一、iostat
iostat用于输出CPU和磁盘I/O相关的统计信息.
不加选项执行iostat
[patrickxu@vm1 ~]$ iostat
Linux 2.6.32-279.19.3.el6.ucloud.x86_64 (vm1) 06/11/2017 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.08 0.00 0.06 0.00 0.00 99.86
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
vda 0.45 0.29 8.10 6634946 183036680
vdb 0.12 3.11 30.55 70342034 689955328单独执行iostat,显示的结果为从系统开机到当前执行时刻的统计信息。
以上输出中,包含三部分:
| 选项 | 说明 |
|---|---|
| 第一行 | 最上面指示系统版本、主机名和当前日期 |
| avg-cpu | 总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值 |
| Device | 各磁盘设备的IO统计信息 |
Device中各列参数含义如下:
| 选项 | 说明 |
|---|---|
| %user | CPU在用户态执行进程的时间百分比。 |
| %nice | CPU在用户态模式下,用于nice操作,所占用CPU总时间的百分比 |
| %system | CPU处在内核态执行进程的时间百分比 |
| %iowait | CPU用于等待I/O操作占用CPU总时间的百分比 |
| %steal | 管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟CPU的百分比 |
| %idle | CPU空闲时间百分比 |
1. 若 %iowait 的值过高,表示硬盘存在I/O瓶颈
2. 若 %idle 的值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量
3. 若 %idle 的值持续低于1,则系统的CPU处理能力相对较低,表明系统中最需要解决的资源是 CPU
avg-cpu中各列参数含义如下:
| 选项 | 说明 |
|---|---|
| Device | 设备名称 |
| tps | 每秒向磁盘设备请求数据的次数,包括读、写请求,为rtps与wtps的和。出于效率考虑,每一次IO下发后并不是立即处理请求,而是将请求合并(merge),这里tps指请求合并后的请求计数。 |
| Blk_read/s | Indicate the amount of data read from the device expressed in a number of blocks per second. Blocks are equivalent to sectors with kernels 2.4 and later and therefore have a size of 512 bytes. With older kernels, a block is of indeterminate size. |
| Blk_wrtn/s | Indicate the amount of data written to the device expressed in a number of blocks per second. |
| Blk_read | 取样时间间隔内读扇区总数量 |
| Blk_wrtn | 取样时间间隔内写扇区总数量 |
我们可以使用-c选项单独显示avg-cpu部分的结果,使用-d选项单独显示Device部分的信息。
2.指定采样时间间隔与采样次数
与sar命令一样,我们可以以”iostat interval [count] ”形式指定iostat命令的采样间隔和采样次数:
[patrickxu@vm1 ~]$ iostat -d 2 3
Linux 2.6.32-279.19.3.el6.ucloud.x86_64 (vm1) 06/12/2017 _x86_64_ (8 CPU)
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
vda 0.45 0.29 8.10 6634946 183051408
vdb 0.12 3.11 30.55 70342034 689955328
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
vda 0.00 0.00 0.00 0 0
vdb 0.00 0.00 0.00 0 0
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
vda 1.50 0.00 12.00 0 24
vdb 0.00 0.00 0.00 0 0以上命令输出Device的信息,采样时间为1秒,采样2次,若不指定采样次数,则iostat会一直输出采样信息,直到按”ctrl+c”退出命令。注意,第1次采样信息与单独执行iostat的效果一样,为从系统开机到当前执行时刻的统计信息。
3.以kB为单位显示读写信息(-k选项)/以mB为单位显示读写信息(-m选项)
我们可以使用-k选项,指定iostat的部分输出结果以kB为单位,而不是以扇区数为单位:
以上输出中,kB_read/s、kB_wrtn/s、kB_read和kB_wrtn的值均以kB为单位,相比以扇区数为单位,这里的值为原值的一半(1kB=512bytes*2)
4.更详细的io统计信息(-x选项)
为显示更详细的io设备统计信息,我们可以使用-x选项,在分析io瓶颈时,一般都会开启-x选项:
linux # iostat -x -k -d 1
Linux 2.6.16.60-0.21-smp (linux) 06/13/12
……
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 9915.00 1.00 90.00 4.00 34360.00 755.25 11.79 120.57 6.33 57.60以上各列的含义如下:
| 选项 | 说明 |
|---|---|
| rrqm/s | 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并 |
| wrqm/s | 每秒对该设备的写请求被合并次数 |
| r/s | 每秒完成的读次数 |
| w/s | 每秒完成的写次数 |
| rkB/s | 每秒读数据量(kB为单位) |
| wkB/s | 每秒写数据量(kB为单位) |
| avgrq-sz | 平均每次IO操作的数据量(扇区数为单位) |
| avgqu-sz | 平均等待处理的IO请求队列长度 |
| await | 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位) |
| svctm | 平均每次IO请求的处理时间(毫秒为单位) |
| %util | 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率 |
对于以上示例输出,我们可以获取到以下信息:
- 每秒向磁盘上写30M左右数据(wkB/s值)
- 每秒有91次IO操作(r/s+w/s),其中以写操作为主体
- 平均每次IO请求等待时间为120.57毫秒,处理时间为6.33毫秒
- 等待处理的IO请求队列中,平均有11.79个请求驻留
实际查看时,一般结合着多个选项查看: 如iostat -dxm 3
[root@yg-uhost724 ~]# iostat -dxm 5
Linux 2.6.32-279.19.16.el6.ucloud.x86_64 (yg-uhost724) 06/12/2017 _x86_64_ (24 CPU)
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await svctm %util
sda 0.69 29.89 1.36 21.52 0.05 0.20 23.04 0.04 1.96 0.29 0.67
sdb 682.88 1811.86 77.94 417.73 2.97 8.71 48.27 0.01 0.03 0.10 4.89
dm-14 0.00 0.00 0.03 41.47 0.00 0.16 8.00 0.01 0.12 0.02 0.10
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 8.00 0.00 7.24 0.07 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 8.00 0.00 0.07 0.04 0.00
dm-3 0.00 0.00 0.00 0.98 0.00 0.00 8.00 0.00 3.57 0.22 0.02
dm-5 0.00 0.00 0.18 50.51 0.00 0.20 8.00 0.03 0.44 0.01 0.07
dm-1 0.00 0.00 1.50 5.51 0.01 0.02 8.00 0.03 4.04 0.04 0.03
dm-6 0.00 0.00 123.23 1042.56 0.48 4.07 8.00 0.01 0.01 0.02 1.90
dm-4 0.00 0.00 635.74 1069.59 2.48 4.18 8.00 0.00 0.04 0.01 2.39
sdc 7.23 106.32 0.52 0.94 0.03 0.42 627.54 0.02 13.32 17.58 2.58
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 15.00 0.40 17.80 0.00 0.10 10.90 0.00 0.10 0.10 0.18
sdb 82.60 11967.00 414.60 2500.20 1.94 56.51 41.07 12.07 4.14 0.07 21.02
dm-14 0.00 0.00 0.00 0.20 0.00 0.00 8.00 0.00 0.00 0.00 0.00
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-3 0.00 0.00 0.00 1.80 0.00 0.01 8.00 0.00 0.11 0.11 0.02
dm-5 0.00 0.00 0.00 2.00 0.00 0.01 8.00 0.00 0.00 0.00 0.00
dm-1 0.00 0.00 0.00 2.40 0.00 0.01 8.00 0.01 4.17 1.25 0.30
dm-6 0.00 0.00 0.00 45.20 0.00 0.18 8.00 0.11 2.45 0.55 2.48
dm-4 0.00 0.00 497.20 14415.80 1.94 56.31 8.00 72.87 4.83 0.01 19.14
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00二、mpstat
mpstat是Multiprocessor Statistics的缩写,是实时监控工具,报告与cpu的一些统计信息这些信息都存在/proc/stat文件中,在多CPU系统里,其不但能查看所有的CPU的平均状况的信息,而且能够有查看特定的cpu信息,mpstat最大的特点是:可以查看多核心的cpu中每个计算核心的统计数据;而且类似工具vmstat只能查看系统的整体cpu情况
查看多核cpu当前运行的状况,每两秒更新一次,一共更新5次
# mpstat 2 5
Linux 3.10.0-327.el7.x86_64 (yankerp) 11/01/2017 _x86_64_ (1 CPU)
07:13:28 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
07:13:30 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
07:13:32 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
07:13:34 PM all 0.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 99.00
07:13:36 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
07:13:38 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
Average: all 0.10 0.00 0.10 0.00 0.00 0.00 0.00 0.00 0.00 99.80sar(System ActivityReporter系统活动情况报告)是目前Linux上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等,sar命令有sysstat安装包安装。
三、sar命令使用一些参数可以使用sar --help来查看
Usage: sar [ options ] [ <interval> [ <count> ] ]
Options are:
[ -A ] [ -B ] [ -b ] [ -C ] [ -d ] [ -H ] [ -h ] [ -p ] [ -q ] [ -R ]
[ -r ] [ -S ] [ -t ] [ -u [ ALL ] ] [ -V ] [ -v ] [ -W ] [ -w ] [ -y ]
[ -I { <int> [,...] | SUM | ALL | XALL } ] [ -P { <cpu> [,...] | ALL } ]
[ -m { <keyword> [,...] | ALL } ] [ -n { <keyword> [,...] | ALL } ]
[ -j { ID | LABEL | PATH | UUID | ... } ]
[ -f [ <filename> ] | -o [ <filename> ] | -[0-9]+ ]
[ -i <interval> ] [ -s [ <hh:mm:ss> ] ] [ -e [ <hh:mm:ss> ] ]
- -A:所有报告的总和
- -b:显示I/O和传递速率的统计信息
- -B:显示换页状态
- -d:输出每一块磁盘的使用信息
- -e:设置显示报告的结束时间
- -f:从制定的文件读取报告
- -i:设置状态信息刷新的间隔时间
- -P:报告每个CPU的状态
- -R:显示内存状态
- –u:输出cpu使用情况和统计信息
- –v:显示索引节点、文件和其他内核表的状态
- -w:显示交换分区的状态
- -x:显示给定进程的装
- -r:报告内存利用率的统计信息
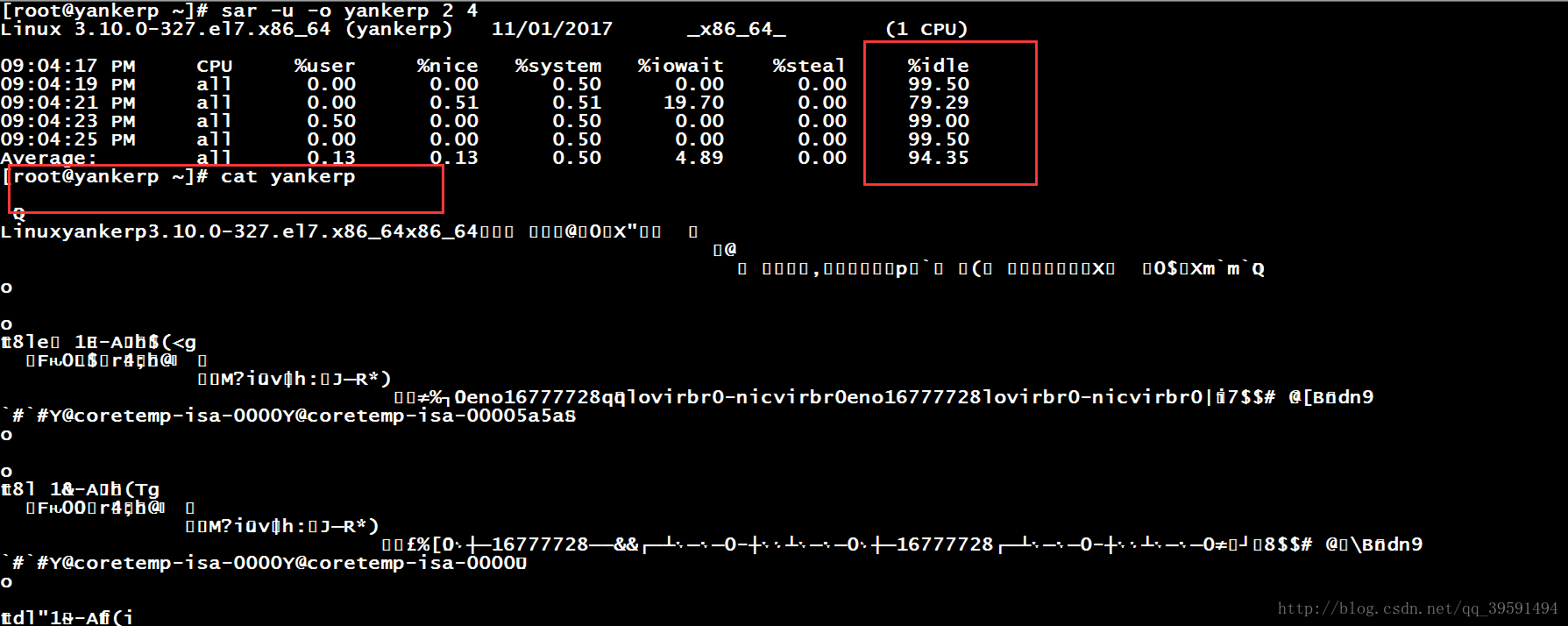
列1:每2秒采样一次,连续4次,观察cpu的使用情况,并将采样的结果以二进制形式存入当前目录下的文件yankerp中,如下:
# sar -u -o yankerp 2 4
# sar -u -f /root/yankerp 从二进制中调取
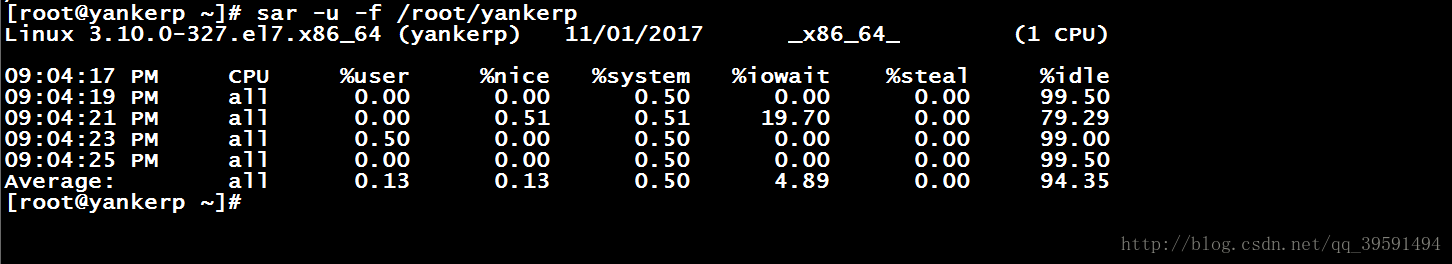
# sar -p 1 4报告每个cpu的状态,1秒一次一共4次

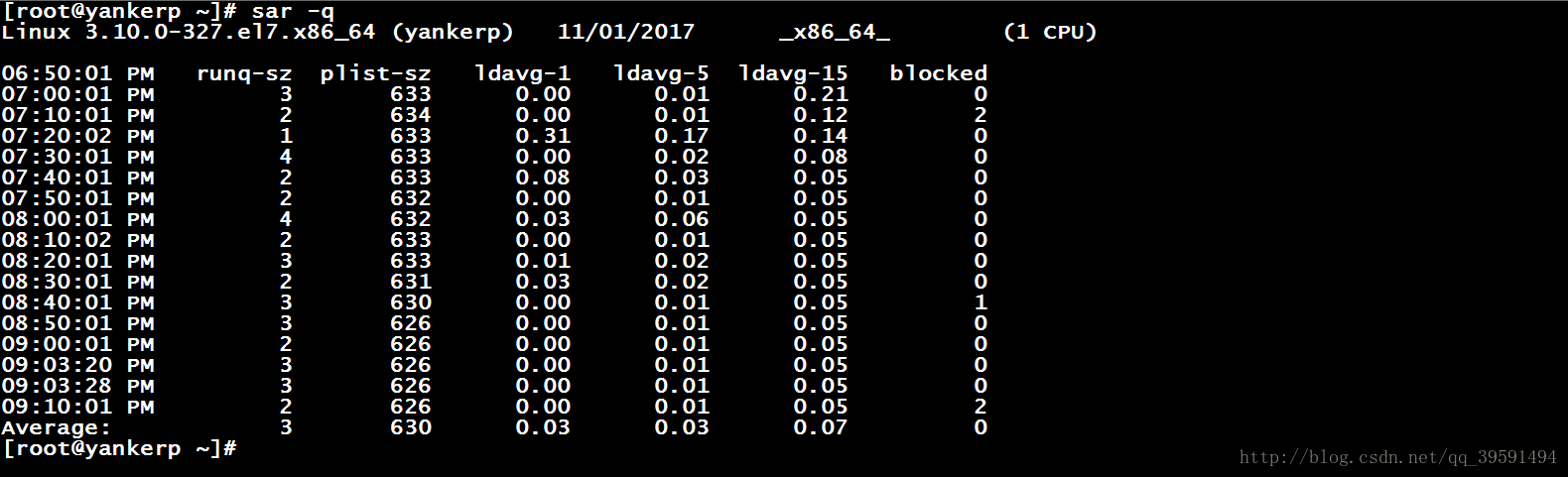
sar -q查看平均负载
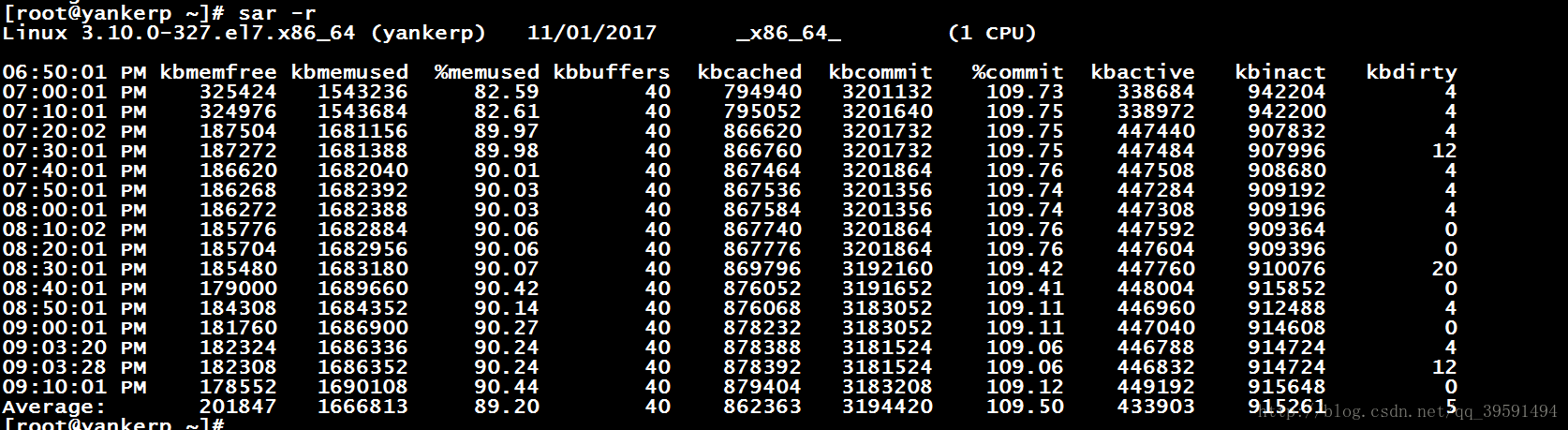
sar -r查看内存使用情况
sar -w查看系统swap分区的统计信息
sar -b查看I/O传递速率的信息
sar -d磁盘使用统计信息
默认监控: sar 5 5 // CPU和IOWAIT统计状态
(1) sar -b 5 5 // IO传送速率
(2) sar -B 5 5 // 页交换速率
(3) sar -c 5 5 // 进程创建的速率
(4) sar -d 5 5 // 块设备的活跃信息
(5) sar -n DEV 5 5 // 网路设备的状态信息
(6) sar -n SOCK 5 5 // SOCK的使用情况
(7) sar -n ALL 5 5 // 所有的网络状态信息
(8) sar -P ALL 5 5 // 每颗CPU的使用状态信息和IOWAIT统计状态
(9) sar -q 5 5 // 队列的长度(等待运行的进程数)和负载的状态
(10) sar -r 5 5 // 内存和swap空间使用情况
(11) sar -R 5 5 // 内存的统计信息(内存页的分配和释放、系统每秒作为BUFFER使用内存页、每秒被cache到的内存页)
(12) sar -u 5 5 // CPU的使用情况和IOWAIT信息(同默认监控)
(13) sar -v 5 5 // inode, file and other kernel tablesd的状态信息
(14) sar -w 5 5 // 每秒上下文交换的数目
(15) sar -W 5 5 // SWAP交换的统计信息(监控状态同iostat 的si so)
(16) sar -x 2906 5 5 // 显示指定进程(2906)的统计信息,信息包括:进程造成的错误、用户级和系统级用户CPU的占用情况、运行在哪颗CPU上
(17) sar -y 5 5 // TTY设备的活动状态
(18) 将输出到文件(-o)和读取记录信息(-f)
sar为转载文章,更多详细请参考原文:http://www.cnblogs.com/howhy/p/6396437.html 感谢博主的分享
四、vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
[root@yankerp ~]# vmstat 2 6

以上表示2秒采集一次一共6次
在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如:
[root@yankerp ~]# vmstat 2
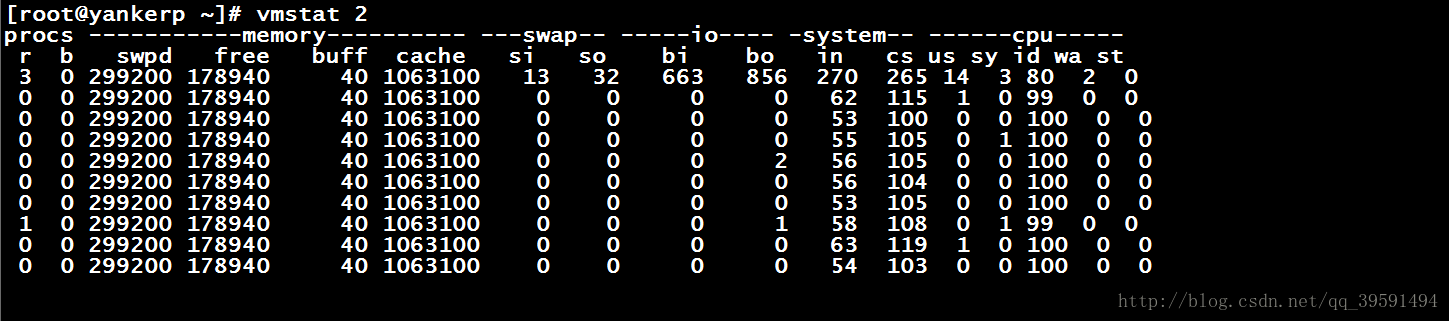
这样的话就是2,秒执行一次,会一直的执行下去。
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存
cache cache直接用来记忆我们打开的文件,给文件做缓冲
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数
us 用户CPU时间
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间
wt 等待IO CPU时间。
