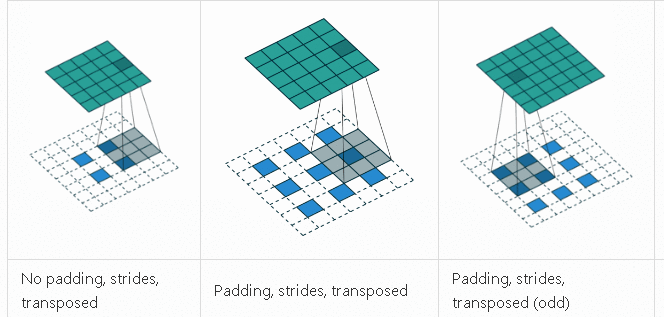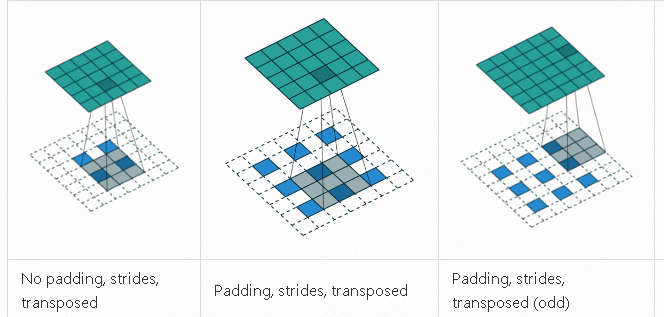
反卷积
反卷积是一种上采样技术, 用来升维还原作用, 比如抠图需要还原出原始图像大小的Mask。反卷积的计算过程和卷积差不多, 只不过它通过补零的方式扩大了原始图像然后再卷积, 最终结果是输出图片变大, 执行动画如下
Metal卷积代码实现分析
Shape
下面的代码会涉及到Shape,我们以一段代码来同步我们这里的shape的概念。
x = np.array([[1,2,5],[2,3,5],[3,4,5],[2,3,6]])
#输出数组的行和列数
print x.shape #结果: (4, 3)Metal里的图片数据存储结构
-
一般图像的数据内存结构对应的shape是[height, weight, channel], 比如RGB的图片就是[height, weight, 3], RGBA就是[height, weight, 4]。当然为了兼容,图片数据的数据可以都维持为[height, weight, 4],多余的channel填充为0即可。
-
考虑到CNN网络中的隐藏层的通道数量远不4,可以进一步将channel分解为4及slice(4的倍数), 形成这样的shape: [height, weight, slices, 4], 通道总数=slices*4。
-
由于Metal中的texture的一个像素单元可以定义为float4类型数据,所以texture的实际维数为3维:[height, weight, slices]。对于Metal texture来说,可以定义type2dArray,可以将slices这一维度放置到_numberOfImages, 当_numberOfImages大于1时就需要type2dArray类型的texture。

-
具体一个像素的format可以根据像素的占用的空间大小来确定,比如421格式可以定义为rgba16float格式。


-
对于卷积核weight来说,它的数据结构是[outChannels, height, width, slices, 4],其实为了和输入图片一致,这个卷积核以[outChannels, slices, height, width, 4]方式组织更容易理解,但是考虑到卷积核数据导出维护角度, 暂时使用了[outChannels, height, width, slices, 4]这种shape。同时卷积核一般以buffer方式存储和传递,而buffer里的数据单元也可以定义为float4, 因而卷积核在buffer中的存在维数是4维[outChannels, height, width, slices]。由卷积的具体算法可知,输入数据[height, weight, slices]和卷积核[outChannels, height, width, slices]卷积得到的输出图片的shape是[outChannels, height, width],但由于输出图片一般保存在texture里的,而texture的基本像素是float4, 因而真正的输出shape应该是如此结构[outChannels/4, height, width, 4], 所以输出texture的真正shape是[outSlices, height, width](outSlices= outChannels/4)。所以为了方便计算,卷积核的逻辑shape可以看成是[outSlices, 4, height, width, slices]。
代码实现分析
下面我们来看下通过Metal的Compute Shader怎样实现3x3卷积的

/**************************************************
* 本文来自CSDN博主"一点码客",喜欢请顶部点击关注
* 转载请标明出处:http://blog.csdn.net/itchosen
***************************************************/
如需实时查看更多更新文章,请关注公众号"一点码客",一起探索技术

