java.lang.OutOfMemoryError: Unable to acquire 65536 bytes of memory, got 0
at org.apache.spark.memory.MemoryConsumer.allocateArray(MemoryConsumer.java:98)
at org.apache.spark.util.collection.unsafe.sort.UnsafeInMemorySorter.<init>(UnsafeInMemorySorter.java:126)
at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.<init>(UnsafeExternalSorter.java:153)
at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.create(UnsafeExternalSorter.java:120)
at org.apache.spark.sql.execution.UnsafeExternalRowSorter.<init>(UnsafeExternalRowSorter.java:82)
at org.apache.spark.sql.execution.SortExec.createSorter(SortExec.scala:87)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.init(Unknown Source)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8.apply(WholeStageCodegenExec.scala:392)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8.apply(WholeStageCodegenExec.scala:389)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$26.apply(RDD.scala:844)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$26.apply(RDD.scala:844)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.ZippedPartitionsRDD2.compute(ZippedPartitionsRDD.scala:89)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.CoalescedRDD$$anonfun$compute$1.apply(CoalescedRDD.scala:100)
at org.apache.spark.rdd.CoalescedRDD$$anonfun$compute$1.apply(CoalescedRDD.scala:99)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:434)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:440)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$SingleDirectoryWriteTask.execute(FileFormatWriter.scala:315)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:258)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:256)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1375)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:261)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1$$anonfun$apply$mcV$sp$1.apply(FileFormatWriter.scala:191)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1$$anonfun$apply$mcV$sp$1.apply(FileFormatWriter.scala:190)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
**
解决方案
**
将代码中的 coalesce 改为 reparation即可。
reparation和coalesce的用法和区别:
先看一下下面的代码吧:
package test
import org.apache.spark.{SparkConf, SparkContext}
object RddTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("localTest").setMaster("local[2]")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List("hello","jason","jim","vin"),5)
println(rdd1.partitions.length) //输出5
val rdd3 = rdd1.repartition(10)
println(rdd3.partitions.length) //输出10
val rdd4 = rdd1.coalesce(10,true)
println(rdd4.partitions.length) //输出10
}
}
从上面的demo中可以看到coalesce和repartition都是用来对RDD的分区重新划分的,下面我们来看一下这两个方法的源码.如下:
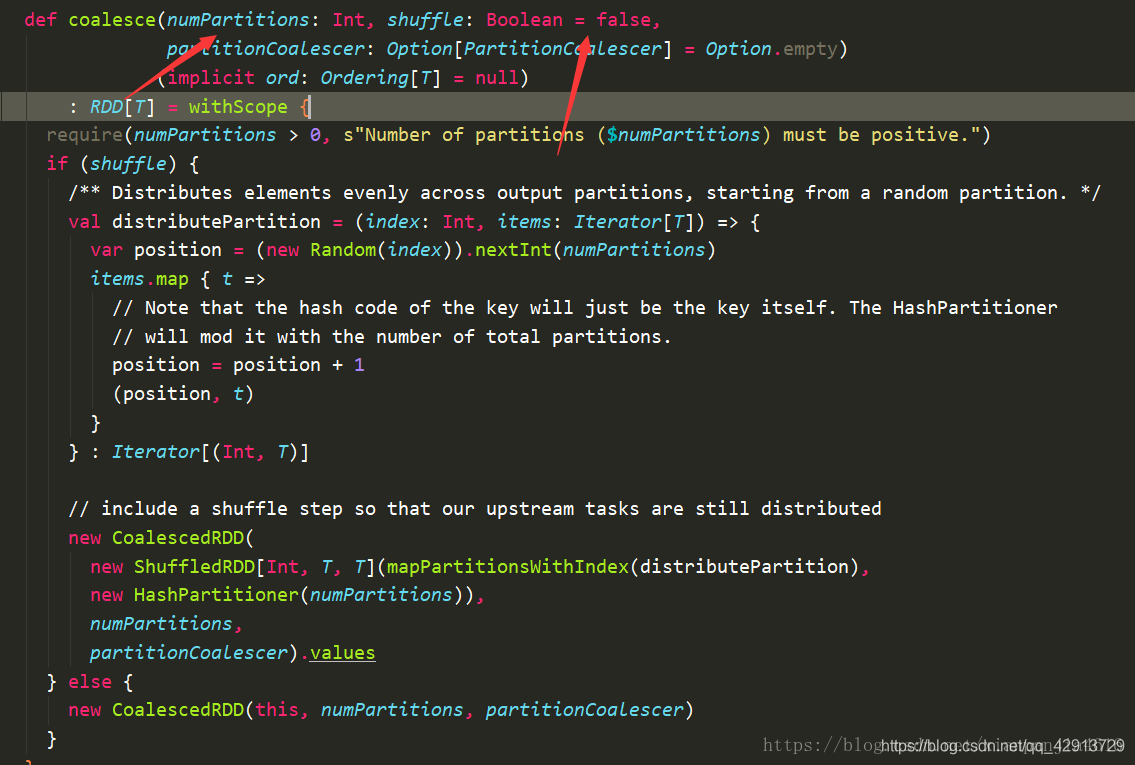

从源码中可以看出repartition方法其实就是调用了coalesce方法,shuffle为true的情况(默认shuffle是fasle).现在假设RDD有X个分区,需要重新划分成Y个分区.
1.如果x<y,说明x个分区里有数据分布不均匀的情况,利用HashPartitioner把x个分区重新划分成了y个分区,此时,需要把shuffle设置成true才行,因为如果设置成false,不会进行shuffle操作,此时父RDD和子RDD之间是窄依赖,这时并不会增加RDD的分区.
2.如果x>y,需要先把x分区中的某些个分区合并成一个新的分区,然后最终合并成y个分区,此时,需要把coalesce方法的shuffle设置成false.
总结:如果想要增加分区的时候,可以用repartition或者coalesce,true都行,但是一定要有shuffle操作,分区数量才会增加,为了让该函数并行执行,通常把shuffle的值设置成true。
