数据处理——数据读取
首先,引入一些库
import os
import pandas as pd
from sklearn.utils import shufflepandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
scikit-learn 是基于 Python 语言的机器学习工具
- 简单高效的数据挖掘和数据分析工具
- 可供大家在各种环境中重复使用
- 建立在 NumPy ,SciPy 和 matplotlib 上
- 开源,可商业使用 - BSD许可证
创建变量,分别存放图像和标签的地址
image_dir = '/root/private/ColorImage/'
label_dir = '/root/private/Gray_Label/'
label_list = []
image_list = []文件夹结构:
""" ColorImage/ road02/ Record002/ Camera 5/ ... Camera 6 Record003 .... road03 road04 Label/ Label_road02/ Label Record002/ Camera 5/ ... Camera 6 Record003 .... Label_road03 Label_road04 """
对图像和标签进行对应
for s1 in os.listdir(image_dir):os.listdir(image_dir)
我们之前将地址存到image_dir中,os.listdir函数返回一个list,list里面是image_dir文件下的文件名。
打印出来就是这样的:

按照路径连接的方式连接到一起
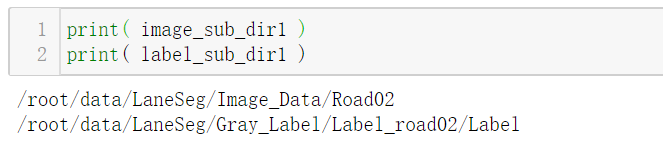
image_sub_dir1 = os.path.join(image_dir, s1)
label_sub_dir1 = os.path.join(label_dir,'Label_'+str.lower(s1), 'Label')由于我们这里有Road2,Road3,Road4文件夹,所以路径不同

for s2 in os.listdir(image_sub_dir1):
image_sub_dir2 = os.path.join(image_sub_dir1, s2)
label_sub_dir2 = os.path.join(label_sub_dir2, s2)
for s3 in os.listdir(image_sub_dir2):
image_sub_dir3 = os.path.join(image_sub_dir2, s3)
label_sub_dir3 = os.path.join(label_sub_dir2, s3)
到这里的目录,再往下就是图片了

for s4 in os.listdir(image_sub_dir3):
image_sub_dir4 = os.path.join(image_sub_dir3, s4)
label_sub_dir4 = os.path.join(label_sub_dir3, s4)
if not os.path.exists(image_sub_dir4):
print(image_sub_dir4)
continue
if not os.path.exists(label_sub_dir4):
print(label_sub_dir4)
image_list.append(image_sub_dir4)
label_list.append(label_sub_dir4)这里每个图片的单独路径就加载到list中了

这里要看一下两个list是否包含路径数量相同,如果不相同就有问题了。
assert len(image_list) == len(label_list)
print("The length of image dataset is {}, and label length is {}".format(len(image_list), len(label_list)))
长度一样,可以继续了》》》
划分训练集,验证集,测试集
划分dataset为 tarin:validate:test=6:2:2
total_length = len(image_list)
sixth_part = int(total_length*0.6)
eighth_part = int(total_length*0.8)
all = pd.DataFrame({'image':image_list, 'label':label_list})
all_shuffle = shuffle(all)
train_dataset = all_shuffle[:sixth_part]
val_dataset = all_shuffle[sixth_part:eighth_part]
test_dataset = all_shuffle[eighth_part:]pd.DataFrame()是pandas库中的一个数据结构,类似于excel表格,他是一个二维表。如图所示:

shuffle是洗牌操作,打散数据,shuffle(all)执行完后,如下图:

将最终的数据存入CSV中
train_dataset.to_csv('../data_list/train.csv', index=False)
val_dataset.to_csv('../data_list/val.csv', index=False)
test_dataset.to_csv('../data_list/test.csv', index=False)