HTTP
HTTP是一个客户端(用户)和服务器端(网站)之间进行请求和应答的标准。通过使用网页浏览器、网络爬虫或者其他工具,客户端可以向服务器上的指定端口(默认端口为80)发起一个HTTP请求。这个客户端成为客户代理(user agent)。应答服务器上存储着一些资源码,比如HTML文件和图像。这个应答服务器成为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。尽管TCP/IP是互联网最流行的协议,但HTTP中并没有规定必须使用它或它支持的层。
HTTP的请求方法有很多种,主要包括以下几个:
GET:向指定的资源发出“显示”请求。GET方法应该只用于读取数据,而不应当被用于“副作用”的操作中(例如在Web Application中)。其中一个原因是GET可能会被网络蜘蛛等随意访问。
HEAD:与GET方法一样,都是向服务器发出直顶资源的请求,只不过服务器将不会出传回资源的内容部分。它的好处在于,使用这个方法可以在不必传输内容的情况下,将获取到其中“关于该资源的信息”(元信息或元数据)。
POST:向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求文本中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
PUT:向指定资源位置上传输最新内容。
DELETE:请求服务器删除Request-URL所标识的资源,或二者皆有。
TRACE:回显服务器收到的请求,主要用于测试或诊断。
OPTIONS:这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用“*”来代表资源名称向Web服务器发送OPTIONS请求,可以测试服务器共能是否正常。
CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的连接(经由非加密的HTTP代理服务器)。方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed),当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。
html结构
我们的数据来源是网页,那么我们在真正抓取数据之前,有必要先了解一下一个网页的组成。网页是由 HTML 、 CSS 、JavaScript 组成的。HTML 是用来搭建整个网页的骨架,而 CSS 是为了让整个页面更好看,包括我们看到的颜色,每个模块的大小、位置等都是由 CSS 来控制的, JavaScript 是用来让整个网页“动起来”,这个动起来有两层意思,一层是网页的数据动态交互,还有一层是真正的动,比如我们都见过一些网页上的动画,一般都是由 JavaScript 配合 CSS 来完成的。
那我们怎么获取网页源代码呢,比如在我使用的chrome浏览器上,通常我们用F12(Fn+F12)打开页面检查器,或者单击鼠标右键点 检查 ,再点击element就可以看到一个网页的源代码,最左上角的箭头标识能帮我们定位网页元素在源代码中的位置。

在 HTML 中,所有标签定义的内容都是节点,它们构成了一个 HTML DOM 树。根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:整个文档是一个文档节点,每个 HTML 元素是元素节点,HTML 元素内的文本是文本节点,每个 HTML 属性是属性节点,注释是注释节点。
针对我们需要爬取的内容,我们可以用多种方式进行元素的定位,我们通过requests请求得到html后就可以用css选择器、xpath、re等等截取我们需要的内容。
基本请求requests
get方法
最基本的语句是:
import requests
url = ‘https://www.python.org/dev/peps/pep-0020/’
res = requests.get(url)
text = res.text
text
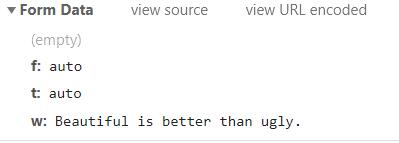
当请求为post时,即数据被包含在请求文本中,比如用金山词霸来翻译:

API使用
所谓的采集网络数据,并不一定必须从网页中抓取数据,而api(Application Programming Iterface应用程序接口)的用处就在这里:API为开发者提供了方便友好的接口,不同的开发者用不同的语言都能获取相同的数据。目前API一般会以XML(Extensible Markup Language,可拓展标记语言)或者JSON(JavaScript Object Notation)格式来返回服务器响应,其中JSON数据格式越来越受到人们的欢迎。
以百度地图提供的API为例,打开链接:http://lbsyun.baidu.com/apiconsole/key 填写自己的信息,并获取ak参数,代码如下:

使用API进行爬虫是很新颖的方法,也具有一定难度
我根据拾取坐标系统用selenium写了一个动态爬虫

AJAX技术
如果利用Requests库和BeautifulSoup来采集一些大型电商网站的页面,可能会发现一个令人疑感的现象,那就是对于同一个URL、同一个页面,抓取到的内容却与浏览器中看到的内容有所不同。比如有的时候去寻找某一个
AJAX技术与其说是一种“技术”,不如说是一种“方案”。在网页中使用JavaScript 加载页面中数据的过程,都可以看作AJAX技术。AJAX技术改变了过去用户浏览网站时一个请求对应一个页面的模式,允许浏览器通过异步请求来获取数据,从而使得一个页面能够呈现并容纳更多的内容,同时也就意味着更多的功能。只要用户使用的是主流的浏览器,同时允许浏览器执行JavaScript,用户就能够享受网页中的AJAX内容。
AJAX技术在逐渐流行的同时,也面临着一些批评和意见。由于JavaScript本身是作为客户端脚本语言在浏览器的基础上执行的,因此,浏览器兼容性成为不可忽视的问题。另外,由于JavaScript在某种程度上实现了业务逻辑的分离(此前的业务逻辑统一由服务器端实现),因此在代码维护上也存在一些效率问题。但总体而言,AJAX技术已经成为现代网站技术中的中流砥柱,受到了广泛的欢迎。AJAX目前的使用场景十分广泛,很多时候普通用户甚至察觉不到网页正在使用AJAX技术。 以知乎的首页信息流为例,与用户的主要交互方式就是用户通过下拉页面(具体操作可通过鼠标滚轮、拖动滚动条等实现)查看更多动态,而在一部分动态(对于知乎而言包括被关注用户的点赞和回答等)展示完毕后,就会显示一段加载动画并呈现后续的动态内容。此处的页面动画其实只是“障眼法”,在这个过程中,JavasScript脚本已向服务器请求发送相关数据,并最终加载到页面之中。这时页面显然没有进行全部刷新,而是只“新”刷新了一部分,通过这种异步加载的方式完成了对新内容的获取和呈现,这个过程就是典型的AJAX应用。
比较尴尬的是,爬虫一般不能执行包括“加载新内容”或者“跳到下一页”等功能在内的各类写在网页中的JavaScript代码。如本节开头所述,爬虫会获取网站的原始HTML页面,由于它没有像浏览器一样的执行JavaScript脚本的能力,因此也就不会为网页运行JavaScript。最终,爬虫爬取到的结果就会和浏览器里显示的结果有所差异,很多时候便不能直接获得想要的关键信息。为解决这个尴尬处境,基于Python编写的爬虫程序可以做出两种改进:
一种是通过分析AJAX内容(需要开发者手动观察和实验),观察其请求目标、请求内容和请求的参数等信息,最终编写程序来模拟这样的JavaScript 请求,从而获取信息(这个过程也可以叫作“逆向工程”)。另外一种方式则比较取巧,那就是直接模拟出浏览器环境,使得程序得以通过浏览器模拟工具“移花接木”,最终通过浏览器渲染后的页面来获得信息。这两种方式的选择与JavaScript在网页中的具体使用方法有关。以后会分享爬取知乎、各大数据库等动态爬虫实例。
