知识点1:
传输控制协议:
Transport Control Protocol(TCP)

知识点2:
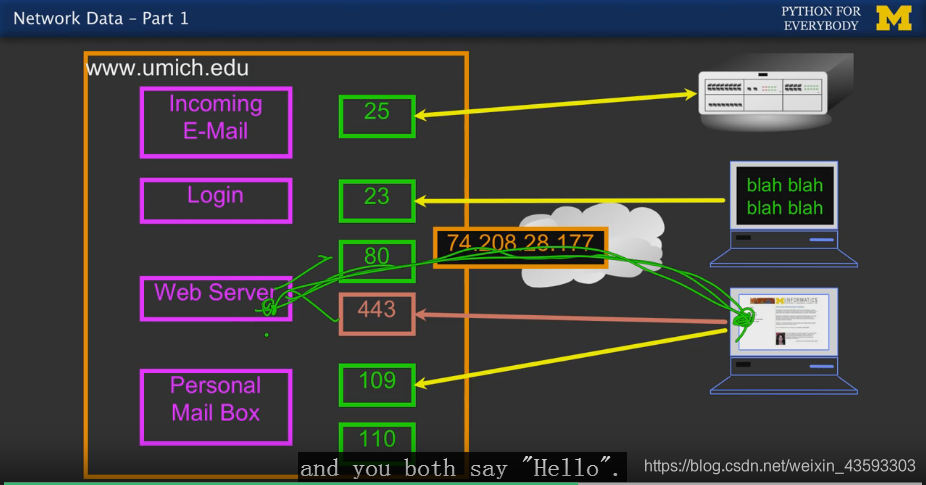
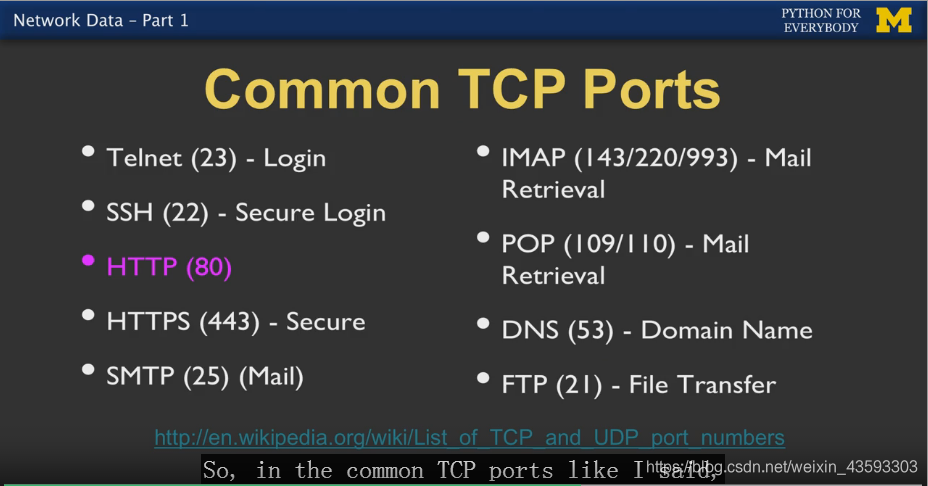
TCP Port Numbers:

知识点3:
Sockets in python(python中的接口)
import socket
mysock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
mysock.connect(('data.pr4e.org' , 80))
在以上代码当中,data.pr4e.org是HOST
80是PORT
知识点4:
超文本传输协议(HTTP)


URLs: Uniform Resources Locators (统一资源定位器)
herf value:如果要从HTML中点到另一个文件,这个HTML中就有这个文件的herf value
知识点5:
从一个页面的链接调到另一个页面的原理(Request Response Cycle)

具体的步骤:
- 点击连接后,browser识别出了点击,便在这个网页的HTML中找相关信息,需要链接哪个服务器,链接哪个端口,检索哪个文件。
- browser建立与对应端口的链接后,发出一个“Get Request”到端口80(指定的端口)。
- 对应的服务器分析这个Request然后找出正在寻找的文件。
- 服务器以HTML的形式作出回应,如图中的绿色块,这块HTML包含了很多的信息。
- 浏览器读取回应的相关信息,作出显示。

以上这是古老的Telnet的操作方式。
输入第一个字块的内容,返回紫块和蓝块,其中紫块为header,蓝块为content of the file
实例:

注释:
- 前两行,导入socket和连接socket,socket就好比是服务器的门,连接了socket知识触碰到了门把手,有了开门的办法,但是还是没有实际打开门。
- 执行完第三行是真正连接上了,但是还没有"send stuff"。
- 可以使用socket自带的receive和send等来进行send or receive stuff。
- 注意cmd末尾的encode,该具体的作用下回分解。
- 注意\r\n\r\n是两个enter,类比古老的Telnet的 操作方式。
- 用一个while loop来接收服务器发回的数据,其中if-break是文件的最后或者传输完成的标志。
- 如果不是传输的最后,获取到了数据,就decode
实际代码为:
import socket #导入对应的库
mysock = socket.socket(socket.AF_INET , socket.SOCK_STREAM) #摸到门把手
mysock.connect(('data.pr4e.org' , 80))
cmd = 'GET http://data.pr4e.org/romeo.txt HTTP/1.0\n\n'.encode() #send HTTP comand,如果这段代码出现了问题,尝试将\n\n更改为\r\n\r\n
mysock.send(cmd)
while True:
data = mysock.recv(512)
if(len(data)<1): #传输完成或到最后一个字符
break
print(data.decode())
mysock.close()
输出结果为:

如果直接复制的话:
HTTP/1.1 400 Bad Request
Date: Sun, 23 Jun 2019 01:57:33 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Length: 308
Connection: close
Content-Type: text/html; charset=iso-8859-1
Bad Request
Your browser sent a request that this server could not understand.
Apache/2.4.18 (Ubuntu) Server at do1.dr-chuck.com Port 80
可见是出了问题的,因此将代码修改为:
cmd = 'GET http://data.pr4e.org/romeo.txt HTTP/1.0\r\n\r\n'.encode()
运行结果为:

解读 .encode()的作用
因为在python当中字符串都是统一编码的(unicode),而我们要用UTF-8编码模式进行交互。因此,encode的作用就是将unicode转化为UTF-8。
