pandas 常见绘图总结
文章目录
前言
pandas的强大让人毋庸置疑,一个集数据审阅、处理、分析、可视化于一身的工具,非常好用。
大家都知道,Matplotlib 是众多 Python 可视化包的鼻祖,也是Python最常用的标准可视化库,其功能非常强大,同时也非常复杂,想要搞明白并非易事。所幸pandas本身就有数据可视化的功能已经可以满足我们大部分的要求了,也就省下了我们很多自己使用 如 Matplotlib 来数据可视化的工作。
一 设置字体和显示中文
Pandas在绘图时,会显示中文为方块,主要原因有二: matplotlib 字体问题,seaborn 字体问题。
没有中文字体,所以我们只要手动添加中文字体的名称就可以了,不过并不是添加我们熟悉的“宋体”或“黑体”这类的名称,而是要添加字体管理器识别出的字体名称,matplotlib自身实现的字体管理器在文件font_manager.py中,自动生成的可用字体信息在保存在文件fontList.cache里,可以搜索这个文件查看对应字体的名称,例如simhei.ttf对应的名称为’SimHei’,simkai.ttf对应的名称为’KaiTi_GB2312’等。因此我们只要把这些名称添加到配置文件中去就可以让matplotlib显示中文。
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.serif'] = ['KaiTi']
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题,或者转换负号为字符串
import seaborn as sns
sns.set_style("darkgrid",{"font.sans-serif":['KaiTi', 'Arial']}) #这是方便seaborn绘图得时候得字体设置
二 pandas 可视化(0.25.3版本)
“有道无术术尚可求,有术无道,止于术。”
这段话在可视化里面的意思就是:首相想清楚你要干嘛,不要一上来就瞎画一堆图,自己觉得NB,但是图都错的再牛逼也只是好看,并没什么作用。
画图前你要思考这几个问题:
- 你为什么要画图?
- 你要画什么图?
- 你这样画图对不对?
1 线形图
普通折线图以折线的上升或下降来表示统计数量的增减变化的统计图,叫作折线统计图。折线统计图不仅可以表示数量的多少,而且可以反映同一事物在不同时间里的发展变化的情况,虽然它不直接给出精确的数据(当然你也可以加上去),但是能够显示数据的变化趋势,反映事物的变化情况。
pandas 有两种绘制线形图的方法,一种是下面这种直接的利用DataFrame.plot()
test_dict = {'销售量':[1000,2000,5000,2000,4000,3000],'收藏':[1500,2300,3500,2400,1900,3000]}
line = pd.DataFrame(test_dict,index=['一月','二月','三月','四月','五月','六月'])
line.plot()
此外,还有另外的一种,因为在新版本的pandas当中,DataFrame.plot()不再给出kind=参数(具体细节可以详见官网),画一般的线图推荐使用:DataFrame.plot.line(self, x=None, y=None, **kwargs),例如:
line.plot.line()
一个带有子图的例子:
line.plot.line(subplots=True)
2 条形图
条形统计图可以清楚地表明各种数量的多少。条形图是统计图资料分析中最常用的图形。按照排列方式的不同,可分为纵式条形图和横式条形图;按照分析作用的不同,可分为条形比较图和条形结构图。
- 条形统计图的特点:
(1)能够使人们一眼看出各个数据的大小。
(2)易于比较数据之间的差别。
(3)能清楚的表示出数量的多少
2.1 垂直条形图
DataFrame.plot.bar(self, x=None, y=None, **kwargs)
普通条形图
line.plot.bar()
堆积条形图
line.plot.bar(stacked=True)
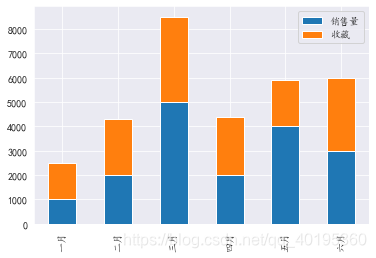
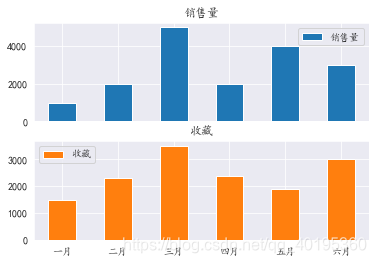
同理可绘制子图,并改变X轴的旋转方向:
line.plot.bar(subplots=True,rot=0)
2.2 水平条形图
DataFrame.plot.barh(self, x=None, y=None, **kwargs)
画图
line.plot.barh()

3 饼图
适用场景:显示各项的大小与各项总和的比例。适用简单的占比比例图,在不要求数据精细的情况适用。
优势:明确显示数据的比例情况,尤其合适渠道来源分析等场景。
line.plot.pie(subplots=True,figsize=(10, 8),autopct='%.2f%%',radius = 1.2,startangle = 250,legend=False,colormap='viridis')

这里参数稍微多了一点:
- subplots 为必要参数设置为True,当然也可以指定y的值。
- figsize 图片的大小。
- autopct 显示百分比。
- radius 圆的半径。
- startangle 旋转角度。
- legend 图例。
- colormap 颜色。
4 散点图
适用场景:显示若干数据系列中各数值之间的关系,类似XY轴,判断两变量之间是否存在某种关联。散点图适用于三维数据集,但其中只有两维需要比较。
优势:对于处理值的分布和数据点的分簇,散点图都很理想。如果数据集中包含非常多的点,那么散点图便是最佳图表类型。
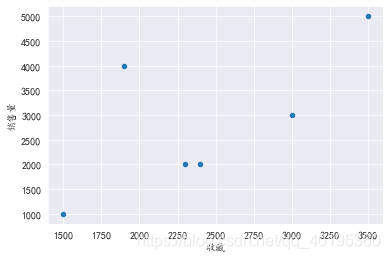
4.1 普通散点图
line.plot.scatter(x='收藏',y='销售量')
4.2 气泡图
test_dict1 = {'销售量':[1000,2000,5000,2000,4000,3000],'收藏':[1500,2300,3500,2400,1900,3000],'评价数':[20,400,30,50,500,80]}
line1 = pd.DataFrame(test_dict1,index=['一月','二月','三月','四月','五月','六月'])
line1.plot.scatter(x='收藏',y='销售量',s=line1['评价数'])

- 注 气泡(散点)作为大小值(三维关系)。
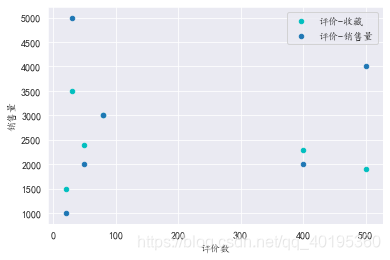
4.3 多组散点图
ax=line1.plot.scatter(x='评价数',y='收藏',label='评价-收藏',color='c')
line1.plot.scatter(x='评价数',y='销售量',label='评价-销售量',ax=ax)
5 面积图
面积图又称区域图,强调数量随时间而变化的程度,也可用于引起人们对总值趋势的注意。堆积面积图还可以显示部分与整体的关系。折线图和面积图都可以用来帮助我们对趋势进行分析,当数据集有合计关系或者你想要展示局部与整体关系的时候,使用面积图为更好的选择。
1、比折线图看起来更加美观。
2、能够突出每个系别所占据的面积,把握整体趋势。
3、不仅可以表示数量的多少,而且可以反映同一事物在不同时间里的发展变化的情况。
4、可以纵向与其他系别进行比较,能够直观地反映出差异。
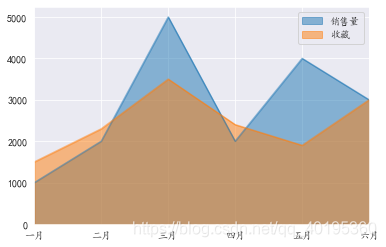
非堆积效果图
line.plot.area(stacked=False)
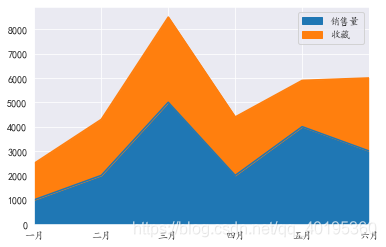
生成堆积图
line.plot.area()
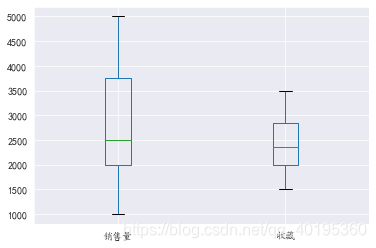
6 箱线图
“箱线图作为描述统计的工具之一,其功能有独特之处,主要有以下几点:
1. 识别数据异常值。
2. 查看偏态和尾重。
3. 了解数据的形状。
DataFrame.boxplot(self, column=None, by=None, ax=None, fontsize=None, rot=0, grid=True, figsize=None, layout=None, return_type=None, **kwds)
画图
line.boxplot()
#其实与`line.plot.box()`等价
7 直方图
直方图是数值数据分布的精确图形表示,这是一个连续变量(定量变量)的概率分布的估计。
作用:
1.整理统计数据,了解统计数据的分布特征,即数据分布的集中或离散状况,从中掌握质量能力状态。
2.观察分析生产过程质量是否处于正常、稳定和受控状态以及质量水平是否保持在公差允许的范围内。
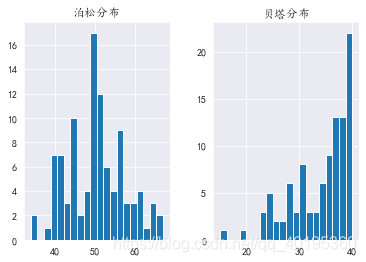
DataFrame.hist(data, column=None, by=None, grid=True, xlabelsize=None, xrot=None, ylabelsize=None, yrot=None, ax=None, sharex=False, sharey=False, figsize=None, layout=None, bins=10, **kwds)
test_dict2 = {'泊松分布':np.random.poisson(50,100),'贝塔分布':np.random.beta(5,1,100)*40}
line2 = pd.DataFrame(test_dict2)
line2
line2.hist(figsize=(10,5),bins=20)

8 核密度曲线
核密度估计(kernel density estimation,KDE)是根据已知的一列数据(x1,x2,…xn)估计其密度函数的过程,即寻找这些数的概率分布曲线。
画频率直方图就是一种密度估计的方法,这里的“密度”(density)可以感性得理解为一个区间(直方图的组距)内数据数量的多少,右图即为这6个数据的密度曲线(这里简称为密度图),它是左图的外轮廓化,数据量越多,直方图的顶点也越接近一条线。
直方图和密度图都是一组数据在坐标轴上“疏密程度”的可视化,只不过直方图用条形图显示,而密度图使用拟合后的(平滑)的曲线显示,“峰”越高,表示此处数据越“密集”。“密度”越高,如下图。
line2.hist(bins=20)
line2.plot.kde(subplots=True)
line2.plot.density(subplots=True)

9 hexbin(六边形图)
可以使用DataFrame.plot.hexbin(self, x, y, C=None, reduce_C_function=None, gridsize=None, **kwargs)创建六边形图形图。
如果您的数据太密集,可以单独绘制每个点,六角形箱体图可以是散点图的有用替代方法。
说实话,我也不知道这个图是用来干啥的,参考资料文献也比较少,如果哪位大神懂,还望不吝赐教。
