今天说一下LinkedHashMap的主要点,因为有同学不太清楚它和HashMap的区别。今天大概总结一下,也是方便自己进行学习。

写在前面
LinkedHashMap的内部维护了一个双向链表。可以按照元素的插入顺序进行访问,也可以按照元素的访问顺序进行访问。要注意一点的是LinkedHashMap是可以实现LRU缓存策略的,前提是你需要将LinkedHashMap中的accessorder属性设置为true。
因此你基本可以认为LinkedHashMap是LinkedList和HashMap的一个组合。
LinkedHashMap简介
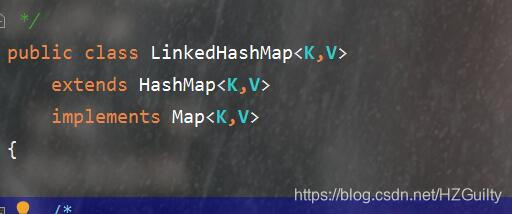
LinkedHashMap继承自HashMap,拥有HashMap的特性。除此之外LinkedHashMap内部维护了一个链表,保证访问的顺序。
LinkedHashMap的内部属性
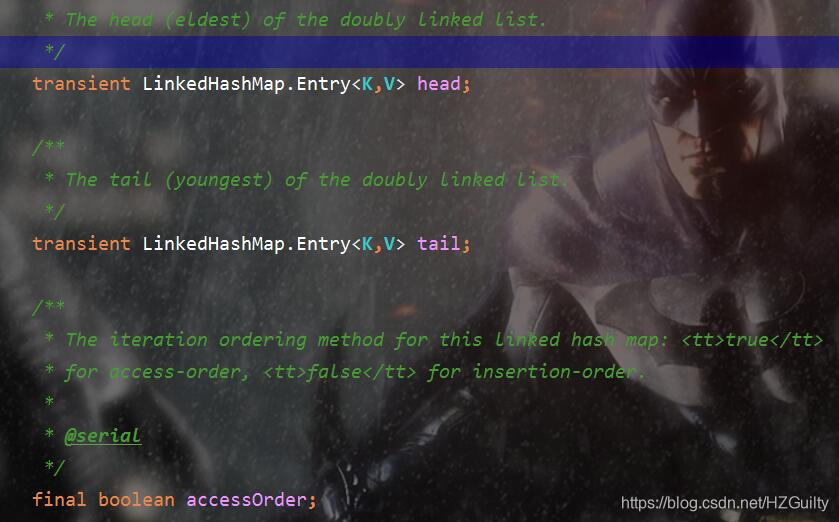
- LinkedHashMap.Entry<K,V> head,表示双向链表的头结点。
- LinkedHashMap.Entry<K,V> tail表示双向链表的尾结点。
- boolean accessOrder表示是否按照顺序访问,默认是false。false的时候是按照插入顺序进行访问,true的时候是按照访问顺序进行访问。
- 用于双向链表存储元素。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
LinkedHashMap的构造方法
LinkedHashMap(int initialCapacity, float loadFactor)
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
LinkedHashMap(int initialCapacity)
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
LinkedHashMap()
public LinkedHashMap() {
super();
accessOrder = false;
}
LinkedHashMap(Map<? extends K, ? extends V> m)
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder)
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
要注意的一点前四个构造方法默认accessorder为false,只有第五个构造方法可以传入accessorder。
LinkedHashMap的主要操作
void afterNodeRemoval(Node<K,V> e)
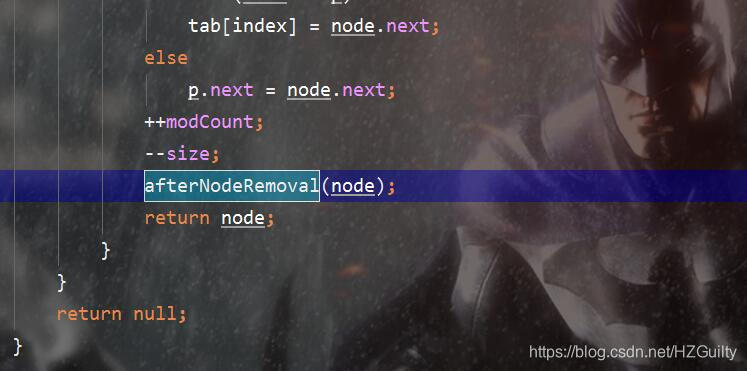
在removeNode方法中被调用,目的是将节点从链表中删除。
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
void afterNodeInsertion(boolean evict)
在HashMap中的putVal()方法中被调用。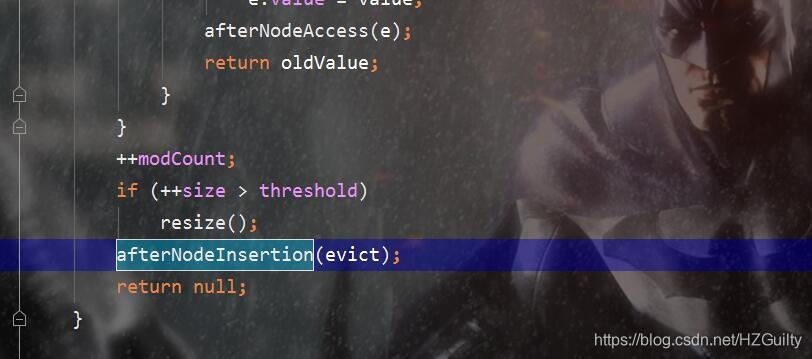
首先会进行判断,如果evict为true,且头结点不为空,且确定要移除最老的元素。调用removeNode方法将节点从HashMap中移除掉,removeNode方法最后会调用afterNodeRemoval(node)方法用于修改双向链表。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
void afterNodeAccess(Node<K,V> e)
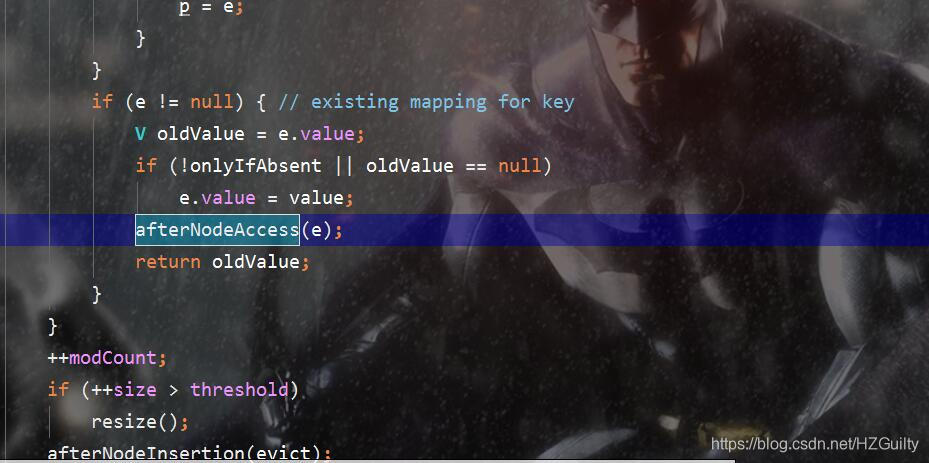
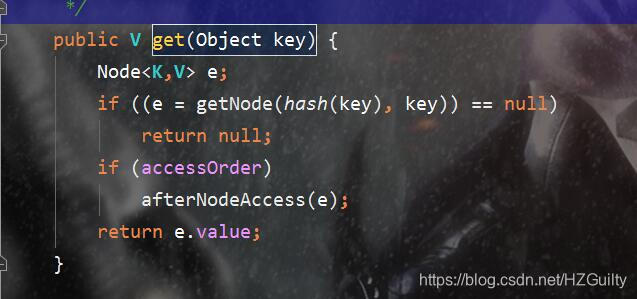
在put方法和get方法中被调用。如果accessorder为true,afterNodeAccess方法会把访问到的节点移动到链表的尾部。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
LinkedHashMap总结
- LinkedHashMap等同于HashMap加LinkedList,每次添加删除元素,不仅需要维护hashmap还要维护一个双向链表。
- accessorder为false时,按照插入元素的顺序去访问元素。
- accessorder为true时,按照访问的元素的顺序去遍历元素。
- LinkedHashMap默认是不会淘汰元素的,如果需要淘汰,则需要重写removeEldestEntry()方法。
- LinkedHashMap可以实现LRU策略,只需要将accessorder设置为true即可。
